Command Palette
Search for a command to run...
MiniCPM-V:手机上的GPT-4V级别多模态大模型(MLLM)
MiniCPM-V:手机上的GPT-4V级别多模态大模型(MLLM)
摘要
近年来,多模态大语言模型(Multimodal Large Language Models, MLLMs)的迅猛发展,从根本上重塑了人工智能研究与产业格局,为迈向下一阶段AI里程碑指明了充满希望的方向。然而,MLLMs在实际应用中仍面临诸多挑战,其中最突出的问题在于其庞大的参数量和高计算需求所带来的高昂运行成本。因此,目前大多数MLLMs仍需部署在高性能云端服务器上,这严重限制了其在移动设备、离线环境、低功耗场景以及注重隐私保护等实际应用中的广泛使用。在本工作中,我们提出MiniCPM-V系列高效多模态大模型,可直接部署于终端设备。通过融合最新的MLLM架构设计、预训练方法与对齐技术,最新版本MiniCPM-Llama3-V 2.5展现出多项显著优势:(1)卓越的综合性能,在OpenCompass平台对11个主流基准的全面评估中,超越GPT-4V-1106、Gemini Pro与Claude 3;(2)强大的光学字符识别(OCR)能力,支持任意长宽比下高达180万像素的高分辨率图像理解;(3)行为可靠,幻觉率极低,具备更高的可信度;(4)支持30多种语言的多语言处理能力;(5)可在智能手机等移动设备上实现高效部署。尤为重要的是,MiniCPM-V可被视为一种具有代表性的趋势:实现具备实用级性能(如GPT-4V水平)的模型,其参数规模正迅速缩小,同时终端侧计算能力正飞速提升。这一双重趋势共同表明,未来在终端设备上部署达到GPT-4V水平的多模态大模型正变得日益可行,将为现实世界中更广泛的人工智能应用打开新的可能性。
一句话总结
来自MiniCPM-V团队和OpenBMB的研究者提出了MiniCPM-V,一系列高效多模态大语言模型,以显著减小的模型规模实现了GPT-4V级别的性能,支持高分辨率图像理解、低幻觉行为、多语言支持以及移动端部署——代表了向设备端AI发展的关键趋势,并拓展了在隐私敏感和资源受限环境中的实际应用。
主要贡献
- MiniCPM-V解决了在资源受限的终端设备上部署高性能多模态大语言模型(MLLMs)的关键挑战,使移动、离线和隐私敏感场景下的实际应用成为可能,这些场景中基于云端的推理不可行。
- 最新的MiniCPM-Llama3-V 2.5在OpenCompass的11个基准上达到最先进性能,超越GPT-4V-1106、Gemini Pro和Claude 3,得益于优化的架构、训练策略以及支持任意长宽比下高达180万像素的高分辨率图像感知能力。
- 该模型表现出可信行为,幻觉率显著降低,具备强大的OCR能力(包括表格到Markdown的转换),支持30多种语言,能够在移动设备上实现高效可靠的部署,同时顺应了模型规模缩小与终端设备算力提升的总体趋势。
引言
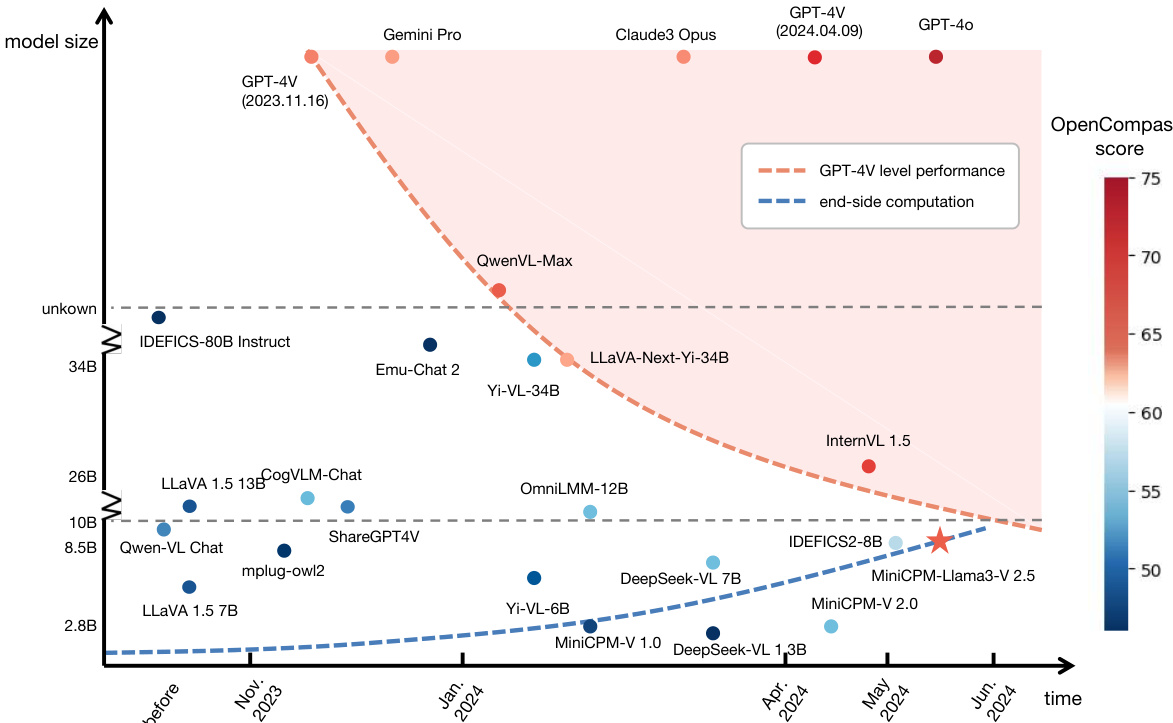
研究者利用多模态大语言模型(MLLMs)的最新进展,应对在智能手机等终端设备上部署高性能模型的关键挑战,这些设备受内存、功耗和处理速度限制。以往工作主要依赖大规模云端MLLMs,这在隐私敏感、离线或能源受限环境中限制了实际应用。尽管轻量化模型取得进展,但在此类设备上实现GPT-4V级别的性能仍因模型规模、推理效率与能力之间的权衡而难以实现。研究者的主要贡献是MiniCPM-V,一系列高效MLLMs,其在OpenCompass上超越GPT-4V、Gemini Pro和Claude 3等模型,同时可部署于手机端。关键创新包括自适应高分辨率图像编码(支持高达180万像素)、基于RLAIF-V的对齐以减少幻觉、通过指令微调实现多语言泛化,以及包括量化和NPU加速在内的全面终端侧优化。该工作还识别出一种类似摩尔定律的趋势:在保持等效性能的前提下,MLLMs模型规模持续减小,这由模型效率提升和终端设备算力上升共同驱动,标志着向强大、设备端多模态AI的转变。
数据集
- 数据集包含来自多个来源的多样化图像-文本对,包括真实场景、产品图像以及合成或增强数据,旨在支持跨语言和视觉复杂性的多模态理解。
- 关键子集包括:
- 一个聚焦韩国料理的子集,包含如拌饭等传统菜肴,图像展示制作过程、食材(如韩式辣酱、蔬菜、海苔)及盛器,数据源自精心挑选的美食摄影。
- 一个交通与基础设施子集,涵盖加油站和卡车停车区,详细描述车辆、遮蔽设施、加油机、标识及环境背景,数据来自真实城市与工业影像。
- 一个多语言评估子集,包含多种语言的图像-文本对,用于评估跨语言性能,包括英语、韩语等,标注反映语言多样性。
- 研究者使用该数据集进行训练,采用混合比例策略,优先选择高质量、多样化且语言丰富的样本;训练集构建兼顾领域覆盖,避免对特定视觉或语言模式的过拟合。
- 图像经过预处理,包括长宽比归一化、分辨率缩放和裁剪,以聚焦显著区域,尤其适用于极端长宽比或杂乱场景。
- 元数据包含语言标签、物体标注和场景描述,定性评估中将幻觉或错误输出以红色明确标记,以突出模型局限性。
- 数据集支持细粒度细节描述和场景文本理解任务,强调准确的视觉定位与跨语言一致性。
方法
研究者采用模块化架构设计MiniCPM-V,以在真实部署中平衡性能与效率。整体框架包含三个主要组件:视觉编码器、压缩层和大语言模型(LLM)。输入图像首先由视觉编码器处理,提取视觉特征。这些特征随后通过压缩层以减少视觉标记数量,最后将压缩后的视觉标记与文本输入结合,输入LLM进行条件文本生成。这种模块化设计使得高分辨率图像的高效处理成为可能,同时保持强大的多模态能力。
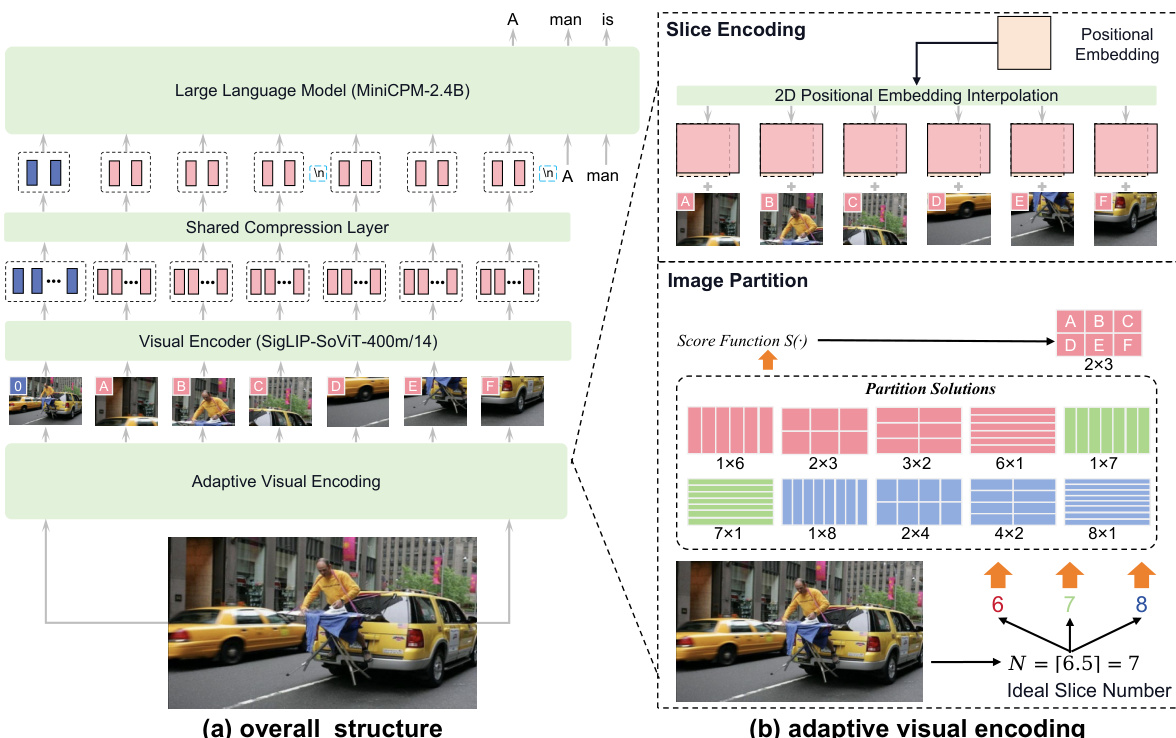
视觉编码过程是一项关键创新,旨在有效处理任意长宽比的高分辨率图像。该方法从图像分块开始,将输入图像划分为网格状切片。切片数量由输入图像面积与视觉编码器预训练面积之比决定,计算公式为 N=⌈Wv×HvWI×HI⌉。为找到最优分块方式,设计一个评分函数 S(m,n),用于评估行数与列数组合的潜在方案,该函数衡量切片长宽比与预训练长宽比的偏差。选择得分最高的分块方案。此过程确保每个切片均适配视觉编码器的预训练设置。分块完成后,对每个切片进行编码。切片按比例缩放以匹配预训练面积,视觉编码器的位置嵌入通过插值适应新切片尺寸。这一步对保持视觉特征完整性至关重要。研究者还额外引入原始图像作为一块切片,以提供整体上下文。
视觉编码完成后,模型采用标记压缩模块来管理编码器生成的大量视觉标记。该模块使用单层交叉注意力机制,固定数量的查询进行压缩。对于MiniCPM-V 1.0和2.0,视觉标记被压缩为64个查询;MiniCPM-Llama3-V 2.5则使用96个标记。该压缩显著降低计算负载与内存占用,使模型更高效,适合终端设备部署。为保留空间信息,引入空间结构:每个切片的标记用特殊标记 <slice> 和 </slice> 包裹,不同行的切片之间用换行标记 \n 分隔。
MiniCPM-V的训练过程分为三个阶段,以确保鲁棒且高效的训练。第一阶段为预训练,分为三个子阶段。阶段一通过冻结视觉编码器和LLM,仅训练压缩层以进行热身。阶段二将视觉编码器输入分辨率从224×224提升至448×448,训练整个视觉编码器。阶段三进一步使用自适应视觉编码策略训练视觉编码器和压缩层,以处理任意长宽比的高分辨率输入。该阶段还引入OCR数据以增强模型OCR能力。为提升数据质量,使用标题重写模型修正低质量标题。采用数据打包技术管理样本长度差异,提升内存效率与计算速度。
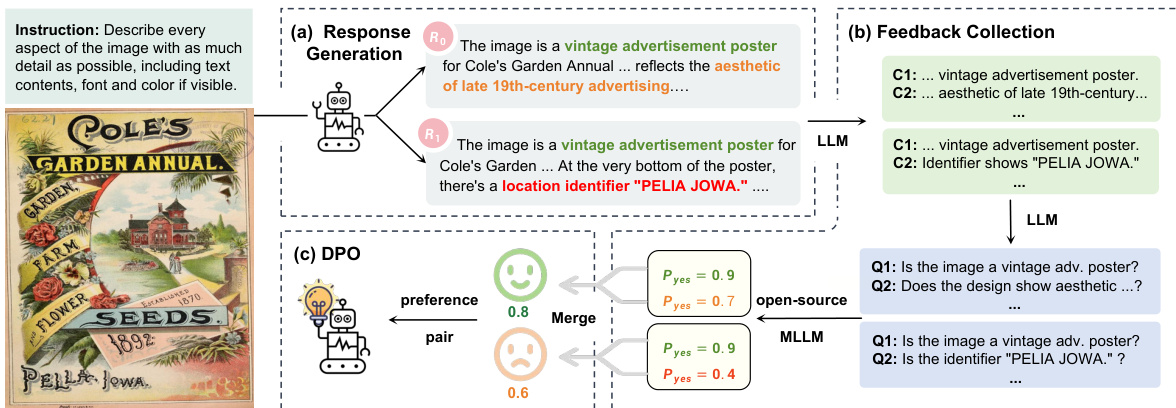
第二阶段为监督微调(SFT),模型在高质量人工标注数据集上训练,以学习交互能力。SFT数据分为两部分:第一部分聚焦基础识别,第二部分增强模型生成详细响应和遵循指令的能力。最终阶段为RLAIF-V,采用分而治之策略以减少幻觉。该过程包括生成多个响应、收集其正确性反馈,并使用DPO(直接偏好优化)基于偏好数据集优化模型。这种多阶段训练策略确保模型兼具强大性能与可靠性。
实验
- 终端侧部署实验验证了在移动和边缘设备上运行MiniCPM-Llama3-V 2.5的可行性,通过量化与框架优化实现。
- 使用GGML框架中的Q4_K_M 4位量化进行基础实践,内存使用从16–17G降至约5G,实现移动端部署。
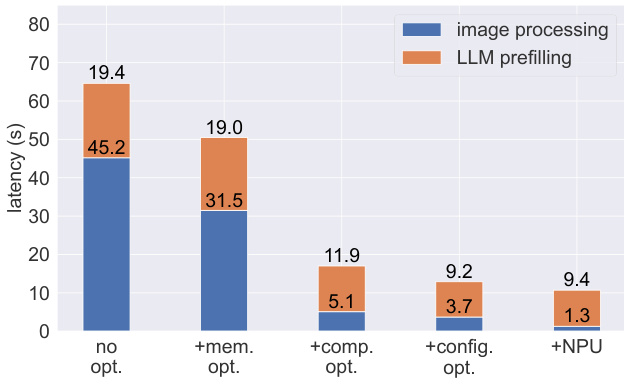
- 高级实践包括内存使用优化、编译优化、配置优化和NPU加速,显著提升性能:编码延迟从64.2秒降至17.0秒,解码吞吐量在小米14 Pro上从1.3提升至8.2 tokens/s。
- NPU加速将视觉编码时间从3.7秒降至1.3秒,在小米14 Pro上实现与Mac M1相当的性能。
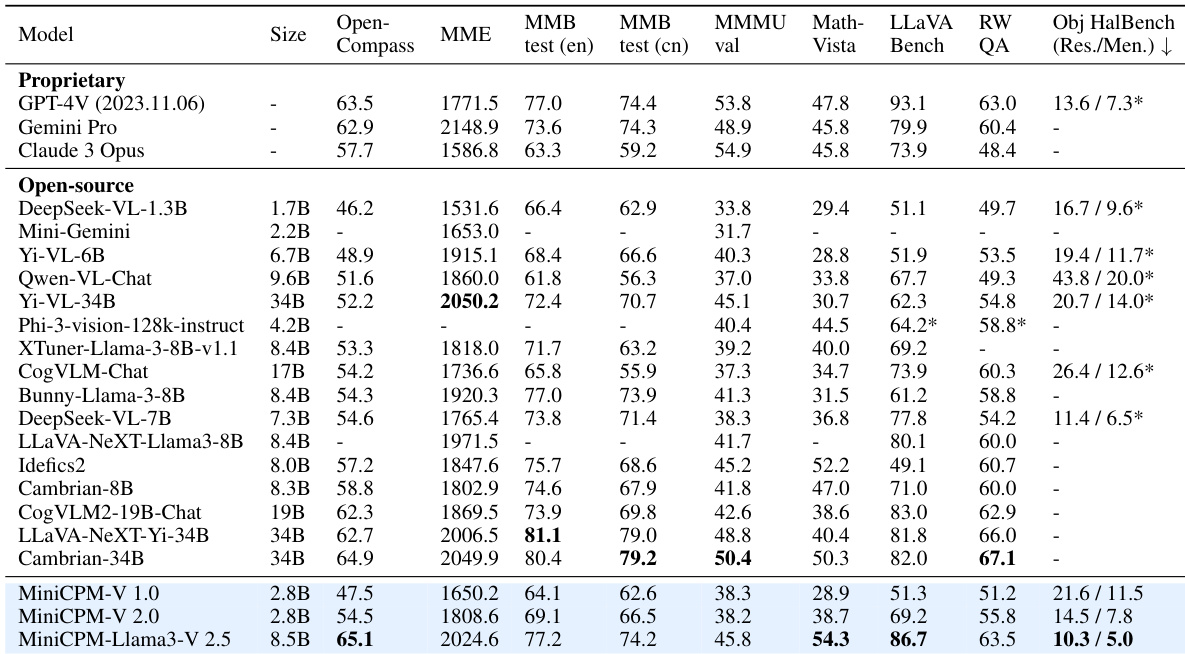
- 在OpenCompass基准上,MiniCPM-Llama3-V 2.5比Idefics2-8B等强开源模型高出7.9分,超越Cambrian-34B和LLaVA-NeXT-Yi-34B等更大模型,且在参数显著更少的情况下,性能优于GPT-4V-1106和Gemini Pro等专有模型。
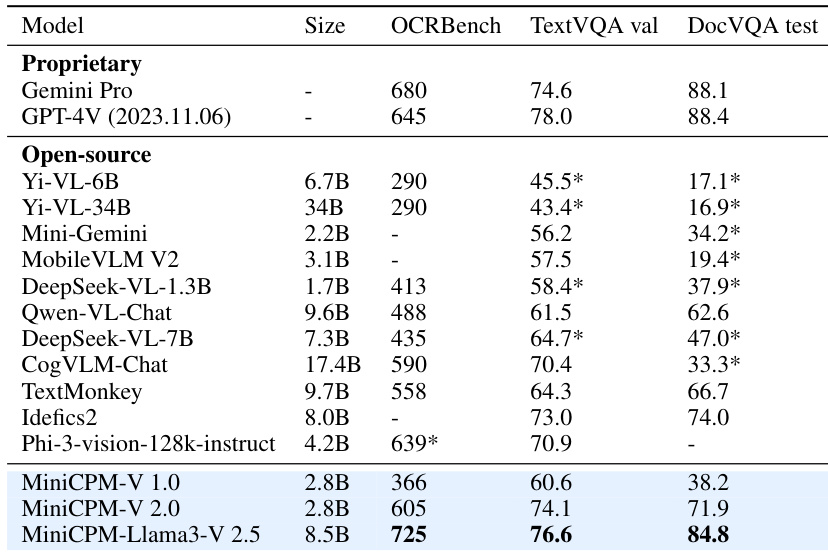
- 在OCR基准(OCR-Bench、TextVQA、DocVQA)上,MiniCPM-Llama3-V 2.5优于1.7B–34B的开源模型,并与GPT-4V-1106和Gemini Pro等专有模型持平。
- 模型在30多种语言上实现多语言多模态能力,在多语言LLaVA Bench上超越Yi-VL-34B和Phi-3-Vision-128k-instruct。
- 消融实验确认,RLAIF-V在不牺牲性能的前提下降低幻觉率,平均提升OpenCompass得分0.6分。
- 使用少于0.5%的SFT数据实现多语言泛化,多语言性能提升超过25分,表明极高的数据效率。
- 案例研究展示了强大的OCR能力、对高分辨率极端长宽比输入的处理能力,以及比GPT-4V更少幻觉的可信行为。
研究者利用MiniCPM-V 2.5在多模态基准上实现强劲性能,同时保持高效,超越更大规模的开源模型,并在通用能力与OCR任务上接近或超越GPT-4V和Gemini Pro等专有模型。模型的有效性得益于RLAIF-V减少幻觉和多语言泛化等技术,使其在多种语言和真实应用场景中表现稳健。

研究者将MiniCPM-V 2.5与其它开源及专有模型在OCR和文本理解基准上进行对比,结果显示MiniCPM-Llama3-V 2.5在OCR-Bench、TextVQA和DocVQA上取得最高分,优于Yi-VL-34B和GPT-4V等模型。结果表明,尽管模型规模较小,MiniCPM-V 2.5仍具备强大的OCR与多模态理解能力,在多个基准上表现具有竞争力。
研究者使用MiniCPM-Llama3-V 2.5在通用多模态基准上实现最先进性能,超越强开源模型,并在参数显著更少的情况下,接近或超过GPT-4V和Gemini Pro等专有模型。结果表明,MiniCPM-V 2.5在性能与效率之间取得良好平衡,具备强大的OCR能力、多语言支持和低幻觉率,适用于真实世界应用。
研究者通过消融实验评估RLAIF-V对MiniCPM-Llama3-V 2.5的影响,结果显示引入RLAIF-V在多个基准上提升性能的同时降低幻觉率。结果表明,采用RLAIF-V的模型在OpenCompass、MME、MMB dev、MMMU、Math-Vista、LLaVA Bench和Object HalBench上的得分均高于未使用RLAIF-V的版本。

研究者采用一系列优化技术降低MiniCPM-Llama3-V 2.5在终端设备上的延迟,结果显示内存使用优化将图像处理时间从45.2秒降至31.5秒,进一步结合编译、配置和NPU加速,总延迟逐步降低至1.3秒。结果表明,这些技术的组合使模型在移动设备上实现高效推理,最终NPU加速配置的解码吞吐量达8.2 tokens/s,超过典型人类阅读速度。