Command Palette
Search for a command to run...
HunyuanCustom:一种面向定制化视频生成的多模态驱动架构
HunyuanCustom:一种面向定制化视频生成的多模态驱动架构
Teng Hu Zhentao Yu Zhengguang Zhou Sen Liang Yuan Zhou Qin Lin Qinglin Lu
摘要
定制化视频生成旨在根据灵活的用户定义条件生成包含特定主体的视频,然而现有方法在主体身份一致性以及输入模态的多样性方面仍面临挑战。本文提出 HunyuanCustom,一种多模态定制化视频生成框架,该框架在保障主体一致性的同时,支持图像、音频、视频与文本等多种条件输入。基于 HunyuanVideo 构建,我们的模型首先通过引入基于 LLaVA 的文本-图像融合模块,增强多模态理解能力,并结合一种图像ID增强模块,利用帧间时序拼接机制强化跨帧的身份特征表达,以解决图像-文本条件下的生成任务。为进一步实现音频与视频条件驱动的生成,我们进一步设计了模态特定的条件注入机制:提出 AudioNet 模块,通过空间交叉注意力实现层级对齐;同时构建视频驱动的注入模块,借助基于分块(patchify)的特征对齐网络,将压缩后的潜在视频条件信息有效融合。在单主体与多主体场景下的大量实验表明,HunyuanCustom 在身份一致性、视觉真实感以及文本-视频对齐性能方面,显著优于当前最先进的开源与闭源方法。此外,我们在下游任务中验证了该模型的鲁棒性,涵盖音频驱动与视频驱动的定制化视频生成任务。实验结果充分证明,多模态条件输入与身份保持策略在推动可控视频生成技术发展中的有效性。相关代码与模型均已开源,访问地址为:https://hunyuancustom.github.io。
一句话总结
作者提出 HunyuanCustom,这是腾讯 Hunyuan 团队与合作者开发的多模态视频生成框架,通过文本-图像融合模块、基于时间拼接的图像 ID 增强机制以及模态特定的条件注入机制,在文本、图像、音频和视频输入下实现了卓越的主体身份一致性,从而在虚拟人、唱歌虚拟形象和可控性与真实感更强的视频编辑等高级应用中展现出强大能力。
主要贡献
-
HunyuanCustom 解决了在多种用户自定义条件下保持主体一致性的视频生成挑战,克服了现有方法在身份保留和模态灵活性方面的局限性,这些方法通常仅支持图像或文本输入。
-
该框架引入了基于 LLaVA 的文本-图像融合模块,以及利用时间拼接实现图像 ID 增强的模块,以强化跨帧的身份特征,同时提出模态特定的条件注入机制——AudioNet 实现分层音频-视频对齐,基于 patchify 的视频-潜在对齐模块则支持视频驱动的生成。
-
在单主体和多主体场景下的广泛评估表明,HunyuanCustom 在身份一致性、真实感和文本-视频对齐方面均优于当前最先进的开源与闭源模型,且在音频驱动和视频驱动的定制任务中表现出良好的鲁棒性。
引言
作者利用基于扩散的视频生成最新进展,应对主体一致、细粒度视频定制这一长期挑战。尽管先前方法在文本或图像驱动生成方面表现优异,但往往难以在多个主体或模态之间维持身份保真度,尤其是在扩展至音频或视频输入时。许多现有方法依赖实例特定的微调或单模态条件控制,限制了其可扩展性和实时应用能力。作者提出 HunyuanCustom,一个支持文本、图像、音频和视频输入的多模态视频生成框架,能够实现鲁棒且主体一致的视频合成。其核心在于基于 LLaVA 的新型文本-图像融合模块、基于时间拼接的图像 ID 增强模块,以及针对音频和视频的专用条件注入机制。在音频驱动生成中,AudioNet 通过空间交叉注意力实现分层音频-视频对齐;而基于 patchify 与身份解耦的条件模块则确保了有效的视频-潜在特征融合。在单主体和多主体场景下进行评估,HunyuanCustom 在身份一致性、视频质量及多模态对齐方面均优于现有开源与商业模型,展现出在虚拟形象、广告和交互式视频编辑等领域的巨大潜力。
数据集
-
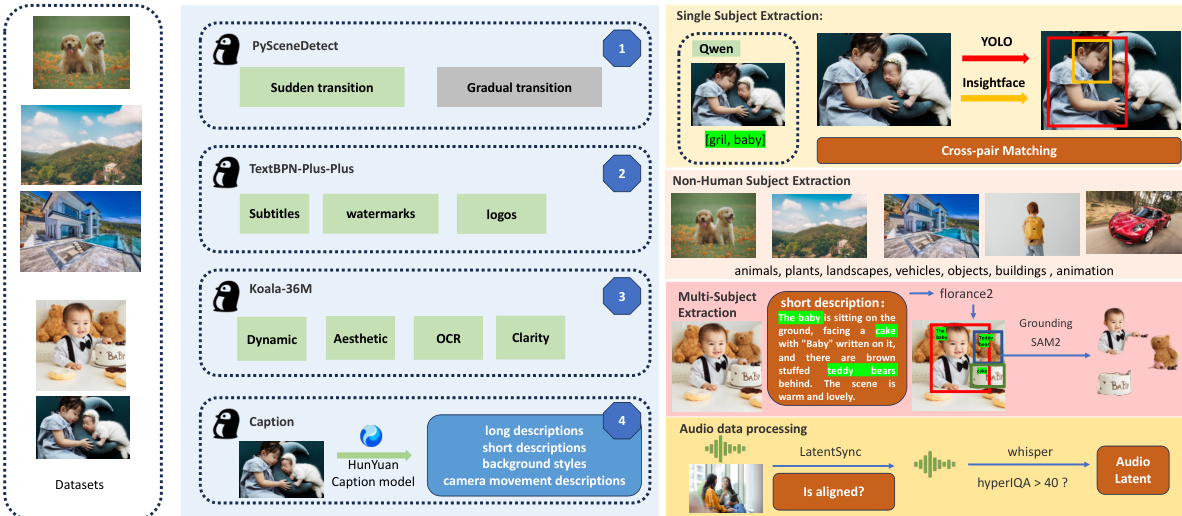
数据集由来自多样化渠道的视频数据构成,包括自采内容和精选的开源数据集(如 OpenHumanvid)。涵盖八大主要领域:人类、动物、植物、景观、车辆、物体、建筑和动漫,确保了广泛的领域覆盖与多样性。
-
数据预处理包括使用 PySceneDetect 将视频分割为单镜头片段,以避免视频内部过渡。通过 textbn-plus-plus 过滤掉包含过多文字、字幕、水印或标志的片段。视频被裁剪并缩放,使短边标准化为 512 或 720 像素,最大长度为 5 秒(129 帧)。最后一步使用 koala-36M 模型,结合自定义阈值 0.06,对美学质量、运动幅度和场景亮度进行筛选,弥补现有工具的不足。
-
主体提取根据主体类型采用不同方法:
- 对于人类,Qwen7B 逐帧标注主体,使用 Union-Find 聚类算法识别出现频率最高的主体 ID(最少 50 帧)。YOLO11X 和 InsightFace 用于人体与人脸检测,若人脸边界框占据人体框面积不足 50%,则舍弃该框。
- 对于非人类主体,QwenVL 提取关键词,GroundingSAM2 生成掩码与边界框;小于视频尺寸 0.3 倍的边界框被舍弃。主体被分类为八类之一,通过平衡采样确保分布均匀。
- 对于多主体视频,Florence2 从视频字幕中提取边界框,随后由 GroundingSAM2 生成掩码。聚类算法移除缺失任一主体的帧,前 5 秒用于训练,接下来的 15 秒保留用于分割。
-
视频分辨率标准化通过计算所有主要主体的联合边界框实现,确保裁剪区域保留至少 70% 的该区域面积。数据集支持 1:1、3:4 和 9:16 三种宽高比,以支持多分辨率输出。
-
视频标注由 HunYuan 自主开发的结构化标注模型生成,提供包括长描述、短描述、背景风格和摄像机运动细节在内的详细元数据。这些标注丰富了视频字幕,提升了模型鲁棒性。
-
训练期间应用掩码数据增强以防止过拟合。如掩码膨胀和转换为边界框等技术可软化掩码边界,提升在编辑形状或特征各异对象(如替换有耳或无耳的玩偶)时的泛化能力。
-
音频数据通过 LatentSync 处理以评估音视频同步性,置信度低于 3 的片段被丢弃,并将音频对齐至视频零偏移。HyperIQA 分数低于 40 的音频被剔除以保证高质量。Whisper 用于提取音频特征以供模型训练。
方法
作者以 HunyuanVideo 框架为基础,构建 HunyuanCustom,这是一个多模态定制化视频生成模型,旨在在多种输入条件下保持主体身份一致性。整体架构设计支持四大核心任务:文本驱动、图像驱动、音频驱动和视频驱动的视频生成,均以主体一致性为核心。如图所示,该框架为每种模态集成独立模块,实现图像、音频和视频条件的解耦控制,同时保留身份信息。
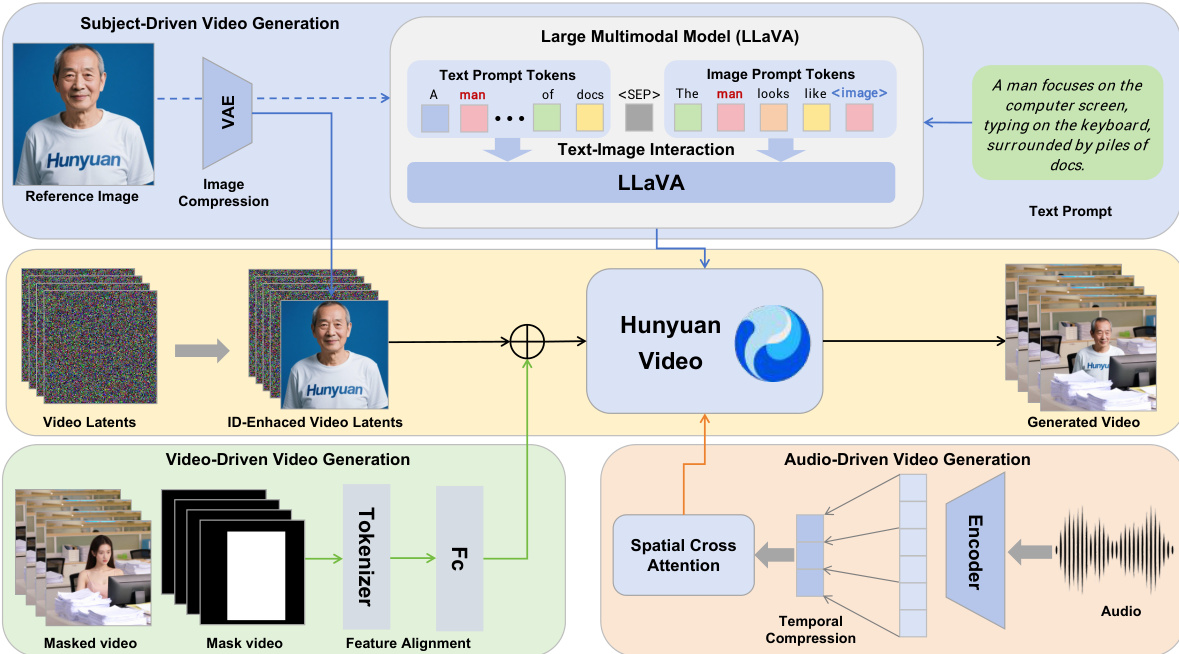
在图像驱动定制的核心是基于 LLaVA 的文本-图像融合模块,该模块促进视觉与文本输入之间的交互。该模块通过构建模板处理文本提示和输入图像,将图像标记嵌入文本中或置于文本之后,并使用特殊分隔符防止图像特征主导文本理解。图像标记被替换为 LLaVA 提取的 24×24 图像隐藏特征,实现视觉与文本信息的联合建模。为增强生成视频中的身份一致性,引入身份增强模块。该模块沿时间维度将参考图像映射至潜在空间后得到的图像潜在特征,与噪声视频潜在特征进行拼接。拼接后的潜在特征沿时间序列分配 3D-RoPE,图像潜在特征置于第 -1 帧位置,以广播身份信息。对图像潜在特征施加空间偏移,防止模型简单复制图像至生成帧。
在多主体定制中,模型扩展单主体方法,将多个条件图像编码至潜在空间,并与视频潜在特征拼接。每个图像被分配唯一的时间索引及对应的 3D-RoPE,以区分不同身份。训练过程采用 Flow Matching 框架,模型预测在目标图像条件下的视频潜在速度。损失函数最小化预测速度与真实速度之间的均方误差,且视频生成模型与 LLaVA 模型均被完全微调,以释放模型全部潜力。
为支持音频驱动的视频定制,作者提出身份解耦的 AudioNet 模块。该模块通过填充和聚合音频帧,将音频特征与压缩后的视频潜在特征对齐。随后使用空间交叉注意力机制,逐帧将音频信息注入视频潜在特征,防止帧间干扰。音频特征经交叉注意力模块处理后,以可学习权重添加至视频潜在特征,以控制音频的影响程度。
在视频驱动的视频定制中,HunyuanCustom 采用高效的视频条件注入策略。条件视频通过预训练的因果 3D-VAE 压缩,并通过特征对齐网络与视频潜在特征对齐。条件特征随后在逐帧基础上与视频潜在特征进行拼接或相加,保留原始特征维度,推理阶段不引入额外计算开销。实验表明,基于相加的方法在保留内容信息和实现条件视频特征与视频潜在特征高效融合方面更为有效。
实验
- 在单主体和多主体视频定制任务上开展全面实验,评估身份保留、文本-视频对齐、时间一致性及动态运动表现。
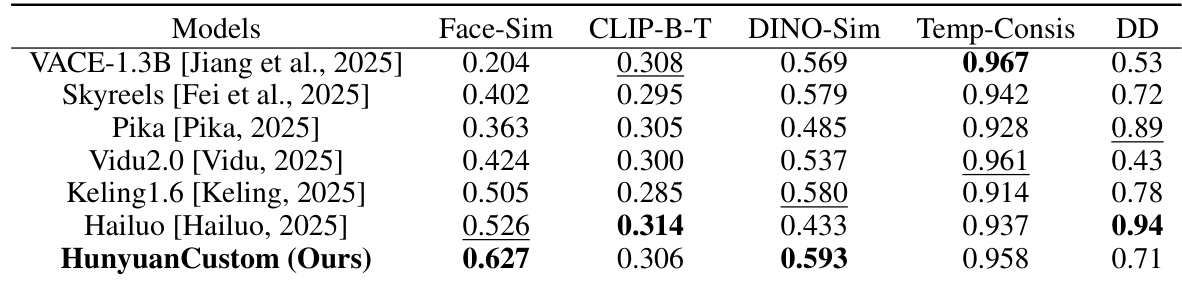
- 在单主体任务中,HunyuanCustom 在身份一致性与主体相似性方面表现最佳,优于包括 Vidu 2.0、Keling 1.6、Pika、Hailuo、Skyreels-A2 和 VACE 在内的最先进方法,视频质量与提示遵循性均更优。
- 在多主体任务中,HunyuanCustom 展现出强大的能力,能稳定保持人类与非人类主体的身份,生成高质量且自然互动的视频,支持虚拟人广告等新型应用。
- 在视频驱动定制中,HunyuanCustom 在视频主体替换方面表现卓越,避免了 VACE 和 Keling 中常见的边界伪影与复制粘贴效应,同时确保无缝融合与身份保留。
- 消融实验验证了 LLaVA 在身份特征提取中的必要性,身份增强模块在捕捉细粒度细节方面的有效性,以及时间拼接相较于通道拼接在维持生成质量与身份保真度方面的优越性。
结果表明,HunyuanCustom 在所有对比模型中实现了最高的面部相似度与主体相似度,表明其具备强大的身份保留能力。同时在文本-视频对齐与时间一致性方面表现具有竞争力,且保持高动态程度,在整体视频质量与一致性方面优于大多数基线模型。