Command Palette
Search for a command to run...
像素推理器:基于好奇心驱动的强化学习激励像素空间推理
像素推理器:基于好奇心驱动的强化学习激励像素空间推理
Su Alex Wang Haozhe Ren Weimin Lin Fangzhen Chen Wenhu
摘要
思维链推理(Chain-of-thought reasoning)已在多个领域显著提升了大型语言模型(Large Language Models, LLMs)的性能。然而,这种推理过程目前仍局限于文本空间,限制了其在视觉密集型任务中的有效性。为解决这一局限,我们提出在像素空间(pixel-space)中进行推理的新范式。在此新框架下,视觉-语言模型(Vision-Language Models, VLMs)被赋予一系列视觉推理操作,如“缩放”(zoom-in)和“选帧”(select-frame)。这些操作使VLM能够直接观察、询问并从视觉证据中进行推断,从而显著提升视觉任务中的推理保真度。在VLM中培养像素空间推理能力面临诸多挑战,包括模型初始阶段在不同模态间能力分布不均,以及对新引入的像素空间操作缺乏主动采用意愿。为此,我们提出一种两阶段训练方法:第一阶段通过在合成推理轨迹(synthesized reasoning traces)上进行指令微调(instruction tuning),使模型熟悉新的视觉操作;第二阶段则采用强化学习(Reinforcement Learning, RL)方法,结合好奇心驱动的奖励机制,平衡模型在像素空间推理与文本空间推理之间的探索行为。借助这些视觉操作,VLM能够与复杂视觉输入(如信息丰富的图像或视频)进行交互,主动获取所需信息。实验结果表明,该方法在多种视觉推理基准测试中均显著提升了VLM的性能。我们提出的7B参数规模模型在V*基准上达到84%的准确率,在TallyQA-Complex上达到74%,在InfographicsVQA上达到84%,创下当前开源模型在这些任务上的最高纪录。这些成果充分体现了像素空间推理的重要性,也验证了所提出框架的有效性。
一句话总结
滑铁卢大学、香港科技大学、中国科学技术大学和Vector研究所的作者提出Pixel-Reasoner,一个7B参数的视觉-语言模型,通过缩放和选帧等视觉操作引入像素空间推理,实现对视觉输入的直接交互;通过结合指令微调与好奇心驱动的强化学习的两阶段训练方法,该模型在视觉推理基准上达到开源模型的最先进性能,展现出在复杂视觉任务中更高的保真度。
主要贡献
- 本工作为视觉-语言模型(VLMs)引入了像素空间推理,通过缩放、选帧等操作实现对视觉输入的直接交互,解决了纯文本思维链推理在视觉密集型任务中的局限性。
- 作者提出一种两阶段训练框架,结合合成推理轨迹的指令微调与好奇心驱动的强化学习,以克服像素空间操作采纳的挑战,并平衡视觉与文本推理之间的探索。
- 所得7B模型Pixel-Reasoner在多个视觉推理基准上达到最先进性能,包括V* bench上84%、TallyQA-Complex上74%、InfographicsVQA上84%,验证了所提框架的有效性。
引言
作者针对当前视觉-语言模型(VLMs)的一个关键局限性展开研究:这些模型在复杂任务中完全依赖文本推理步骤,缺乏对视觉输入的直接交互能力。这限制了其捕捉细粒度视觉细节(如小物体、细微的空间关系或图像与视频中的嵌入文本)的能力。为克服这一问题,作者提出Pixel Reasoner框架,使VLMs能够通过缩放和帧选择等视觉操作执行像素空间推理。该方法结合预热指令微调与好奇心驱动的强化学习,激励有意义的视觉探索,使模型能够迭代地深化对图像与视频的理解。这标志着从纯文本推理的重大转变,实现了更深入、更准确的视觉分析,同时保持与现有VLM架构的兼容性。
数据集
-
数据集由三个种子数据集构成:SA1B、FineWeb和STARQA,因其高视觉复杂性及明确标注而被选中,支持细粒度视觉分析。SA1B提供高分辨率自然场景与详细分割掩码;FineWeb提供网页截图与问答对,并对答案区域进行精确边界框标注;STARQA提供视频数据,包含问答对与相关视觉内容的标注时间窗口。
-
每个数据集贡献不同模态:SA1B支持图像级细粒度推理,FineWeb支持空间精确的视觉查询,STARQA支持视频序列的时间推理。作者使用GPT-4o提取或生成需要定位特定视觉线索的细粒度视觉-语言查询,尤其针对SA1B,查询基于识别出的图像细节进行合成。
-
专家轨迹采用基于模板的方法合成,以确保视觉操作的合理整合。模板将推理结构化为:(1) 对完整输入进行全局分析,(2) 执行视觉操作(裁剪或选帧),(3) 对生成的视觉线索进行详细分析,(4) 给出最终答案。这确保了视觉操作的必要性,避免被跳过。
-
生成两种轨迹类型:单次通过轨迹,直接使用正确视觉线索;错误诱导自纠正轨迹,在正确线索前插入错误或误导性视觉操作(如无关帧、过大的边界框),以模拟错误恢复过程。
-
自纠正轨迹类型包括:Recrop once(一个错误边界框)、Recrop twice(两个错误边界框)、Further zoom-in(包含正确线索的过大边界框)、Reselect(错误帧选择)。其比例分布详见表2。
-
视觉操作仅限两种类型:CropImage,接收二维边界框与目标图像索引以缩放至特定区域;SelectFrames,从16帧视频序列中选择最多8帧。
-
训练过程中,作者采用单次通过、自纠正与纯文本推理轨迹的混合,使模型学会何时应用像素空间推理。在自纠正轨迹中,对表示错误视觉操作的token应用损失掩码,防止模型学习错误行为。
-
数据处理流程如图8所示,将完整高分辨率图像或视频与参考视觉线索输入GPT-4o,生成全局与局部文本分析,再与视觉操作结合形成完整轨迹。
-
数据集已公开,包含完整文档,包括数据模式、使用说明与许可证信息,确保可复现性并符合原始数据集条款。
方法
作者提出Pixel-Reasoner,一种旨在使视觉-语言模型(VLMs)通过引入缩放、选帧等视觉操作,在像素空间中直接进行推理的框架。该方法与传统文本推理形成对比,后者需将视觉信息先转化为文本再进行推理。该框架的核心是迭代推理过程,模型生成的推理步骤可为文本思考或视觉操作。视觉操作步骤涉及调用预定义函数(如zoom-in或select-frame),其执行结果随后被纳入推理链。这一过程使模型能够主动检查、质询并从视觉证据中推断,从而提升视觉密集型任务的推理保真度。
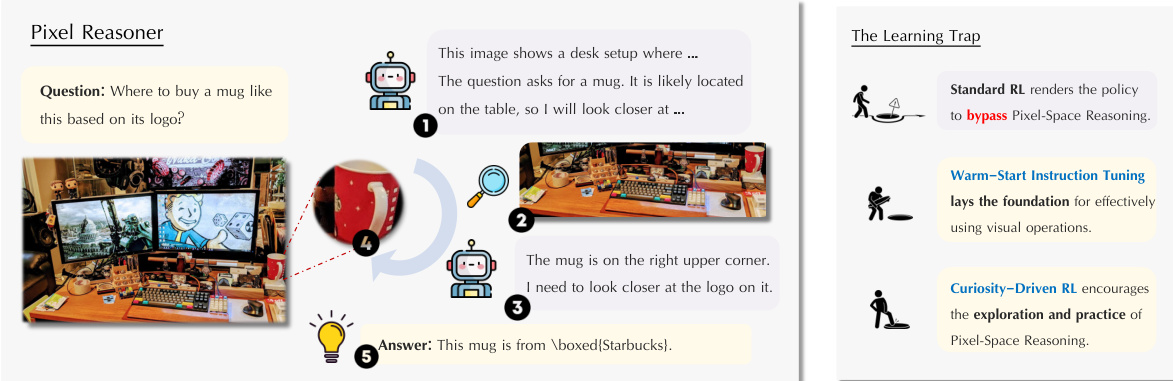
该框架基于两阶段训练方法,以应对培养像素空间推理的挑战。第一阶段为预热指令微调,旨在使模型熟悉新型视觉操作,同时保留其自纠正能力。该阶段合成7,500条推理轨迹,引导模型掌握视觉操作并建立基础理解。指令微调阶段对建立视觉操作的基准能力至关重要,为后续强化学习阶段奠定基础。

第二阶段采用好奇心驱动的强化学习(RL)方法,以平衡像素空间与文本推理之间的探索。该阶段旨在克服因模型在文本与视觉推理能力初始不平衡而产生的“学习陷阱”。该陷阱表现为:模型初期在视觉操作上表现不佳,导致负面反馈,且可绕过本应使用视觉操作的查询。为打破此循环,作者提出一种好奇心驱动的奖励机制,内在奖励尝试执行像素空间操作的行为。该机制被形式化为约束优化问题,目标是在最大化预期正确性的同时,确保像素空间推理的最低频率,并限制每响应中的视觉操作数量。修改后的奖励函数在整体像素空间推理率低于阈值时,对使用像素空间推理的响应给予好奇心奖励;对超过最大视觉操作次数的响应施加惩罚。
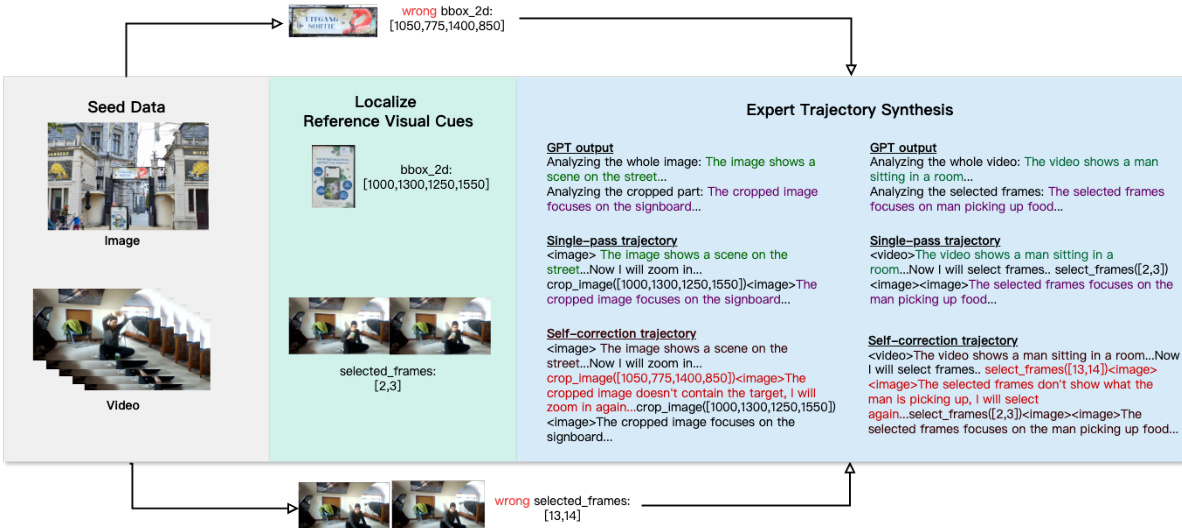
训练流程始于种子数据,用于生成参考视觉线索。这些线索随后用于专家轨迹合成,其中GPT-4o生成包含视觉操作的推理轨迹。合成过程包括单次通过轨迹与自纠正轨迹,旨在提供多样化的训练样本。最终模型Pixel-Reasoner基于Qwen2.5-VL-7B构建,并使用合成数据与好奇心驱动的RL方法进行训练。该框架使模型能够通过主动执行视觉操作,从信息丰富的图像或视频中获取必要信息,从而与复杂视觉输入进行交互。
实验
- Pixel-Reasoner在四个多模态基准上取得最先进结果:V*(84.3)、TallyQA、InfographicVQA与MVBench,优于更大规模的开源模型(如27B Gemma3)与专有模型(如Gemini-2.5-Pro,在V*上领先5.1分)。
- 模型在7,500条轨迹(含5,500个像素空间推理样本)上训练,表明好奇心驱动奖励的强化学习对培养像素空间推理至关重要,可克服监督微调中观察到的“学习陷阱”。
- 消融实验确认:预热指令微调与自纠正、好奇心激励是关键因素;缺乏这些组件的模型默认采用文本空间推理,平均性能下降2.5分。
- Pixel-Reasoner在V*上78.5%的响应触发像素空间推理,MVBench上66.9%,其他基准超57%,且错误率低,表明视觉操作使用有效且可靠。
- 在4×8 A800(80G)GPU上使用GRPO训练20小时,结合选择性样本重放与融合好奇心奖励与效率惩罚的奖励机制,实现稳定且高性能的训练动态。
作者使用表格详细说明数据集中轨迹类型的分布:图像任务中,30%为单次通过,20%涉及一次Recrop,20%涉及两次Recrop,30%需进一步缩放;视频任务中,90%为单次通过,10%涉及Reselect。

结果表明,Pixel-Reasoner在所有四个基准上均达到最高开源性能,超越更大模型与专用工具系统。其成功归因于有效的指令微调与好奇心驱动奖励机制,该机制通过主动培养像素空间推理克服了“学习陷阱”。

结果表明,Pixel-Reasoner实现了高比例的像素空间推理,其RaPR在训练20,000步后稳定高于0.7,而无好奇心奖励的基线模型迅速下降至接近零。这表明好奇心驱动奖励机制对训练过程中持续培养像素空间推理至关重要。

作者使用一组全面的基准评估Pixel-Reasoner——一个基于强化学习与好奇心驱动奖励机制训练的7B参数模型。结果表明,Pixel-Reasoner在所有四个基准上均达到最先进性能,超越更大规模的开源模型与专用工具模型,在V* Bench(84.3)与InfographicVQA(84.0)上取得最高分。
