Command Palette
Search for a command to run...
QwenLong-L1:面向长上下文大推理模型的强化学习方法
QwenLong-L1:面向长上下文大推理模型的强化学习方法
摘要
近期的大规模推理模型(Large Reasoning Models, LRMs)通过强化学习(Reinforcement Learning, RL)展现出强大的推理能力。然而,这些性能提升主要集中在短上下文推理任务中。相比之下,如何通过强化学习有效拓展LRMs以处理和推理长上下文输入,仍是当前亟待解决的关键挑战。为弥合这一差距,我们首先形式化了长上下文推理强化学习的范式,并识别出其中存在的核心问题:训练效率低下与优化过程不稳定。针对上述挑战,我们提出QwenLong-L1框架,通过渐进式上下文扩展的方式,将原本面向短上下文设计的LRMs适配至长上下文场景。具体而言,该框架包含三个关键阶段:首先采用预热式监督微调(Supervised Fine-Tuning, SFT)建立稳健的初始策略;随后引入课程引导的分阶段强化学习机制,以稳定策略演进过程;最后结合一种难度感知的回溯采样策略,激励策略在探索中主动应对更具挑战性的任务。在七个长上下文文档问答基准上的实验结果表明,QwenLong-L1-32B在性能上超越了包括OpenAI-o3-mini和Qwen3-235B-A22B在内的主流旗舰LRMs,达到与Claude-3.7-Sonnet-Thinking相当的水平,展现出当前先进LRMs中的领先性能。本研究推动了实用化长上下文LRMs的发展,使其能够在信息密集型环境中实现稳健、高效的推理能力。
一句话总结
通义实验室的作者提出了 QWENLONG-L1,一种通过渐进式上下文扩展实现大模型长上下文推理的新框架,结合了预热监督微调、课程引导的分阶段强化学习以及难度感知的回溯采样,克服了训练效率低下和不稳定的难题——在七个长上下文问答基准上达到最先进性能,与 Claude-3.7-Sonnet-Thinking 相媲美,并优于 OpenAI-o3-mini 和 Qwen3-235B-A22B 等模型。
主要贡献
- 尽管短上下文强化学习(RL)取得了进展,大推理模型(LRMs)在长上下文推理方面仍面临关键挑战,主要由于输出熵降低和长序列方差增加导致的训练效率低下和优化不稳定。
- 所提出的 QWENLONG-L1 框架通过渐进式上下文扩展解决这些问题,结合预热监督微调阶段、课程引导的分阶段强化学习以及难度感知的回溯采样,以稳定策略演化并增强探索能力。
- 在七个长上下文文档问答基准上,QWENLONG-L1-32B 达到最先进性能,优于 OpenAI-o3-mini 和 Qwen3-235B-A22B 等模型,并与 Claude-3.7-Sonnet-Thinking 性能相当。
引言
大推理模型(LRMs)通过强化学习(RL)在短上下文推理任务中取得了显著进展,实现了链式思维等复杂问题求解行为。然而,将这些模型扩展到长上下文场景——即必须基于大量信息密集型输入进行推理——仍面临重大挑战,原因在于长序列导致的输出熵降低和方差增加,造成训练效率低下和优化不稳定。先前方法缺乏针对长上下文强化学习的结构化框架,限制了其可扩展性。作者提出了 QWENLONG-L1,首个专为长上下文推理设计的强化学习框架,通过渐进式上下文扩展实现从短上下文到长上下文的稳定适应。该框架结合预热监督微调阶段、课程引导的分阶段强化学习以及难度感知的回溯采样策略,以提升探索能力和训练稳定性。框架采用混合奖励函数和组相对强化学习算法,同时提升精确率与召回率。在七个长上下文文档问答基准上的实验表明,QWENLONG-L1-32B 超越了 OpenAI-o3-mini 和 Qwen3-235B-A22B 等领先模型,性能与 Claude-3.7-Sonnet-Thinking 相当,展示了长上下文推理在实际应用中的重大进展。
数据集
- 数据集包含两个主要部分:强化学习(RL)数据集和监督微调(SFT)数据集,旨在支持语言模型的长上下文推理。
- RL 数据集 DOCQA-RL-1.6K 包含 1,600 个文档-问题-答案对,涵盖三个推理领域:
- 数学推理:600 个问题,源自 DocMath,涉及金融报告等长篇专业文档中的数值推理。
- 逻辑推理:600 个合成多选题,使用 DeepSeek-R1 生成,基于法律、金融、保险和生产领域的实际文档。
- 多跳推理:400 个样本——200 个来自 MultiHopRAG,200 个来自 Musique——聚焦跨文档推理与信息整合。
- SFT 数据集包含 5,300 个高质量的问答-文档三元组,由 DeepSeek-R1 提炼而来,经过精心筛选以保证质量、复杂性和多样性。文档经过过滤,确保长度适中且上下文精确。
- 作者使用 SFT 数据集作为模型在强化学习优化前的强初始化,而 RL 数据集则以混合比例使用,以平衡三种推理领域。
- 所有数据均使用 Qwen 分词器处理以测量序列长度;文档保留原始形式,仅进行最小程度预处理以保持上下文完整性。
- 未进行显式裁剪,但构建了文档来源、推理类型和章节引用等元数据,以支持训练与评估。
- 通过逐步推理并引用具体文档章节(如 Note 7 或 Note 14)展示模型的定位与验证能力,体现其在长文本中获取信息的行为。
方法
作者采用强化学习(RL)框架训练语言模型完成长上下文推理任务,其中策略模型需基于长上下文 c 生成准确的推理链和问题 x 的答案。整体训练过程围绕渐进式上下文扩展策略展开,将优化过程划分为多个阶段,以实现从短上下文到长上下文的稳定训练。在每个阶段,策略模型 πθ 在特定上下文长度范围内的输入上进行训练,逐步将输入长度从初始值 L1 增加至最大值 LK。这种课程引导的方法确保模型以受控方式逐步掌握更复杂的长上下文场景。

如图所示,该框架从一个策略模型开始,输入为问题 x 和上下文 c,上下文可为短(cshort)或长(clong),具体取决于当前训练阶段。策略模型为给定输入生成一组 G 个输出 {yi}i=1G。这些输出随后由混合奖励机制评估,该机制结合基于规则的验证与 LLM-as-a-judge 组件。基于规则的验证通过精确字符串匹配确保严格正确性,而 LLM-as-a-judge 则评估生成答案与标准答案之间的语义等价性,从而缓解严格字符串匹配带来的假阴性问题。两个组件的奖励通过最大值选择合并,形成每个输出的最终奖励 ri。
随后,利用奖励计算策略更新的优势值。框架采用组相对强化学习算法(如 GRPO 和 DAPO),无需独立的价值网络,避免了因注意力机制的二次复杂度导致的长上下文输入计算开销。在 GRPO 中,每个 token 的优势通过归一化组级奖励计算;DAPO 引入额外技术以提升稳定性,包括动态采样策略(过滤奖励方差为零的样本)、基于 token 的损失函数(缓解长度偏差)以及过长奖励调整(惩罚过长输出)。策略模型使用所选 RL 算法的裁剪替代目标进行更新,更新后的策略作为下一轮迭代的新策略。
为进一步稳定训练过程,作者在强化学习训练前引入预热监督微调(SFT)阶段。该阶段通过教师模型提炼的高质量示范初始化策略模型,使模型在进入更不稳定的强化学习优化前,具备基本的上下文理解与推理链生成能力。SFT 模型作为强化学习训练的初始策略,提供稳健的初始参数。此外,采用难度感知的回溯采样机制,根据生成输出的逆平均奖励计算难度得分,从前期阶段采样更具挑战性的实例,确保模型在整个训练过程中持续从最难样本中学习。
实验
- 在七个长上下文文档问答(DocQA)基准上进行评估,包括多跳推理任务(2WikiMultihopQA、HotpotQA、Musique、NarrativeQA、Qasper、Frames)和数学推理(DocMath),使用 DeepSeek-V3 作为裁判模型,温度设为 0.0。
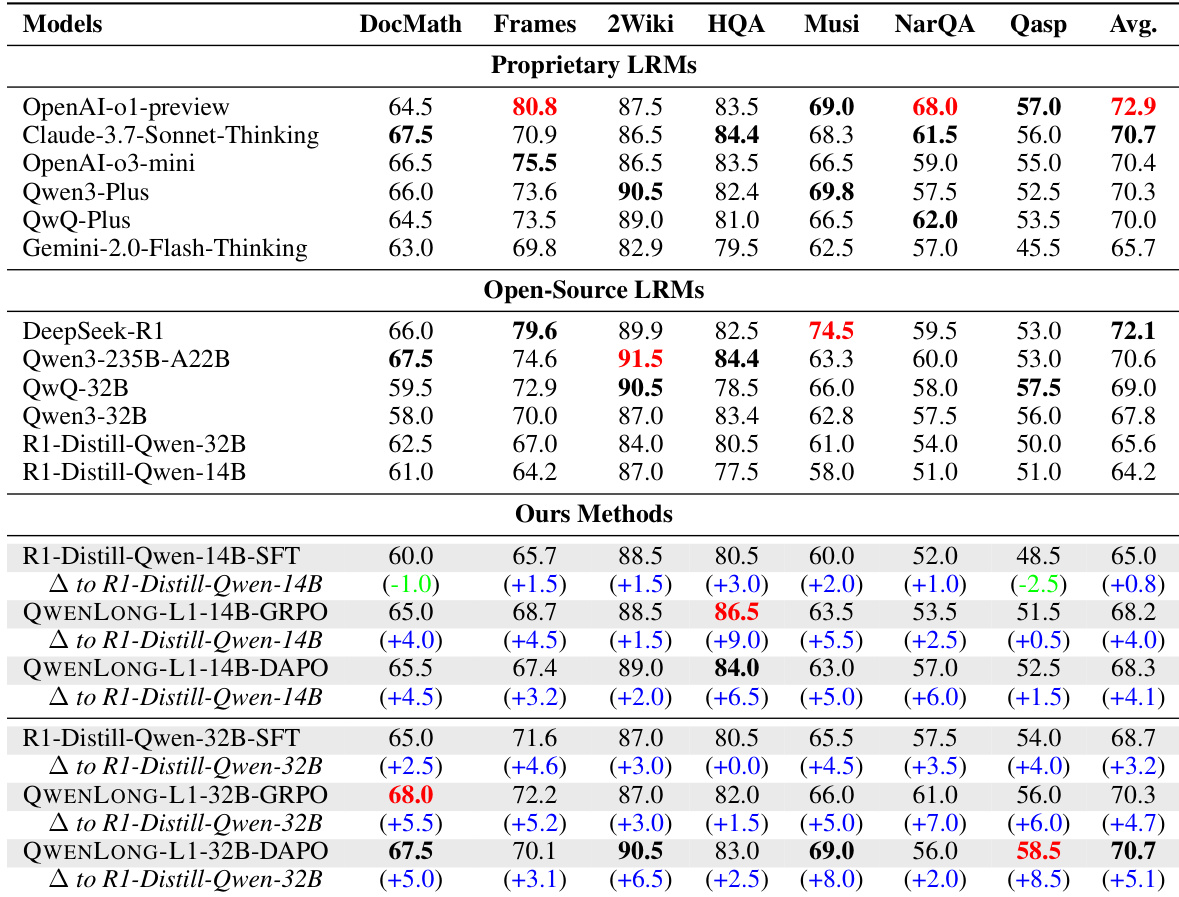
- QWENLONG-L1-14B 在各基准上平均得分为 68.3,超越 Gemini-2.0-Flash-Thinking、R1-Distill-Qwen-32B、Qwen3-32B,并与 QwQ-32B 相当。
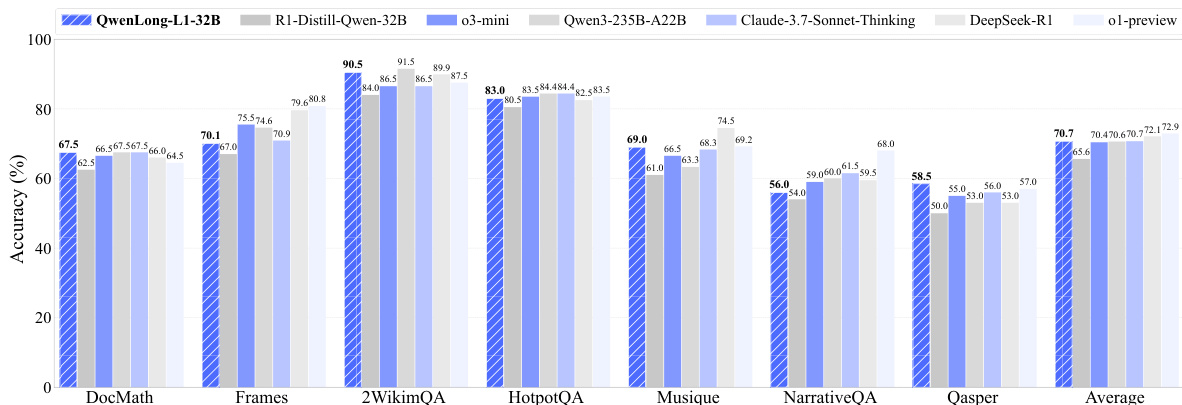
- QWENLONG-L1-32B 平均得分为 70.7,超过 QwQ-Plus、Qwen3-Plus、Qwen3-235B-A22B、OpenAI-o3-mini,并与 Claude-3.7-Sonnet-Thinking 相当。
- 强化学习集成带来显著提升:QWENLONG-L1-14B 在 DAPO 和 GRPO 下分别比基线模型提升 4.1 和 4.0 分,远超 SFT 的 0.4 分提升。
- 测试时使用 16 个样本的缩放策略提升了 Pass@K 性能,QWENLONG-L1-14B 达到 73.7 Pass@2,优于 DeepSeek-R1(72.1)和 OpenAI-o1-preview(72.9)。
- 消融实验验证了预热 SFT、课程引导的分阶段 RL 以及难度感知回溯采样在提升稳定性和性能方面的有效性。
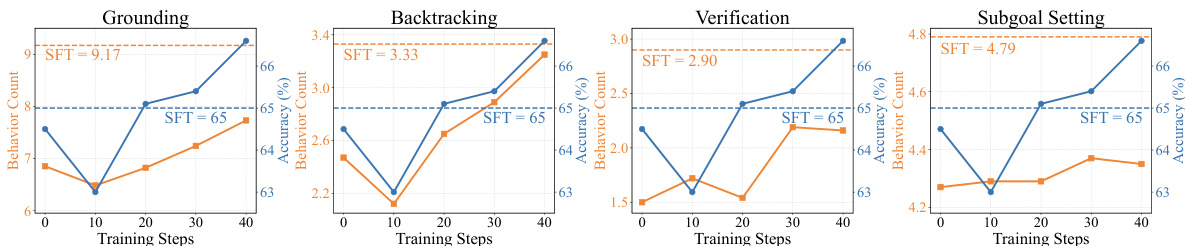
- 强化学习训练显著增强了核心推理行为(定位、子目标设定、回溯、验证),而仅使用 SFT 即使增加行为频率也无法提升性能。
作者使用七种多样化的长上下文文档问答基准评估 QWENLONG-L1,数据集统计显示各任务在样本数量、平均长度和最大长度方面存在显著差异。测试数据集包括 DocMath、Frames、2Wiki、HQA、Musi、NarQA 和 Qasp,各自具有独特特征;而监督微调与强化学习的训练数据集在规模和上下文长度上也存在显著差异。

作者使用七种长上下文文档问答基准评估 QWENLONG-L1,与当前最先进的专有及开源大推理模型进行对比。结果表明,QWENLONG-L1 表现优异,QWENLONG-L1-14B 平均得分为 68.3,QWENLONG-L1-32B 平均得分为 70.7,优于 Gemini-2.0-Flash-Thinking 和 Qwen3-Plus 等多个领先模型。
作者使用七种长上下文文档问答基准评估 QWENLONG-L1,结果显示 QWENLONG-L1-32B 达到 70.7% 的最高平均准确率,超越多个最先进的专有及开源模型。该模型在各单项基准上表现强劲,尤其在 2WikiMultihopQA 和 HotpotQA 上分别取得 90.5% 和 83.0% 的高分。
作者利用提供的图表分析训练过程中四种核心推理行为——定位、回溯、验证和子目标设定——的演化情况。结果显示,尽管监督微调(SFT)提高了这些行为的频率,但并未转化为性能提升,SFT 模型的准确率仍处于较低水平。相比之下,强化学习(RL)训练使这四种行为逐步增加,且与准确率的显著提升密切相关,表明 RL 有效优化了模型的推理模式。