Command Palette
Search for a command to run...
Flow-GRPO:通过在线强化学习训练流匹配模型
Flow-GRPO:通过在线强化学习训练流匹配模型
Jie Liu Gongye Liu Jiajun Liang Yangguang Li Jiaheng Liu Xintao Wang Pengfei Wan Di Zhang Wanli Ouyang
摘要
我们提出Flow-GRPO,这是首个将在线策略梯度强化学习(Reinforcement Learning, RL)融入流匹配(flow matching)模型的方法。本方法采用两种关键策略:(1)通过ODE-to-SDE转换,将原本确定性的常微分方程(ODE)转化为等价的随机微分方程(SDE),该SDE在所有时间步上均保持与原模型边缘分布一致,从而支持统计采样以实现强化学习中的探索;(2)提出去噪缩减(Denoising Reduction)策略,在不减少推理阶段采样步数的前提下显著减少训练阶段的去噪步数,大幅提升了采样效率,同时保持原有生成性能。实验结果表明,Flow-GRPO在多个文本到图像生成任务中均表现出色。在组合生成任务中,经过强化学习微调的SD3.5-M模型能够近乎完美地生成物体数量、空间关系及细粒度属性,使GenEval评测准确率从63%提升至95%。在视觉文本渲染任务中,生成准确率也从59%提升至92%,显著增强了文本生成质量。此外,Flow-GRPO在人类偏好对齐方面也取得了显著提升。值得注意的是,极少出现奖励滥用(reward hacking)现象,即奖励提升并未以图像质量或多样性明显下降为代价。
一句话总结
来自MMLab、香港中文大学、快手科技及合作机构的作者提出Flow-GRPO,一种将在线策略梯度强化学习(RL)通过ODE到SDE转换集成到流匹配模型中的新方法,以增强探索能力并减少去噪步骤,从而提升采样效率,在文本到图像生成、组合准确性及人类偏好对齐方面实现最先进性能,且奖励欺骗极小。
主要贡献
-
Flow-GRPO首次将在线策略梯度强化学习(RL)集成到流匹配模型中,通过ODE到SDE转换将底层ODE转化为等价SDE,解决了其确定性本质的根本挑战,从而在保持原始边缘分布不变的前提下,引入可控随机性以实现RL探索所必需的随机采样。
-
该方法采用去噪减少策略,在不改变推理调度的前提下减少训练过程中的去噪步骤,显著提升采样效率并降低数据生成成本,同时保持高质量输出,并支持可扩展的在线RL训练。
-
实验表明,Flow-GRPO在组合生成任务上达到最先进水平(GenEval准确率从63%提升至95%),在视觉文本渲染任务上也表现优异(准确率从59%提升至92%),同时在DrawBench上改善人类偏好对齐,且几乎无奖励欺骗,图像质量与多样性未下降。
引言
流匹配模型因其高效的确定性采样和出色的图像质量,已成为文本到图像生成领域的主流方法,但在复杂组合任务和准确文本渲染方面仍面临挑战。以往生成模型的对齐方法主要依赖离线强化学习或直接微调,而在线强化学习——在提升语言模型推理能力方面已被证明有效——在基于流的模型中仍鲜有探索。关键挑战在于基于ODE的流模型的确定性本质与在线RL所需的随机采样之间的冲突,加之大型模型中迭代采样的高计算成本。为此,作者提出Flow-GRPO,通过两项核心创新将GRPO集成到流匹配中:其一,将ODE转换为SDE,引入可控随机性而不改变边缘分布;其二,应用去噪减少策略,在训练阶段减少采样步数,同时在推理阶段保留完整的去噪调度。这使得高效在线RL训练成为可能,且奖励欺骗极小。实验表明,Flow-GRPO显著提升了组合生成与文本渲染性能——GenEval准确率从63%提升至95%,文本渲染准确率从59%提升至92%——超越GPT-4o,同时保持高图像质量,并在多种奖励类型上具有良好泛化能力。
数据集
- 数据集由来自多样化公开网络爬取的图像-文本对构成,经过筛选以确保高质量并贴合多模态生成任务需求。
- 每个子集通过多种自动化质量指标进行过滤:美学评分(基于CLIP的回归器)、DeQA评分(用于低级伪影检测的多模态大模型)、ImageReward(评估对齐与保真度的T2I偏好模型)以及UnifiedReward(用于人类偏好预测的最先进统一奖励模型)。
- 过滤过程对这些指标施加严格阈值,仅保留高质量、视觉连贯且语义对齐的图像-文本对,确保训练信号的稳健性。
- 最终数据集划分为训练集、验证集和测试集,其中训练集用于在监督学习与强化学习目标混合的基础上微调基础模型。
- 训练中的混合比例根据各奖励模型的相对性能与覆盖范围确定,以平衡对齐性、质量与安全性。
- 图像在预处理阶段被裁剪至标准化分辨率以保证一致性,同时保留源域、图像尺寸和质量评分等元数据,供下游分析与模型评估使用。
方法
作者利用组相对策略优化(GRPO)增强流匹配模型在文本到图像生成中的表现,提出一种新颖框架,将在线强化学习整合至采样过程中。整体架构如图所示,包含三个主要组件:基于确定性ODE衍生的随机采样机制、用于高效数据收集的去噪减少策略,以及基于组相对奖励更新模型的策略优化循环。
该方法的核心在于将标准流匹配中使用的确定性常微分方程(ODE)转换为等价的随机微分方程(SDE)。这一转换使得生成有效强化学习所需的多样化轨迹成为可能。原始确定性ODE定义前向过程为 dxt=vtdt,通过添加扩散项引入随机性。由此产生的反向时间SDE形式为 dxt=(vt(xt)−2σt2∇logpt(xt))dt+σtdw,其中 σt 控制噪声水平,dw 表示维纳过程增量。该SDE确保随机过程在所有时间步的边缘分布与原始确定性模型一致,从而在保留模型生成能力的同时引入探索所需的随机性。
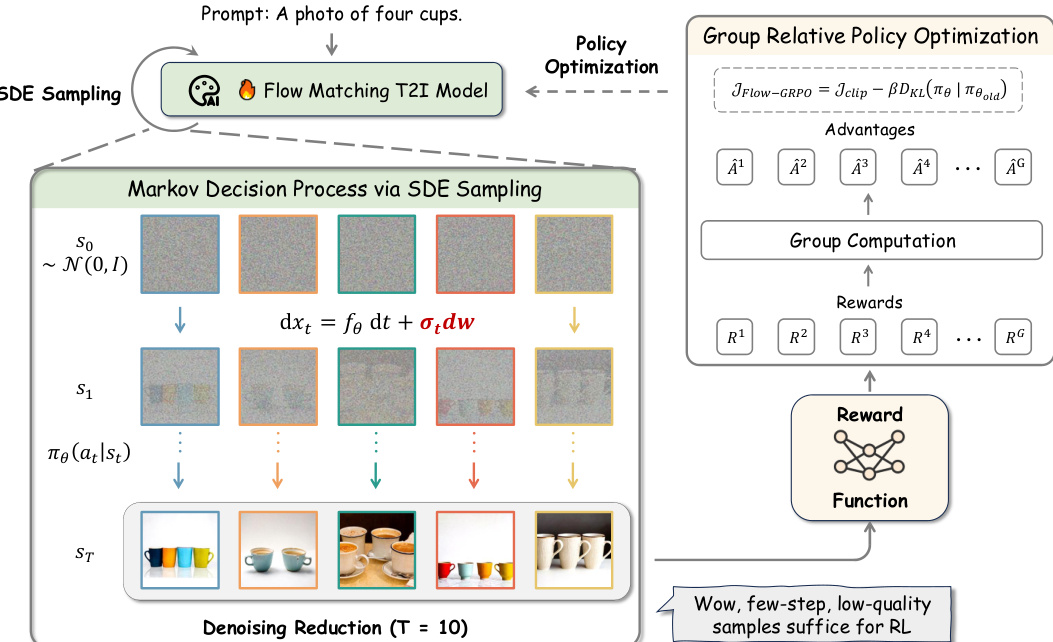
如图所示,该框架以提示词(如“四只杯子的照片”)为起点,输入流匹配T2I模型。模型随后采用SDE采样生成一系列图像,从噪声分布 N(0,I) 开始,通过马尔可夫决策过程逐步去噪。该过程中的每一步 t 由状态 st 定义,包含条件文本 c、当前时间步 t 和噪声图像 xt。每一步的动作为模型策略 πθ(at∣st) 预测的去噪样本 at。状态间转移为确定性,但SDE引入的随机性确保策略可探索不同路径,生成多样化轨迹。
为提升训练效率,作者实施去噪减少策略,在强化学习的数据收集阶段显著减少去噪步数。图中表示为 T=10 步,远少于高质量推理中常用的 T=40 步。该减少允许快速生成低质量但信息丰富的样本,足以支持RL过程。这些样本的奖励由奖励函数计算,用于评估生成图像与提示的匹配程度。随后,这些奖励用于计算组相对优势,并输入GRPO损失函数。
GRPO损失如图所示,定义为 JFlow-GRPO=Jclip−βDKL(πθ∣πold)。第 i 个样本在 G 个样本组中的组相对优势 A^ti 通过归一化组级奖励计算得出。策略通过最大化该目标进行更新,其中包含用于稳定训练的裁剪项和用于防止策略大幅更新的KL散度惩罚项。该方法确保模型学习生成不仅与提示对齐,且具备高质量与多样性的图像。
实验
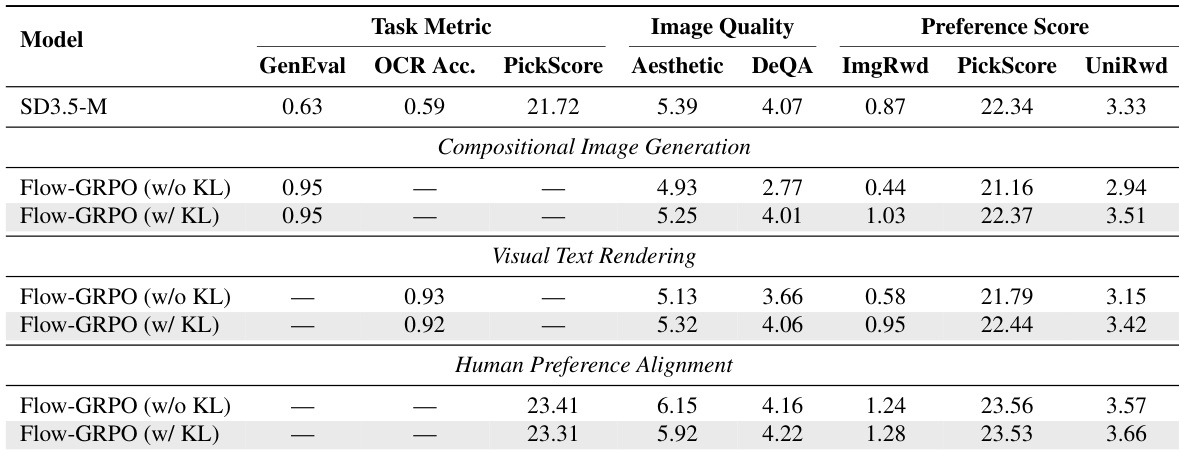
- GenEval上的组合图像生成:Flow-GRPO在计数、颜色、属性绑定和空间关系方面均优于GPT-4o及所有基线模型,同时在DrawBench上保持高图像质量与多样性。
- 视觉文本渲染:Flow-GRPO显著提升文本保真度,在OCR任务中实现高准确率,且未降低图像质量或DrawBench偏好得分。
- 人类偏好对齐:Flow-GRPO在PickScore上超越SFT、Flow-DPO、ReFL和ORW,训练稳定,图像质量无下降,且通过KL正则化防止多样性崩溃。
- 核心结果:在GenEval上,Flow-GRPO超越GPT-4o与先前方法;在视觉文本渲染上,实现高文本保真度;在人类偏好上,持续提升PickScore,同时在各基准测试中保持图像质量与多样性。
作者使用Flow-GRPO改进文本到图像模型在组合图像生成上的表现,GenEval得分为0.95,超越GPT-4o的0.84。结果表明,Flow-GRPO在DrawBench上维持或提升图像质量与偏好得分,美学、DeQA及偏好指标无显著下降。
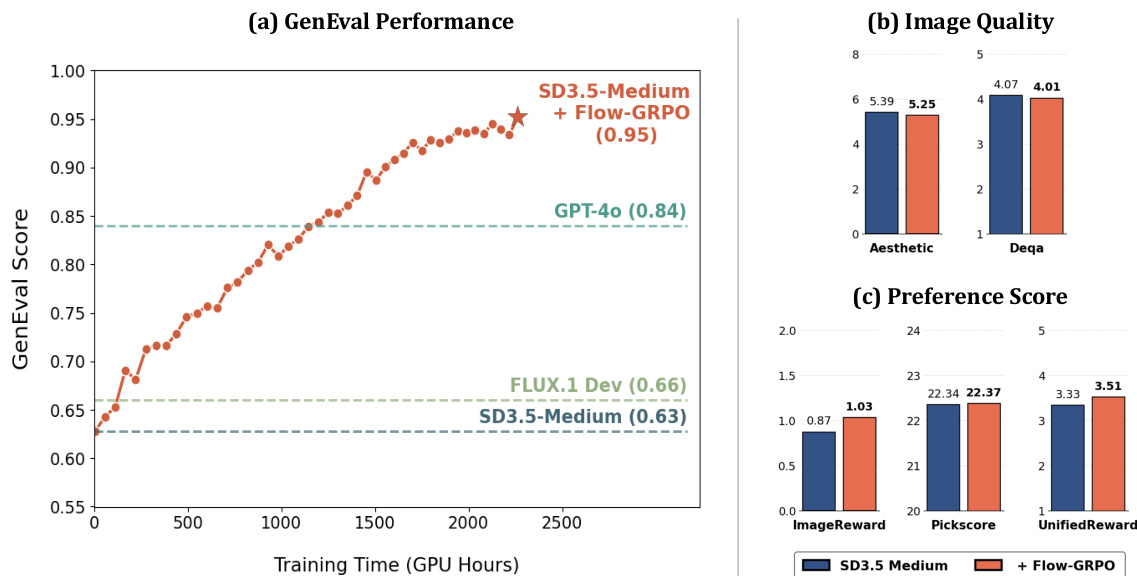
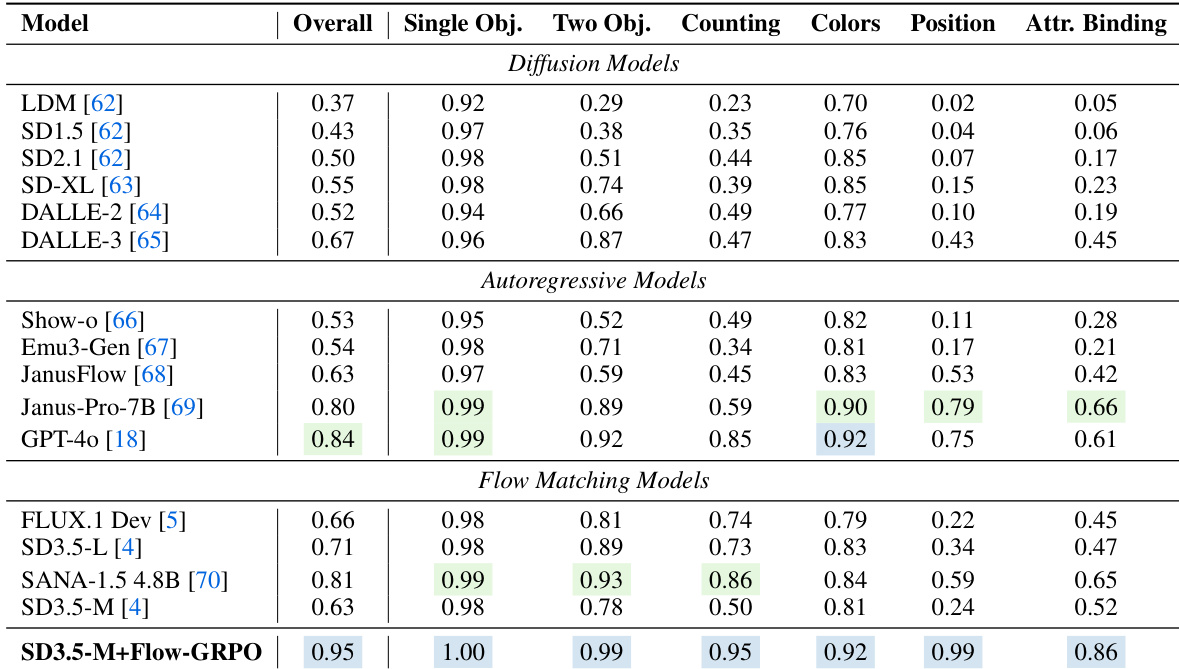
作者使用Flow-GRPO增强流匹配模型,在GenEval基准测试的所有任务类别(包括物体计数、颜色识别与属性绑定)上均达到最先进水平。结果表明,SD3.5-M+Flow-GRPO优于所有基线模型,尤其在单物体与双物体任务中表现突出,同时保持高整体准确率,并超越此前的扩散模型与自回归模型。
作者使用Flow-GRPO微调FLUX.1-Dev模型,显著提升其在多个图像质量与偏好指标上的表现。结果表明,Flow-GRPO提升了模型的美学评分、图像奖励、PickScore与UnifiedReward,同时DeQA保持或略有提升,表明其在不牺牲图像质量的前提下,更好地对齐人类偏好。

作者使用Flow-GRPO增强SD3.5-M模型,在多个GenEval任务上取得显著提升,尤其在颜色、形状与空间推理方面表现突出,同时在其他指标上保持竞争力。结果表明,SD3.5-M+Flow-GRPO优于Janus-Pro-7B与EMU3等基线模型,在颜色准确率、形状识别及2D/3D空间理解方面均有显著提升。

作者使用Flow-GRPO在三个任务上改进文本到图像模型,结果表明引入KL正则化可在保持图像质量与多样性的同时,实现更高的任务特定性能。结果表明,带KL正则化的Flow-GRPO在所有任务上均优于基线模型及无KL版本,GenEval、OCR准确率与偏好得分均有提升,同时图像质量指标得以维持或增强。