Command Palette
Search for a command to run...
通义千问Qwen3技术报告
通义千问Qwen3技术报告
摘要
在本工作中,我们推出了通义千问系列的最新版本——Qwen3。Qwen3是一系列大型语言模型(LLMs),旨在进一步提升性能、效率以及多语言能力。该系列涵盖密集模型(dense models)与混合专家(Mixture-of-Experts, MoE)架构,参数规模从0.6亿到235亿不等。Qwen3的一项关键创新在于,将“思考模式”(适用于复杂、多步骤推理任务)与“非思考模式”(适用于快速、上下文驱动的响应)统一集成至同一框架中。这一设计无需在不同模型之间切换——例如无需在对话优化模型(如GPT-4o)与专用推理模型(如QwQ-32B)之间切换——并可根据用户查询或对话模板实现动态模式切换。与此同时,Qwen3引入了“思考预算”(thinking budget)机制,允许用户在推理过程中自适应地分配计算资源,从而根据任务复杂度灵活平衡延迟与性能表现。此外,通过充分利用旗舰模型所蕴含的知识,我们在显著降低训练成本的前提下,构建了性能优异的小规模模型,大幅减少了构建中小型模型所需的计算资源消耗。实证评估表明,Qwen3在多个基准测试中均取得了领先水平的表现,涵盖代码生成、数学推理、智能体任务等多样化场景,其性能可与更大规模的MoE模型及专有模型相媲美。相较于前代版本Qwen2.5,Qwen3将多语言支持从29种语言和方言扩展至119种,显著提升了跨语言理解与生成能力,进一步增强了模型的全球适用性与可及性。为促进研究的可复现性及社区驱动的协同开发,所有Qwen3模型均已开源,采用Apache 2.0许可协议,向全球研究者与开发者开放使用。
一句话总结
作者提出 Qwen3,一个统一的大语言模型家族,采用密集型和专家混合(Mixture-of-Expert)架构,参数规模从 0.6 亿到 2350 亿不等,融合动态思考与非思考模式,实现自适应推理与响应效率,支持无缝的任务特定推理而无需模型切换,同时引入思考预算机制以优化资源使用,并将多语言支持显著扩展至 119 种语言,公开模型采用 Apache 2.0 许可。
主要贡献
- Qwen3 引入统一架构,无缝集成复杂多步推理的思考模式与快速上下文驱动响应的非思考模式,无需在独立模型间切换,可根据任务需求动态适应。
- 模型基于涵盖 119 种语言和方言的 36 万亿 token 预训练数据集,采用三阶段训练流程,提升推理、编码与长上下文理解能力,同时通过思考预算机制使用户可控制每项任务的计算资源。
- Qwen3 在关键基准测试中达到最先进水平——AIME'24 达 85.7,LiveCodeBench v5 达 70.7,CodeForces 达 2,056,展现出在代码生成、数学推理和智能体任务方面与更大规模专有模型及 MoE 模型相媲美的强大竞争力。
引言
作者借助开源大语言模型日益增长的发展势头,推动通用人工智能的探索,解决以往模型在推理与非推理任务中常需独立架构、难以精细控制计算投入、多语言与长上下文能力受限等局限。为克服这些挑战,Qwen3 提出统一架构,在单一模型中无缝融合思考与非思考模式,通过可配置的思考预算实现推理深度的动态调整。该设计结合在 119 种语言上 36 万亿 token 的预训练数据,以及包含思维链监督与强化学习的多阶段后训练流程,使 Qwen3 在编程、数学与基于智能体的任务中达到最先进性能。发布密集型与专家混合型变体(最大总参数达 2350 亿,每 token 激活 220 亿参数),确保可扩展性与高效性,使 Qwen3 成为适用于多样化现实应用场景的强大、灵活且可访问的基础模型。
数据集
- 预训练数据集包含 36 万亿 token,覆盖 119 种语言和方言,语言覆盖范围超过 Qwen2.5 的三倍(Qwen2.5 使用 29 种语言)。
- 数据来源涵盖编码、STEM、推理任务、书籍、多语言文本及合成数据等高质量内容。
- 通过 Qwen2.5-VL 模型对 PDF 类文档进行光学字符识别(OCR),提取额外文本,再经 Qwen2.5 模型进行质量优化。
- 使用 Qwen2.5、Qwen2.5-Math 和 Qwen2.5-Coder 模型生成万亿级合成 token,产出教材、指令、问答对、代码片段等结构化内容,覆盖数十个领域。
- 构建多语言数据标注系统,对超过 30 万亿 token 进行细粒度标注,涵盖教育价值、领域、学科与安全属性,支持精准数据筛选与混合优化。
- 与以往在源或领域层面调整数据混合比例的方法不同,本工作在实例层面优化数据混合,基于小规模代理模型的消融实验与详细标签进行分析。
- 针对长思维链(long-CoT)训练,专门构建数学、代码、逻辑推理与通用 STEM 问题数据集,每题均配有验证答案或测试用例。
- 采用两阶段过滤流程:首先使用 Qwen2.5-72B-Instruct 过滤非可验证、多部分或易回答的问题,确保仅保留复杂推理任务。
- 使用 Qwen2.5-72B-Instruct 对查询进行领域分类标注,以保持各类别间均衡分布。
- 对每个过滤后的查询,使用 QwQ-32B 生成 N 个候选回答;若未找到正确解,则由人工标注者评估准确性。
- 进一步过滤掉包含错误最终答案、过度重复、猜测行为、推理摘要不一致、语言/风格突变或与验证集潜在重叠的回答。
- 最终精炼数据集用于极小样本、有限训练步数的冷启动训练阶段,旨在建立基础推理模式,避免对性能指标过拟合。
- 此预备阶段为后续强化学习奠定基础,保持模型灵活性并支持更广泛提升。
方法
Qwen3 系列采用全面的训练框架,旨在实现多样化任务的高性能,同时支持高效部署。后训练流程如图所示,围绕两个核心目标展开:思考控制与强到弱蒸馏。旗舰模型遵循四阶段训练序列。第一阶段为长思维链冷启动(Long-CoT Cold Start),聚焦长上下文理解能力初始化。第二阶段为推理强化学习(Reasoning RL),通过强化学习提升模型推理能力。第三阶段为思考模式融合(Thinking Mode Fusion),将非思考与思考模式整合为统一框架,支持根据用户输入动态切换模式。第四阶段为通用强化学习(General RL),通过优化指令遵循、格式一致性、偏好对齐、智能体能力与特定场景表现,全面提升模型在各类场景下的综合能力。
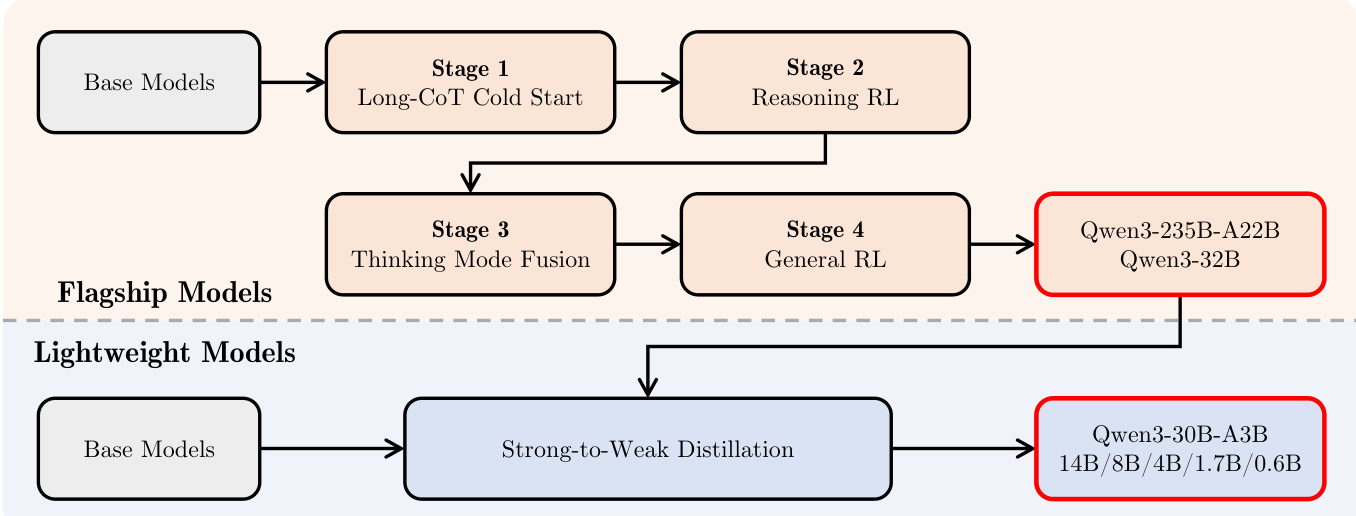
思考与非思考模式的融合通过精心设计的对话模板实现。用户可通过在查询或系统消息中加入 /think 或 /no_think 标志指定期望模式。这使模型能动态切换模式,默认情况下采用思考模式,除非明确指示。在非思考模式下,助手响应中保留空的思考块,以维持内部格式一致性。该设计使开发者仅需修改对话模板即可控制模型的推理行为。
该框架还引入思考预算机制,允许用户在推理过程中自适应分配计算资源。当模型思考过程达到用户设定的阈值时,系统手动终止思考,并插入“停止思考”指令。随后模型基于截至该点的累积推理生成最终响应。此能力自然源于思考模式融合阶段,使用户可根据任务复杂度在延迟与性能之间取得平衡。
对于轻量级模型,采用强到弱蒸馏(Strong-to-Weak Distillation)方法简化训练流程。该流程分为两个阶段:离策略蒸馏与同策略蒸馏。在离策略阶段,使用教师模型在思考与非思考模式下生成的输出,将知识蒸馏至学生模型,使其具备基础推理能力与模式切换能力。在同策略阶段,学生模型在任一模式下生成序列,并通过将其 logits 与教师模型对齐,最小化 KL 散度进行微调。该方法显著降低构建小规模模型所需的计算资源,同时确保其具备竞争力的性能。
实验
- Qwen3-235B-A22B-Base 在 15 个基准测试中,有 14 个优于 Qwen2.5-Plus-Base、Llama-4-Maverick-Base 和 DeepSeek-V3-Base,仅使用约 1/3 总参数与 2/3 激活参数,展现出卓越的效率与性能。
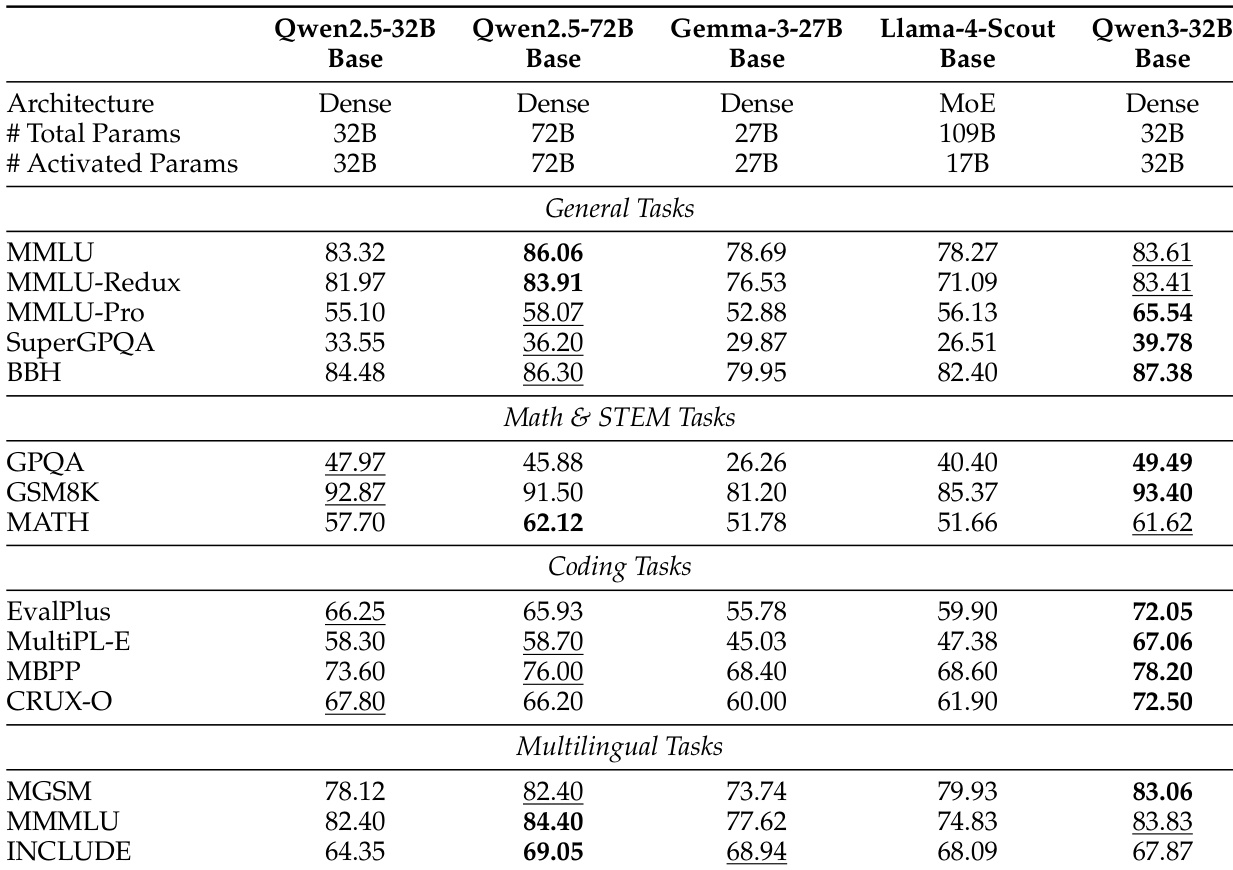
- Qwen3-32B-Base 在 MMLU-Pro 上达 65.54,在 SuperGPQA 上达 39.78,超越 Qwen2.5-32B-Base 与 Gemma-3-27B-Base,尽管参数不足其一半,仍优于 Qwen2.5-72B-Base 在 10 个基准测试中的表现。
- Qwen3-30B-A3B-Base 仅使用 1/5 激活参数,性能与 Qwen3-14B-Base 及 Qwen2.5-32B-Base 相当,凸显强到弱蒸馏的有效性。
- Qwen3-235B-A22B(思考模式)在开源模型中达到最先进水平,优于 DeepSeek-R1 在 17/23 基准测试中,接近 OpenAI-o1 与 Gemini2.5-Pro 等闭源模型。
- Qwen3-235B-A22B(非思考模式)在 18/23 基准测试中超越 GPT-4o-2024-11-20,展示出无需显式推理的强大通用能力。
- Qwen3-32B(思考模式)在 17/23 基准测试中优于 QwQ-32B,与 OpenAI-o3-mini(中等)竞争,确立其作为新一代 32B 推理模型的最先进地位。
- Qwen3-8B、Qwen3-4B、Qwen3-1.7B 与 Qwen3-0.6B 模型在思考与非思考模式下均优于更大规模的 Qwen2.5 对应模型,证实轻量级模型蒸馏的成功。
- 在 RULER 基准测试中,Qwen3 模型在非思考模式下表现出色的长上下文能力,但思考模式下因推理内容干扰略有性能下降。
- 在 Belebele 与多语言基准测试中,Qwen3 模型在 80 种语言上表现具有竞争力,优于 Qwen2.5,与同规模 Gemma 模型相当。
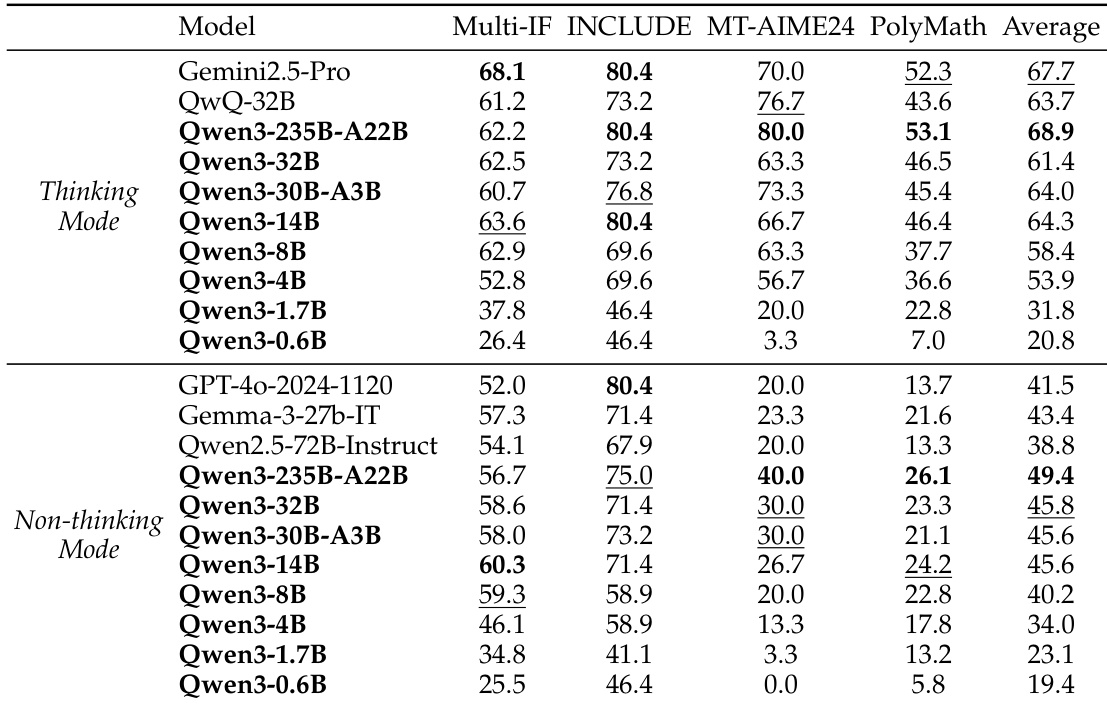
作者使用表格对比 Qwen3 模型在多种基准测试中思考与非思考模式下的性能表现。结果显示,Qwen3-235B-A22B 在思考模式下平均得分最高,超越 Gemini2.5-Pro 与其他强基线模型;Qwen3-32B 与 Qwen3-30B-A3B 在两种模式下均表现强劲,超越参数量更大的模型。
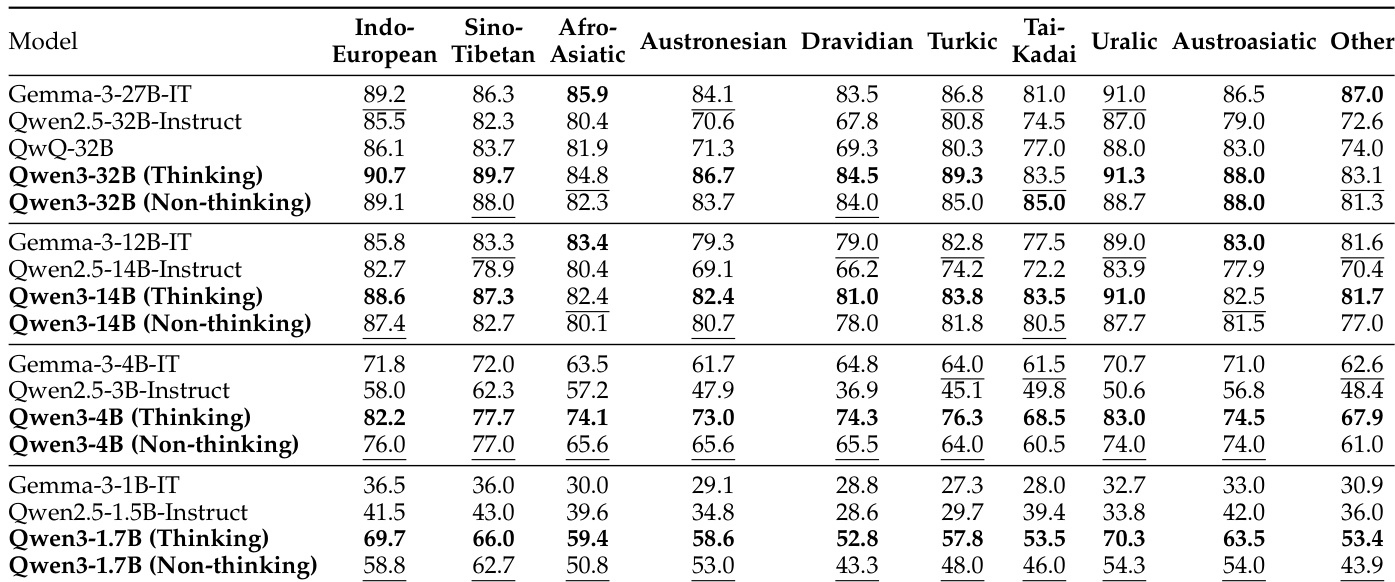
作者对比 Qwen3 模型在多种语言(包括印欧语系、汉藏语系、亚非语系等)中的多语言性能。结果显示,Qwen3-32B(非思考模式)在多数语言类别中得分最高,优于同规模的 Qwen2.5 模型,展现出强大的多语言能力。
作者将 Qwen3-32B-Base 与多个同规模开源模型(包括 Qwen2.5-32B-Base、Gemma-3-27B-Base 与 Llama-4-Scout-Base)进行对比。结果显示,Qwen3-32B-Base 在多数基准测试中优于 Qwen2.5-32B-Base 与 Gemma-3-27B-Base,与更大规模的 Qwen2.5-72B-Base 竞争力相当,且尽管参数仅为 Llama-4-Scout-Base 的三分之一,仍显著超越其表现。
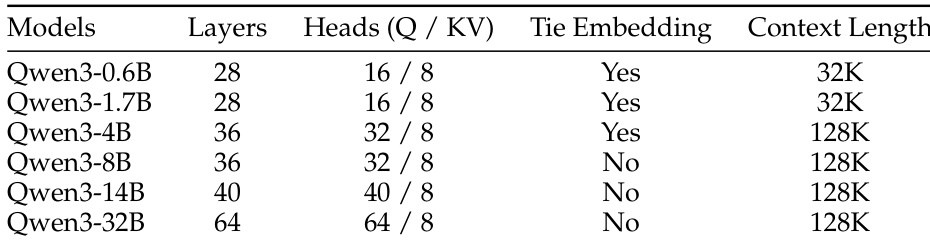
作者使用所提供表格详细说明 Qwen3 系列模型的架构规格,显示模型规模随层数、注意力头数与上下文长度增加而增长。表格表明,Qwen3-0.6B 与 Qwen3-1.7B 采用嵌入层共享(tie embedding)与 32K 上下文长度,而从 Qwen3-4B 到 Qwen3-32B 的更大模型采用 128K 上下文长度且不使用嵌入层共享。
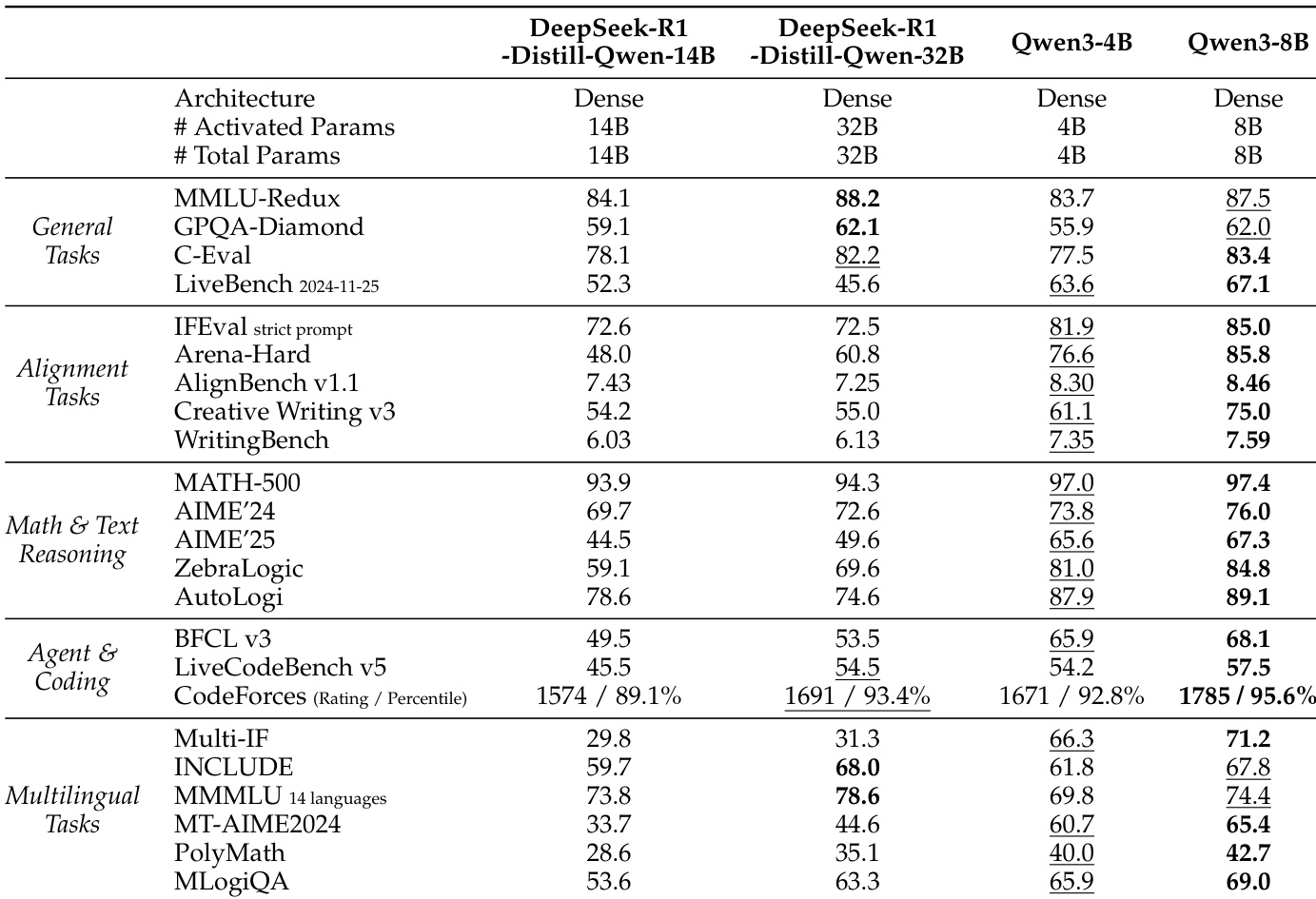
作者将 Qwen3-4B 与 Qwen3-8B 与 DeepSeek-R1-Distill 模型及其他基线模型在多个任务上进行对比。结果显示,Qwen3-8B 在多数基准测试中优于 Qwen3-4B 与 DeepSeek-R1-Distill 模型,尤其在数学、推理与编码任务中表现突出,且在多个领域得分高于更大模型如 DeepSeek-R1-Distill-Qwen-32B。