Command Palette
Search for a command to run...
统一多模态预训练中的涌现特性
统一多模态预训练中的涌现特性
摘要
统一的多模态理解与生成能力在前沿的专有系统中已展现出令人瞩目的性能。在本研究中,我们提出 BAGEL——一个原生支持多模态理解与生成的开源基础模型。BAGEL 是一个统一的解码器-only 架构模型,基于大规模交错排列的文本、图像、视频及网页数据,经过万亿级标记(tokens)的预训练。当利用如此多样化且交错的多模态数据进行扩展时,BAGEL 在复杂多模态推理方面展现出显著的涌现能力。因此,在标准基准测试中,BAGEL 在多模态生成与理解任务上均显著优于现有的开源统一模型,并展现出先进的多模态推理能力,包括自由形式的图像编辑、未来帧预测、三维空间操作以及世界导航等。为推动多模态研究的进一步发展,我们公开了关键研究成果、预训练细节、数据构建流程,并向社区开源代码与模型检查点。项目主页详见:https://bagel-ai.org/
一句话总结
来自字节跳动种子、深圳先进技术研究院、莫纳什大学、香港科技大学和加州大学圣克鲁兹分校的作者提出 BAGEL,一个基于万亿级交错多模态标记预训练的仅解码器开源基础模型,能够实现涌现的多模态推理和统一理解与生成的卓越性能,包括自由形式图像操作和3D世界导航,代码与检查点已发布,以推动社区研究。
主要贡献
-
BAGEL 是一个统一的仅解码器基础模型,在来自大规模交错文本、图像、视频和网络数据的万亿级标记上进行预训练,能够在单一架构中实现原生的多模态理解与生成。该设计使得此前主要基于图像-文本对训练的开源模型未能完全实现的复杂推理能力得以涌现。
-
该模型通过自由形式图像操作、未来帧预测、3D物体操作和世界导航等任务展现出先进的多模态推理能力,得益于其在多样化、交错多模态数据上的训练,支持跨模态的长上下文、组合式推理。
-
BAGEL 在标准多模态基准测试中显著优于现有开源统一模型,并发布其代码、检查点、预训练细节和数据构建协议,以促进进一步研究,推动多模态人工智能领域的透明度与可复现性。
引言
作者利用大规模、多模态交错数据——整合文本、图像、视频和网络内容——训练 BAGEL,一个统一的仅解码器模型,以推进多模态理解与生成。该方法解决了先前研究的关键局限:过度依赖图像-文本配对数据,无法支持跨多种模态的复杂、长上下文推理。通过利用多样化、交错的数据进行扩展,BAGEL 展现出自由形式图像操作、未来帧预测、3D物体交互和世界导航等涌现能力,显著缩小了与专有系统之间的性能差距。主要贡献是一个可扩展的开源框架,通过统一预训练实现先进多模态推理,并配套详细的协议、代码和检查点,加速社区研究进程。
数据集
- BAGEL 模型在多样化、多模态数据集上进行训练,结合语言、图像、视频和网络数据,支持多模态推理、上下文内预测和未来帧生成等任务,通过统一接口实现。
- 数据集包含三个主要组成部分:纯文本数据、视觉-文本配对数据,以及从视频和网络来源新构建的交错数据。
- 纯文本数据为高质量数据,经过精心筛选,以保持在通用文本任务中强大的语言建模与推理能力。
- 视觉-文本配对数据分为两个子集:
- VLM 图像-文本对:来源于网页 alt-text 和标题,通过 CLIP 相似度、分辨率/长宽比约束、文本长度检查和去重进行筛选;包含 OCR、图表和定位标注等结构化监督信息。
- T2I 图像-文本对:包含高质量真实图像-文本对,以及来自现有 T2I 模型的少量合成数据,涵盖多样化的标题风格,具有高图像清晰度、结构完整性和语义多样性。
- 视频数据来源于公开在线视频及两个开源数据集——Koala36M(教学内容)和 MVImgNet2.0(多视角物体捕捉),以支持时空理解。
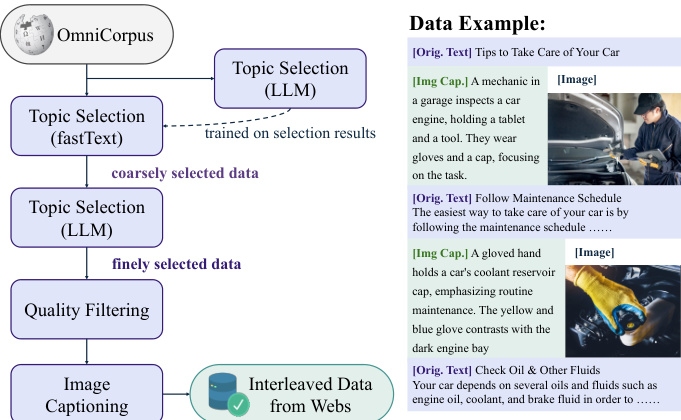
- 网络数据基于 OmniCorpus,一个来自 Common Crawl 的大规模集合,通过开源图像编辑数据集增强,提供结构化、交错的文本-图像内容。
- 视频数据过滤:使用镜头检测对视频片段进行分割,裁剪去除边框和叠加元素,并根据长度、分辨率、清晰度、运动稳定性以及基于 CLIP 的去重进行筛选。
- 网络数据过滤:采用两阶段流水线——首先,使用在 LLM 生成标签上训练的 fastText 分类器筛选相关文档;其次,由 Qwen2.5-14B 模型执行细粒度过滤,随后通过规则检查图像清晰度、相关性及文档结构。
- 交错视频数据通过使用蒸馏后的 Qwen2.5-VL-7B 模型在连续帧之间生成短时序锚定的标题(最多 30 个标记)构建;平均每段视频产生 4500 万条交错序列。
- 交错网络数据采用“标题优先”策略:每个图像前均附加简洁的 LLM 生成标题(通过 Qwen2.5-VL-7B 生成),以引导图像生成并提升对齐效果;超过 300 个标记的图像间文本段落由 LLM 摘要,以增强上下文密度,最终生成 2000 万条结构化序列。
- 训练过程中,模型使用精心调优比例的多种数据类型混合,结合文本、视觉-文本对以及交错视频和网络数据,以平衡模态并支持多样化的推理与生成任务。
方法
作者采用 Mixture-of-Transformer-Experts(MoT)架构,在单一模型中统一多模态理解与生成,实现两种模态之间的无缝交互。如框架图所示,模型采用两种不同的 Transformer 专家:一个以理解为导向的专家,一个以生成为导向的专家。这两个专家在每一层通过共享的自注意力操作处理相同的标记序列,无需瓶颈连接,从而实现理解与生成过程之间的长上下文交互。这种无瓶颈设计促进了训练数据与训练步数的扩展,使模型的全部能力信号得以在无架构限制下自然涌现。
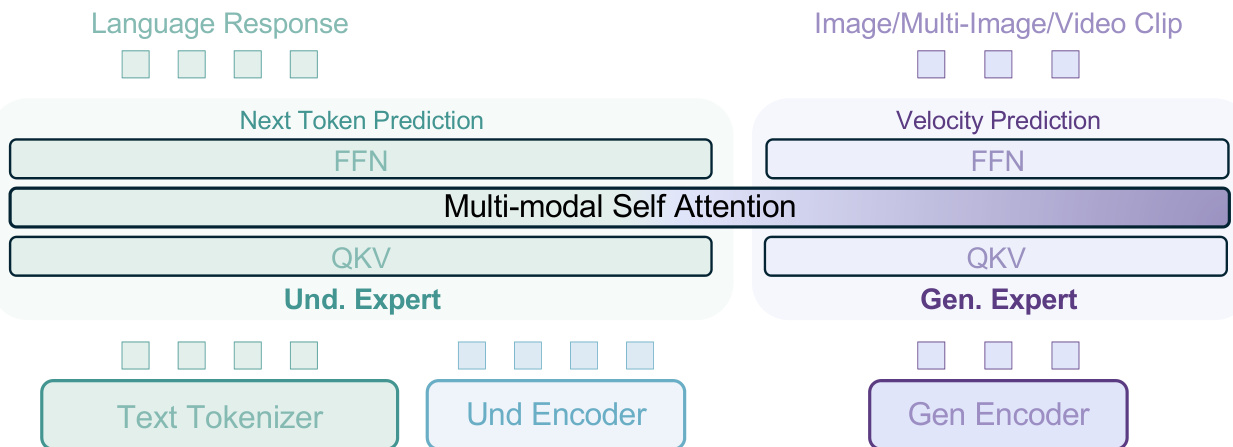
骨干模型初始化自仅解码器 Transformer 架构,具体为 Qwen2.5,其包含 RMSNorm 用于归一化,SwiGLU 用于激活,RoPE 用于位置编码,以及 GQA 用于 KV 缓存压缩。为稳定训练,每个注意力模块中均添加了 QK-Norm。视觉信息通过两条独立路径处理:在理解方面,ViT 编码器将原始像素转换为标记,初始化自 SigLIP2-so400m/14,并通过 NaViT 增强以支持原生长宽比处理;在生成方面,使用来自 FLUX 的预训练 VAE 模型将图像转换为潜在空间,训练期间冻结 VAE 模型。ViT 与 VAE 的标记均通过 2D 位置编码整合进 LLM 骨干网络,扩散时间步编码则直接应用于 VAE 标记的初始隐藏状态。
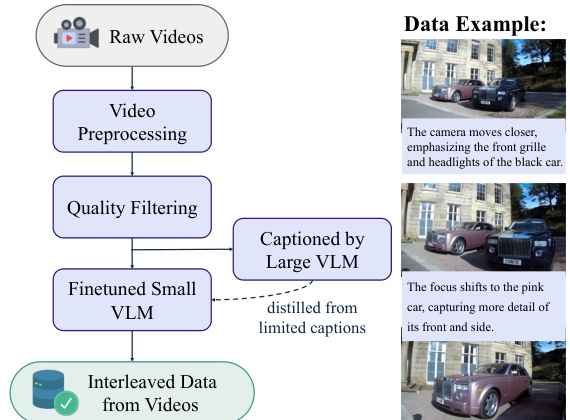
模型的训练数据通过可扩展协议构建,整合了网络与视频来源。视频数据提供像素级、概念性、时间性和物理连续性,为获取具身世界知识提供关键信号。交错数据格式包含多模态对话、文本到图像/视频生成、图像操作等任务,实现多样化生成数据的无缝集成。为增强推理能力,数据通过引入以推理为导向的内容进行丰富,促进跨模态推理与理解-生成过程之间的知识迁移。该精心构建的数据集捕捉了丰富的世界知识与细微的跨模态交互,赋予模型在上下文内预测、世界建模和复杂多模态推理方面的基础能力。
训练过程中,一个交错多模态生成样本可能包含多个图像,每个图像具有三组视觉标记:用于 Rectified-Flow 训练的噪声 VAE 标记、用于条件输入的干净 VAE 标记,以及用于输入格式统一的 ViT 标记。在交错图像或文本生成中,后续标记可关注前序图像的干净 VAE 与 ViT 标记,但不关注其噪声版本。在交错多图像生成中,采用扩散强制策略,为不同图像添加独立的噪声水平,并将每个图像条件化于前序图像的噪声表示。为增强生成一致性,连续图像被随机分组,并在每组内应用全注意力机制。广义因果注意力机制通过 PyTorch FlexAttention 实现,相比朴素的缩放点积注意力实现约 2 倍加速。推理时,广义因果结构允许缓存已生成多模态上下文的键值对,加速解码过程。仅存储干净 VAE 标记与 ViT 标记的 KV 对,一旦图像完全生成,对应的噪声 VAE 标记即被其干净版本替换。通过以特定概率随机丢弃文本、ViT 与干净 VAE 标记,实现无分类器引导。

模型在增强推理的数据上进行训练,涵盖四类共 50 万例:文本到图像生成、自由形式图像操作和概念性编辑。在文本到图像生成中,模糊查询与简单引导配对,Qwen2.5-72B 被提示生成额外的查询-引导对与详细提示,随后传递给 FLUX.1-dev 生成目标图像。在自由形式图像操作中,使用 VLM 接收源图像与目标图像对、用户查询以及来自 DeepSeek-R1 的推理轨迹示例,生成具身解释。概念性编辑采用三阶段 VLM 流程构建高质量 QA 示例,使模型学会从多样化文本指令中理解复杂视觉目标。该方法帮助模型学习将图像生成基于语言推理,并提升复杂视觉任务的规划能力。
实验
- 在 15 亿参数 LLM 上对比 Dense Transformer、MoE 与 MoT 变体;MoT 始终优于两者,尤其在多模态生成中 MSE 损失更低且收敛更快,验证了分离生成与理解参数的优势。
- 数据采样比例消融实验表明,将生成数据比例从 50% 提升至 80% 可使 MSE 损失降低 0.4%,表明训练中应优先考虑生成任务。
- 学习率消融实验揭示权衡:较高学习率加速生成收敛,较低学习率提升理解能力;采用目标加权的平衡策略。
- 在 MME、MMBench、MM-Vet、MMMU、MathVista 和 MMVP 基准测试中,BAGEL-7B 达到最先进性能,分别在 MMMU 和 MM-Vet 上超越 Janus-Pro 14.3 和 17.1 分。
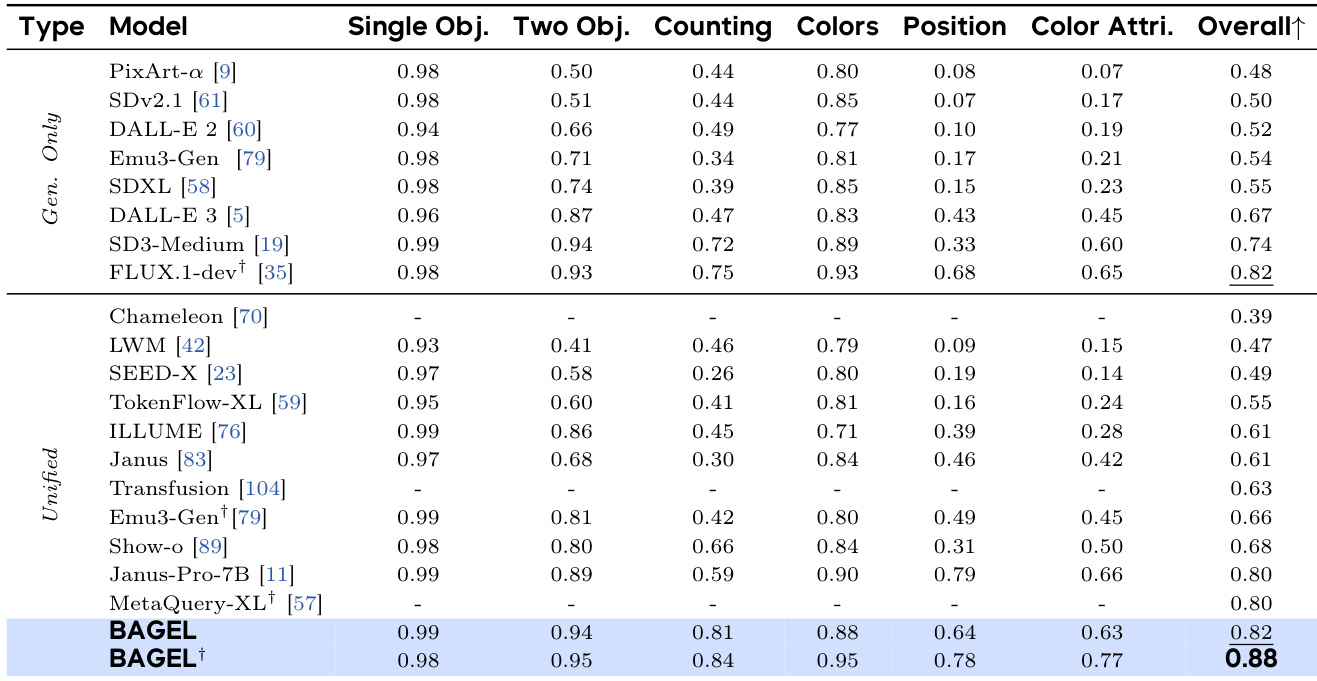
- 在 GenEval 上,BAGEL 得分为 88%,超越专用模型(FLUX-1-dev: 82%,SD3-Medium: 74%)和统一模型(Janus-Pro: 80%,MetaQuery-XL: 80%)。
- 在 WISE 上,BAGEL 超过所有开源模型,仅低于 GPT-4o,表明其在文本到图像生成中具备强大的世界知识整合能力。
- 在 GEdit-Bench 上,BAGEL 与领先的专业模型 Step1X-Edit 表现相当,并优于 Gemini 2.0;在 IntelligentBench 上得分为 44.9,比 Step1X-Edit 高出 30 分,验证其卓越的复杂推理能力。
- 使用思维链推理后,BAGEL 的 WISE 得分提升至 0.70(从 0.52),IntelligentBench 得分提升至 55.3(从 44.9),显示多模态推理能力显著增强。
- BAGEL 展现出涌现能力:理解与生成能力早期即出现,而智能编辑需达到 3.61T 标记才达 85% 性能,表明其复杂推理能力在后期才涌现。
- BAGEL-1.5B 在定性图像生成与编辑方面优于更大模型(JanusPro-7B、Step1X-Edit-12B),凸显其强大效率与可扩展性。
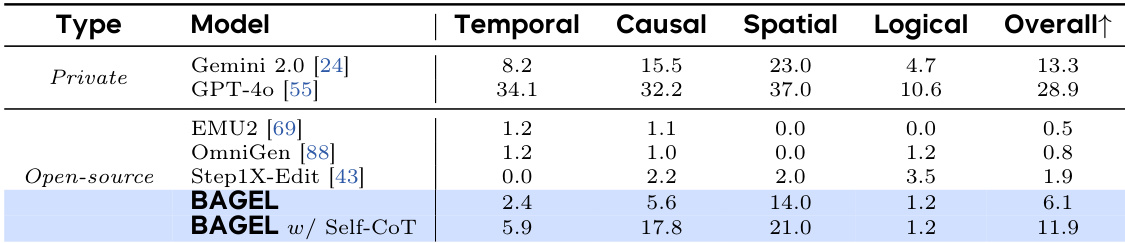
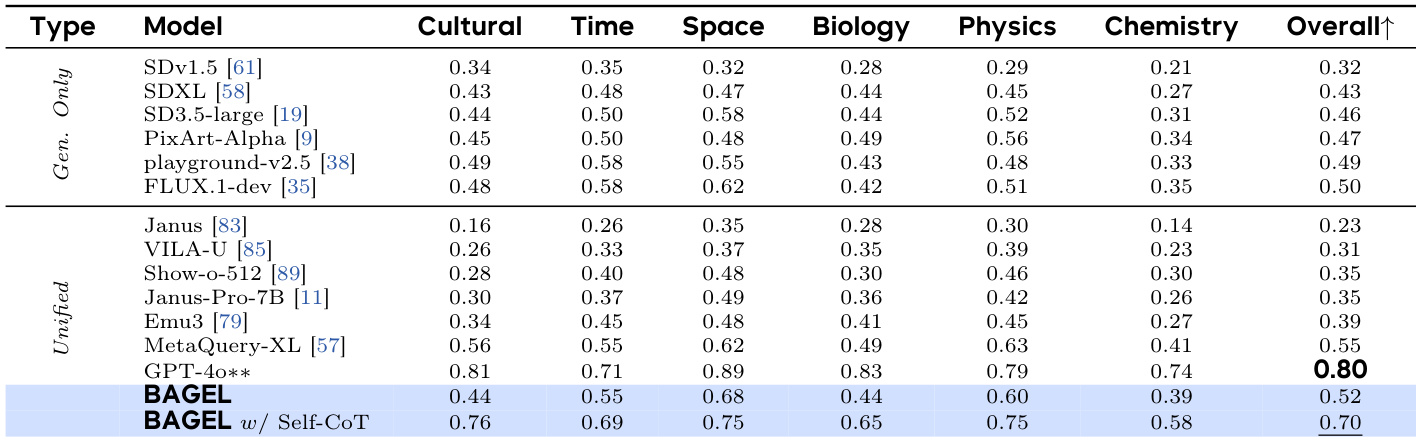
作者在 KRIS-Bench 评估套件上将 BAGEL 与其他模型进行比较,该套件评估属性感知、空间感知、时间预测、社会科学、自然科学、逻辑推理和指令分解能力。结果显示,BAGEL 采用自生成思维链(self-CoT)后获得 11.9 的最高总分,显著优于其他开源模型,并接近 GPT-4o 等私有模型的性能。
作者在多模态理解基准上比较了多种模型的性能,BAGEL 及其变体得分均高于专用生成模型和其他统一模型。BAGEL w/ Self-CoT 达到 0.70 的最高总分,显著优于标准 BAGEL 模型及其他最先进模型,表明推理能力显著增强多模态理解能力。
作者在 GEdit-Bench 上将 BAGEL 与现有模型进行比较,该基准评估经典图像编辑任务。结果显示,BAGEL 总得分为 0.88,与最佳模型 FLUX-1-dev 相当,并优于其他统一模型,表明其在图像编辑方面具备强大竞争力。
作者在 KRIS-Bench 上将 BAGEL 与私有模型和开源模型进行比较,评估其在事实性、概念性和程序性推理任务上的表现。结果显示,BAGEL 在开源模型中总分最高,采用自生成思维链推理后在程序性和概念性推理方面有显著提升。
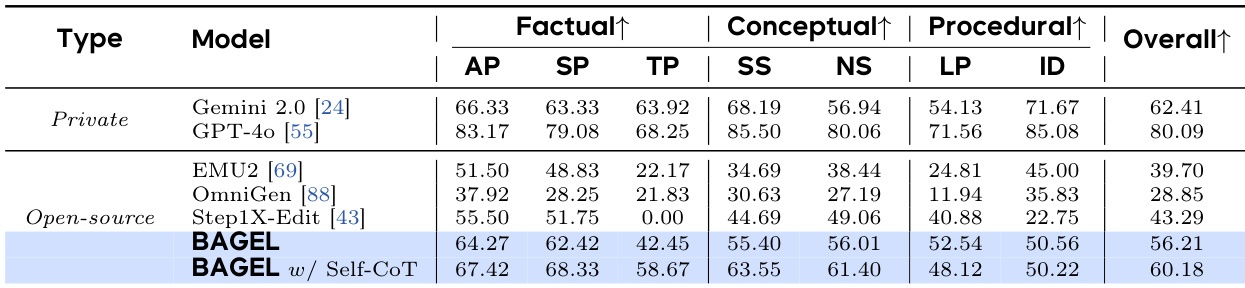
作者在 IntelligentBench 评估套件上比较 BAGEL 与其他模型的性能,该套件评估图像编辑中的复杂多模态推理。结果显示,BAGEL 得分为 44.9,而采用自生成思维链推理的增强版本(BAGEL w/ Self-CoT)得分为 55.3,显著更高,超越所有开源模型,接近私有模型性能。
