Command Palette
Search for a command to run...
MMaDA:多模态大扩散语言模型
MMaDA:多模态大扩散语言模型
摘要
我们提出MMaDA,一种新型的多模态扩散基础模型,旨在实现跨文本推理、多模态理解以及文本到图像生成等多个领域的卓越性能。该方法具有三项关键创新:(i)MMaDA采用统一的扩散架构,具备共享的概率建模机制与模态无关的设计,无需依赖特定模态的组件。这一架构确保了不同类型数据之间的无缝集成与高效处理。(ii)我们引入了一种混合长链思维(Chain-of-Thought, CoT)微调策略,统一了跨模态的CoT表达格式。通过对齐文本与视觉领域间的推理过程,该策略为最终强化学习(Reinforcement Learning, RL)阶段提供了良好的冷启动条件,显著提升了模型从初始阶段即应对复杂任务的能力。(iii)我们提出了UniGRPO——一种专为扩散基础模型设计的统一策略梯度强化学习算法。该算法结合多样化的奖励建模方式,实现了推理与生成任务在后训练阶段的统一优化,保障了性能的持续提升。实验结果表明,MMaDA-8B作为统一的多模态基础模型,展现出强大的泛化能力:在文本推理任务中超越了LLaMA-3-7B和Qwen2-7B等强大模型;在多模态理解任务中优于Show-o与SEED-X;在文本到图像生成任务中则显著领先于SDXL与Janus。这些成果充分验证了MMaDA在统一扩散架构中有效弥合预训练与后训练阶段差距的潜力,为未来多模态基础模型的研究与开发提供了一个全面、可扩展的框架。我们已将代码与训练好的模型开源,欢迎访问:https://github.com/Gen-Verse/MMaDA
一句话总结
普林斯顿大学、北京大学、清华大学与字节跳动种子团队提出 MMADA,一种具有模态无关架构和混合长链思维微调的统一多模态扩散基础模型,实现了文本、视觉与生成任务间的无缝集成;其创新的 UniGRPO 强化学习算法通过多样化奖励统一后训练,显著提升了在文本推理、多模态理解及文生图生成方面相对于当前最先进模型的性能。
主要贡献
-
MMADA 引入了一种统一的扩散架构,采用模态无关设计与共享的概率公式,实现了对多种模态——文本、图像等——的无缝集成与处理,无需依赖模态特定组件,从而克服了以往多模态模型在处理离散与连续数据时依赖独立流水线的局限性。
-
该框架采用混合长链思维(CoT)微调策略,标准化了跨模态的推理过程,对齐文本与视觉推理流程,为后续强化学习阶段提供有效的冷启动训练,显著提升了模型从初始阶段应对复杂多步任务的能力。
-
MMADA 集成了 UniGRPO,一种基于统一策略梯度的强化学习算法,结合多样化奖励建模,联合优化推理与生成任务;该方法在文本推理、多模态理解及文生图生成方面均达到最先进水平,超越了 LLaMA-3-7B、Qwen2-7B、Show-o、SEED-X、SDXL 和 Janus 等模型。
引言
作者利用多模态扩散模型构建了一个统一的基础模型,能够在单一架构中处理多样任务——文本推理、多模态理解与文生图生成。以往多模态模型的研究多集中于自回归或模态特定设计,难以在非自回归设置下平衡推理与生成能力。现有统一模型常缺乏有效的后训练策略,限制了其在各类任务中的适应性与性能。为此,作者提出 MMADA,一种具有模态无关设计与共享概率公式的统一扩散架构,消除了对模态特定组件的需求。他们提出混合长链思维微调策略,对齐跨模态推理,实现有效冷启动训练。此外,他们开发了 UniGRPO,一种基于多样化奖励建模的统一强化学习算法,以提升推理与生成能力。这些创新使 MMADA-8B 在三个领域均超越领先模型,展现出强大的泛化能力,并为未来多模态 AI 发展提供了统一框架。
数据集
- MMADA 的数据集由多个专用子集组成,分别服务于不同训练阶段:基础语言与多模态数据、指令微调、推理与强化学习。
- 基础数据包括 RefinedWeb 用于文本生成,以及一系列开源图文数据集用于多模态理解与生成。
- 指令微调数据包含 Alpaca 用于文本指令遵循,以及 LLaVA-1.5 用于视觉指令微调。
- 推理数据结合了文本推理数据集(ReasonFlux、LIMO、s1k、OpenThoughts、AceMath-Instruct)与由 LMM-R1 模型在 GeoQA 和 CLEVR 上生成的多模态推理实例,仅保留正确回答的样本。此外,GPT-4.1 合成跨科学、文化与地标领域的事实性物品描述对,以 CoT 风格轨迹格式呈现,用于增强世界知识感知的图像生成。
- 强化学习数据使用推理阶段原始的数学与逻辑数据集,具体来自 GeoQA 与 CLEVR。
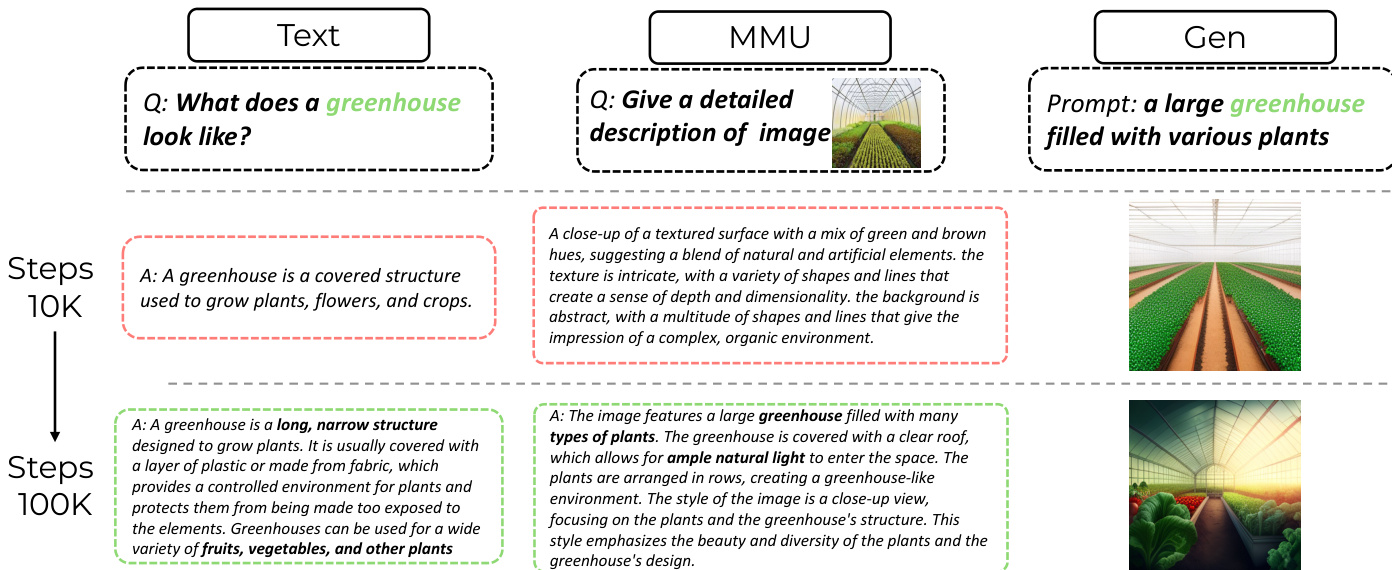
- 模型训练分为三个阶段:第一阶段(20万步)使用基础数据,包含 RefinedWeb 与 ImageNet-1k,后期将 ImageNet 替换为更多样化的图文对;第二阶段(5万步)结合指令微调与推理数据;第三阶段(5万步)使用 UniGRPO 与强化学习数据。
- 训练在 64 块 A100(80GB)GPU 上进行,全局批量大小为 1,280,采用 AdamW 优化器与余弦学习率调度器,初始学习率设为 5e-5。
- 评估方面,图像生成通过 5 万个测试提示使用 CLIP Score、ImageReward、GenEval 与 WISE 进行评估,文本生成则在 MMLU 与 GSM8K 上评估。
- 模型初始化使用 LLaDA-8B-Instruct 权重与 Show-o 的预训练图像分词器。
方法
作者采用统一的扩散架构,在单一概率框架下建模文本与视觉数据,实现联合理解与生成任务。整体训练流程包含三个阶段:预训练、混合长 CoT 微调与 UniGRPO 强化学习。模型核心为一种离散扩散框架,作用于两种模态的分词序列。文本使用 LLaDA 分词器,图像则通过基于 MAGVIT-v2 的预训练量化器将像素数据转换为离散 token 序列,下采样因子为 16,使得 512×512 图像生成 32×32 的 token 图。这种统一分词方式使模型将两种模态均视为离散 token 序列,并由共享的掩码 token 预测器进行处理。
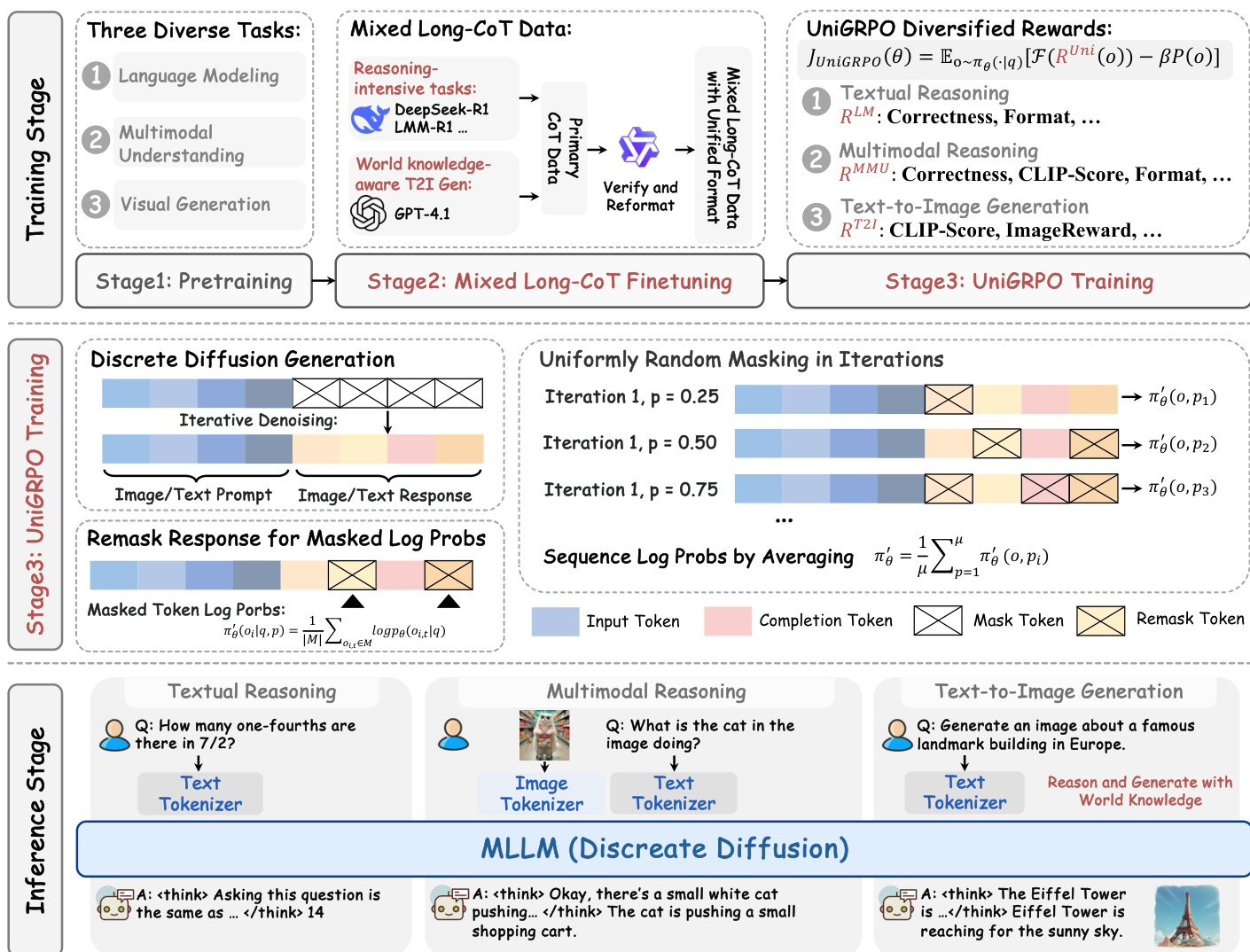
如图所示,预训练阶段(阶段一)采用统一的交叉熵损失训练模型作为掩码 token 预测器。模型参数化为 pθ(⋅∣xt),输入为噪声序列 xt,并同时预测所有被掩码的 token。前向扩散过程通过逐步添加噪声来破坏真实序列 x0,模型则被训练以恢复原始 token。损失仅在被掩码的 token 上计算,确保模型在受损上下文中学习正确预测。该统一公式在模态间对齐了噪声破坏与语义恢复过程,促进有效的跨模态交互。
第二阶段为混合长 CoT 微调,模型在精心筛选的长形式推理轨迹数据集上进一步优化。作者引入一种任务无关的 CoT 格式,将输出结构化为 <special_token> <reasoning_process> <special_token> <result>,连接模态特定输出并实现知识迁移。微调过程保留原始提示,并独立掩码结果中的 token,将拼接后的输入输入模型,以计算重建被掩码区域的损失。该联合训练方法在保持与原始提示对齐的同时,增强了任务特定能力。

第三阶段为 UniGRPO 训练,引入一种专为扩散模型设计的新型基于策略梯度的强化学习算法。该方法解决了将自回归 GRPO 适配至扩散架构的挑战,如局部掩码依赖性与无法通过链式法则计算序列级对数似然的问题。UniGRPO 采用结构化噪声策略,为每个响应随机采样掩码比例,确保模型暴露于多种去噪阶段。它近似扰动分布下的每 token 对数似然,并通过平均被掩码 token 计算序列级对数似然。策略梯度目标整合了裁剪的代理奖励与 KL 散度惩罚,以稳定训练。该设计使模型能够从多步去噪动态中学习,充分发挥扩散模型的完整生成能力。
实验
- 多模态理解:在 POPE、MME、VQAv2、GQA 与 MMMU 基准上达到最先进或具有竞争力的结果,优于 LLaVA-v1.5 等专用模型及 SEED-X、DreamLLM 等统一模型,由混合长 CoT 微调与 UniGRPO 阶段验证。
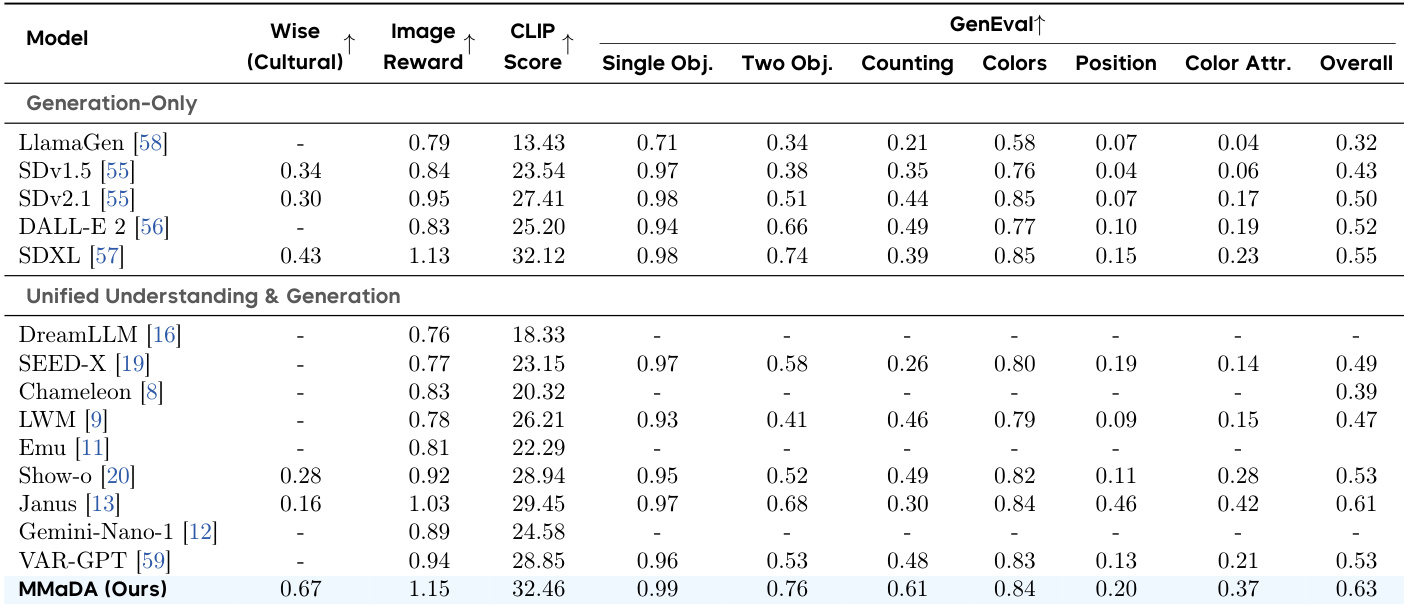
- 文生图生成:在 GenEval 与 WISE 基准上取得最高 CLIP Score 与 ImageReward,展现出卓越的组合性、物体计数能力与世界知识感知生成能力,归因于 UniGRPO 训练与联合推理。
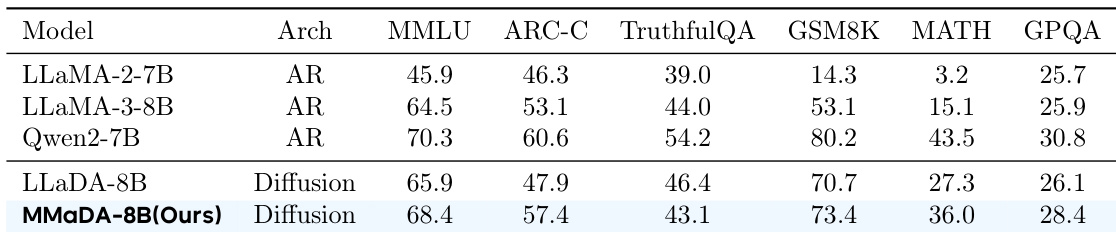
- 文本推理:在 MMLU 与 ARC-C 上表现与 Qwen2-7B 和 LLaMA3-8B 相当,在 GSM8K、MATH 与 GPQA 上超越 LLaDA-8B,证明了基于统一扩散模型在通用语言任务中的可行性。
- 消融研究:混合长 CoT 微调显著提升推理能力,尤其在数学与几何任务中;UniGRPO 进一步提升所有任务性能,证实其在增强理解与生成方面的有效性。
- UniGRPO 的设计选择:均匀随机掩码与部分答案掩码提升了训练稳定性与收敛性,同时更充分地利用了扩散模型动态。
- 任务协同:文本生成、多模态理解与图像生成的联合训练带来持续性能提升,输出更连贯、准确的跨模态结果。
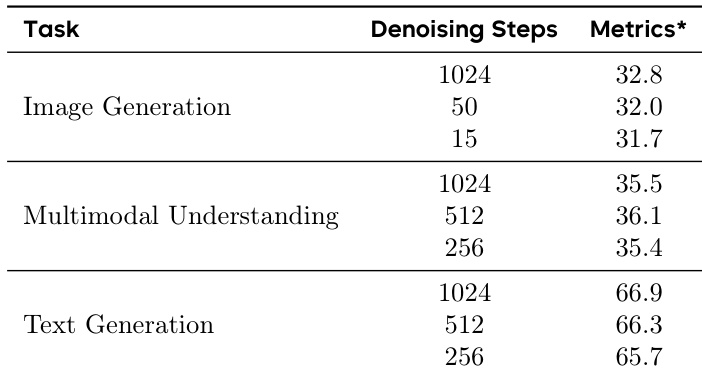
- 采样效率:基于扩散的生成在仅 15–50 次去噪步骤下即取得优异结果,相比自回归模型展现出显著效率优势,得益于并行 token 生成。
作者使用基于扩散的模型 MMaDA-8B 在语言建模基准上评估其性能。结果表明,MMaDA-8B 在多个任务上表现具有竞争力,尤其在数学推理与通用语言理解方面超越了 LLaMA-8B 与 Qwen2-7B 等强基线模型。
作者使用表格展示训练阶段对 MMADA 在多个基准上性能的影响。结果显示,阶段一后模型性能落后于基线,但引入混合长 CoT 微调后性能显著提升,尤其在推理任务中。进一步应用 UniGRPO 后,所有任务均取得显著进步,性能接近最先进方法。

作者使用表格对比其统一模型 MMaDA 与仅生成模型及统一模型在 CLIP Score、ImageReward 与 GenEval 基准上的文生图生成性能。结果显示,MMaDA 在 CLIP Score 与 ImageReward 上均取得最高分,全面超越其他模型,并在 GenEval 上展现出强大的组合与计数能力,尤其在 WISE 文化基准上表现突出。
作者使用表格评估 MMaDA 在不同去噪步数下于图像生成、多模态理解与文本生成任务中的性能。结果显示,即使仅使用 15 步去噪,模型在图像生成上仍保持强劲性能,而文本与多模态任务在远少于完整 1024 步的情况下即可生成连贯输出。
作者使用表格对比其模型 MMaDA 与多种基线在 POPE、MME 与 VQAv2 等基准上的多模态理解性能。结果显示,MMaDA 在多数任务中达到具有竞争力或更优结果,尤其在超越其他统一模型方面表现突出,凸显其提出训练阶段的有效性。