Command Palette
Search for a command to run...
覆盖 40+主流模型及数据集,上海交大团队发布一站式蛋白质工程设计平台 VenusFactory

随着人工智能计算和数据驱动方法的快速发展,蛋白质工程正在迈向 AI 辅助设计阶段。研究人员比以往任何时候都更需要全面、高质量的蛋白质数据集,更强大、更具影响力的蛋白质人工智能模型,以及更高效、标准化的分析平台,以便在海量生物数据中精准挖掘有价值的信息,加速新蛋白的设计与优化,推动生物医药、合成生物学等领域的创新突破。
在此背景下,越来越多的生命科学从业者希望了解 AI,使用 AI 技术来帮助蛋白质工程的设计。然而,无论是 David Baker 的重头设计开源方案,还是 Meta 的 ESM 系列大模型,在使用上都存在诸多难点,例如 AI 计算框架逻辑复杂、代码量大、需要极强的计算机编程基础等等。换言之,对于生物研究人员乃至非资深计算机从业者而言,仍需面对相当高的使用门槛。介于此,用户友好的低代码应用逐渐成为现代开源工具使用的主流趋势,其能够帮助研究人员摆脱复杂的模型配置与代码实现,让计算机科学家和生物学家都能以更加便捷的方法调用或训练深度学习模型,专注于科学研究本身。
为推动人工智能在蛋白质工程领域的应用与发展,中国上海交通大学洪亮教授课题组开发了 VenusFactory——一个专为蛋白质工程量身打造的一站式开放平台。研究人员可以通过界面交互或命令行,轻松实现繁琐的数据检索、模型训练、任务评测、模型部署等功能。该平台通过无代码化、流程化设计,将过去复杂的人工智能工程化操作简化为指尖级的轻量操作,让研究人员无需编写复杂代码,即可在本地启动 web 服务轻松调用超 40 个前沿的蛋白质深度学习模型,实现私有数据隐私保护,大幅降低智能科学研究的门槛,加速人工智能在生命科学领域的深入应用。
代码与数据开源在:https://github.com/ai4protein/VenusFactory
目前,HyperAI 网站的教程版块已上线了「VenusFactory 蛋白质工程设计平台」,详细使用教程已附在本文结尾处,感兴趣的读者可以通过下方链接体验该平台:
VenusFactory:打破蛋白质 AI 应用壁垒的统一平台
蛋白质数据高度分散,VenusFactory 直达生物数据源头 AI 蛋白质研究高度依赖于大规模生物数据,而标注数据分布在多个主流的公开数据库,科学家往往需要在多个数据库之间切换,手动下载数据,并编写脚本进行格式转换,导致时间和精力浪费于非实际的研究工作。而 VenusFactory 则是直接连接主流公开数据库,如 RCSB PDB 、 UniProt 、 InterPro 等,多线程高速下载极大提升数据检索的效率:
- 蛋白质序列、三维结构、功能注释一站式获取,全面整合生物信息。
- 标准化格式输出,避免数据兼容问题,助力 AI 直接训练。
- 多线程下载机制,大幅提升数据获取速度,让科学家聚焦研究本身。
蛋白质 AI 任务评测体系不统一,VenusFactory 覆盖五大核心任务 目前,蛋白质 AI 模型评测体系缺乏现成的权威基准数据,大部分研究仍然聚焦于个别任务的优化,研究人员在选择方案时,往往需要额外花费大量时间进行实验比对。 VenusFactory 则是集成了超 40 个前沿蛋白质工程评测数据集,涵盖五大核心任务:
- 蛋白质功能预测:预测蛋白质的功能标签,助力新酶、新靶点发现。
- 蛋白质亚细胞定位预测:预测蛋白质在细胞中的定位,助力疾病诊断。
- 蛋白质溶解度评估:通过溶解度预判断提高湿实验效率。
- 蛋白质突变影响分析:探索基因突变的潜在影响,推进精准医疗。
- 其他预测任务:如金属离子结合、蛋白排序信号预测、最适温度预测等。
借助这些基准数据集和评测结果,用户可以轻松比较不同模型的性能,选择和优化方案。同时,VenusFactory 也提供了全部数据集的下载功能,用户可以一键获取相应的蛋白质序列、结构、标签等信息。
现有蛋白质 AI 计算工具使用门槛高,非计算背景研究人员难以使用 当前的蛋白质 AI 模型的使用往往需要较强的编程能力和深度学习知识,对于大多数生物学家而言,训练、微调和应用 AI 模型仍然是一项高门槛任务。 VenusFactory 集成了超 40 个全球前沿的蛋白质语言模型 (PLMs),涵盖了全面的 AI 大模型解决方案,如 Venus 系列 (ProSST 、 Pro-Prime 、 PETA 等) 、 ESM 系列 (ESM2 、 ESM1b 等) 、 Ankh 系列 (Base 、 Large) 和 ProtTrans 系列 (ProtBert 、 ProtT5) 等。
- 预训练模型生态:直接调用开源 PLM,无需从零训练,节省计算资源。
- 高性能微调:支持 LoRA 、 SES-Adapter 等前沿方法,让模型适应特定生物任务。
- 多任务支持:无论是蛋白质溶解度预测,还是突变体性质预测,都能轻松上手。
- 命令行模式:适合计算机科学家,可灵活调整参数、实现深度优化。
- 无代码 web 界面:适合生物学家,简单点击即可运行 AI 任务,无需编程基础!
VenusFactory 针对这些核心挑战,构建了一站式 AI 赋能蛋白质工程的平台,提供从数据获取、任务评测到模型微调的完整解决方案,让生物学家和计算科学家都能高效推进研究。
开源 &社区共建,推动科学创新
科学研究的未来在于开放共享。 VenusFactory 采用 Apache 2.0 许可证,所有代码、数据集、模型权重均完全开源,用户可以自由下载、修改、优化,并与全球研究者共享最新成果。所有数据、模型、微调代码都托管在 GitHub & Hugging Face,确保全球科学家都能便捷访问、复现实验,并基于 VenusFactory 构建自己的 AI 研究项目。
为了方便读者体验 VenusFactory,HyperAI 网站上线了「VenusFactory 蛋白质工程设计平台」的一键部署教程,以下为详细使用介绍 ↓
教程链接:https://go.hyper.ai/ZqO3h
VenusFactory 蛋白质工程设计平台使用教程
Demo 运行
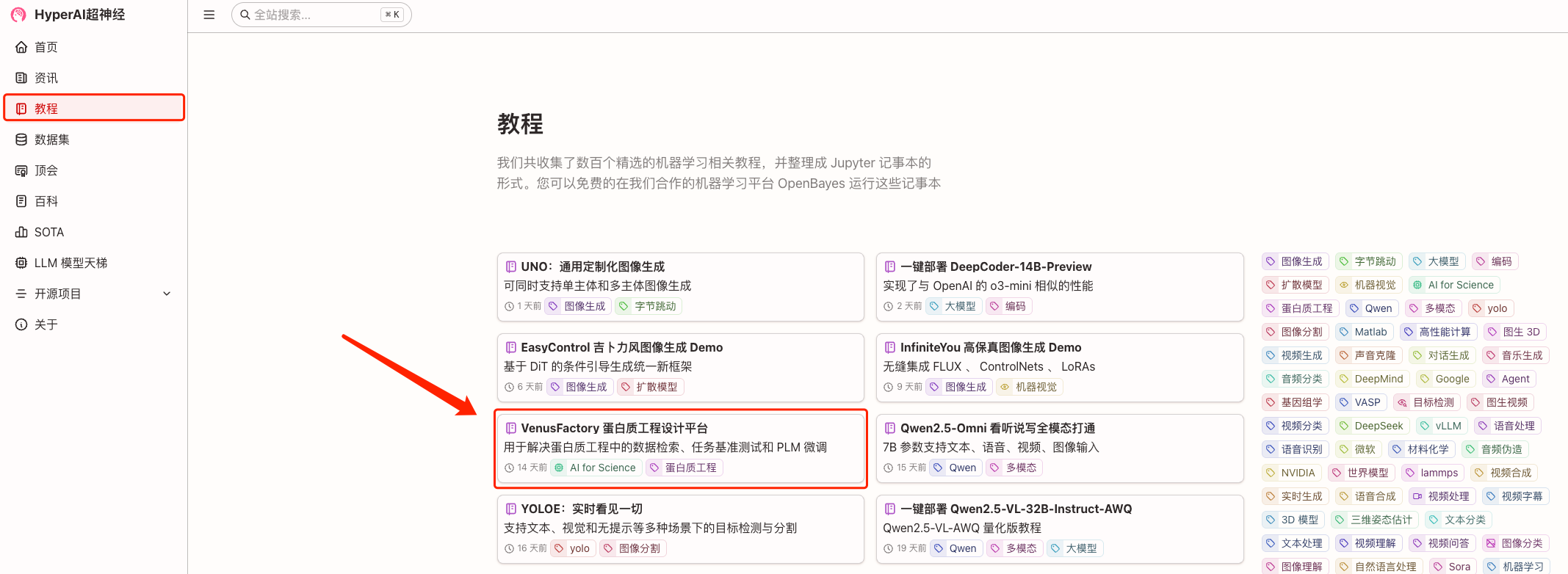
1. 登录 hyper.ai,在「教程」页面,选择「VenusFactory 蛋白质工程设计平台」,点击「在线运行此教程」。
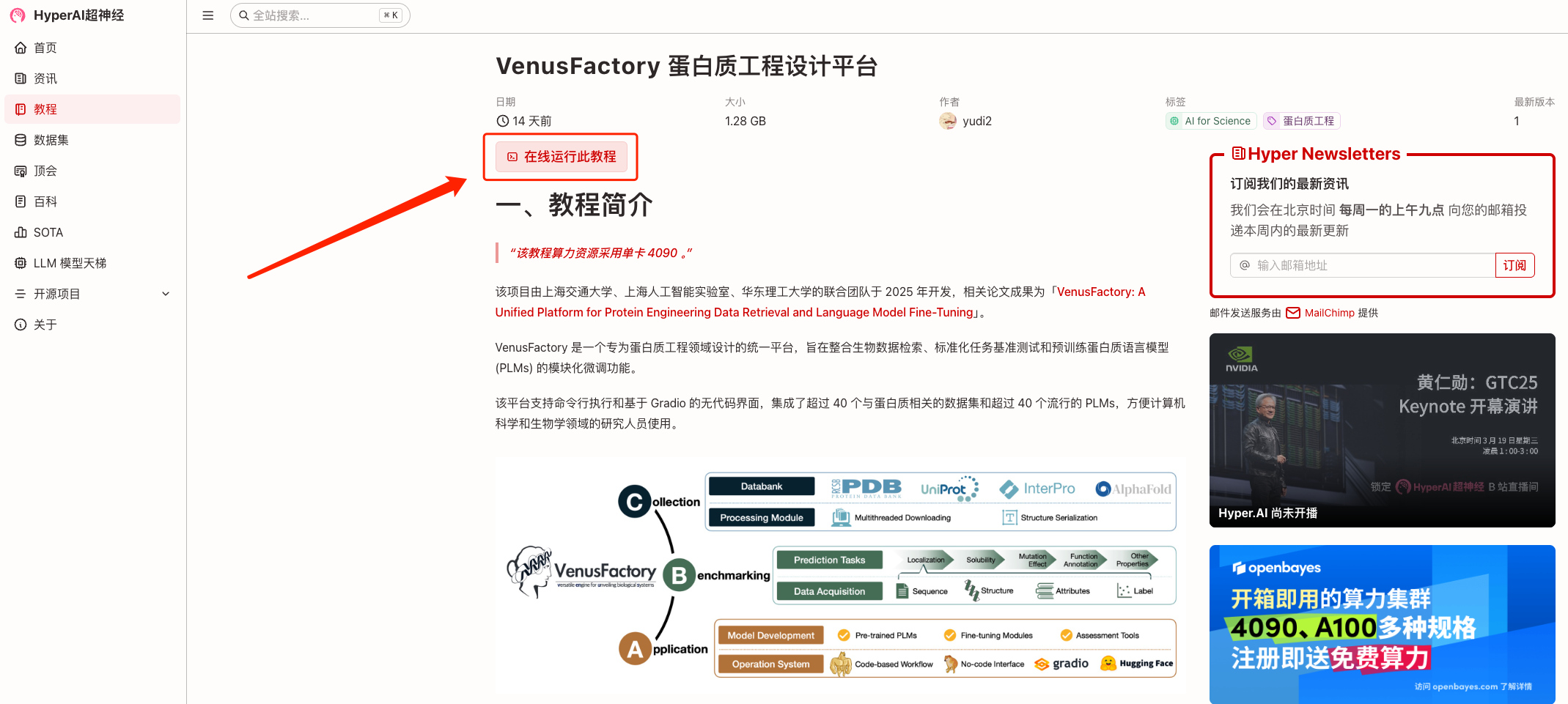
2. 页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
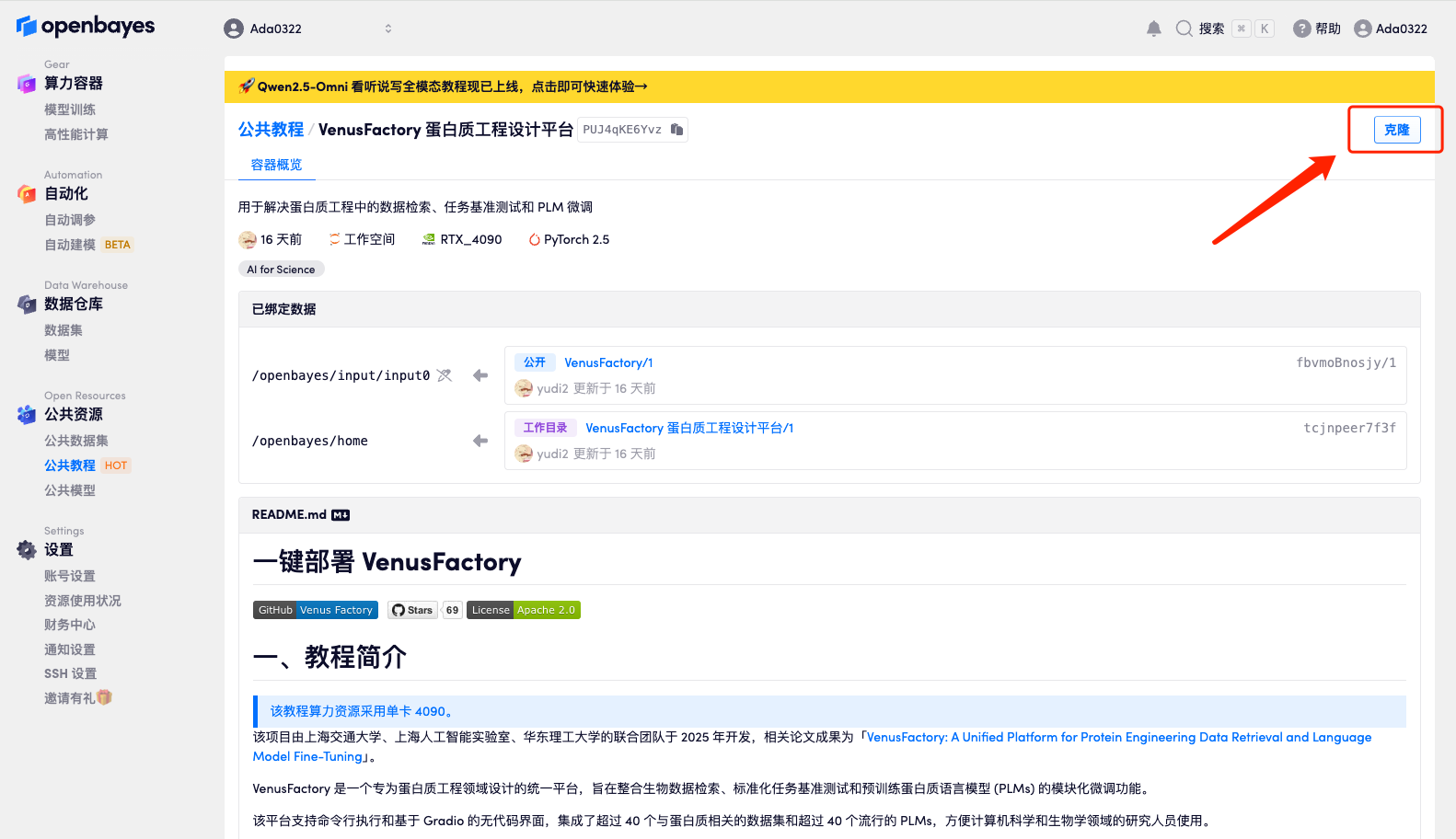
3. 选择「NVIDIA GeForce RTX 4090」以及「PyTorch」镜像,并点击「继续执行」。 OpenBayes 平台提供了 4 种计费方式,大家可以按照需求选择「按量付费」或「包日/周/月」。新用户使用下方邀请链接注册,可获得 4 小时 RTX 4090 + 5 小时 CPU 的免费时长!
HyperAI 超神经专属邀请链接(直接复制到浏览器打开):
https://openbayes.com/console/signup?r=Ada0322_NR0n
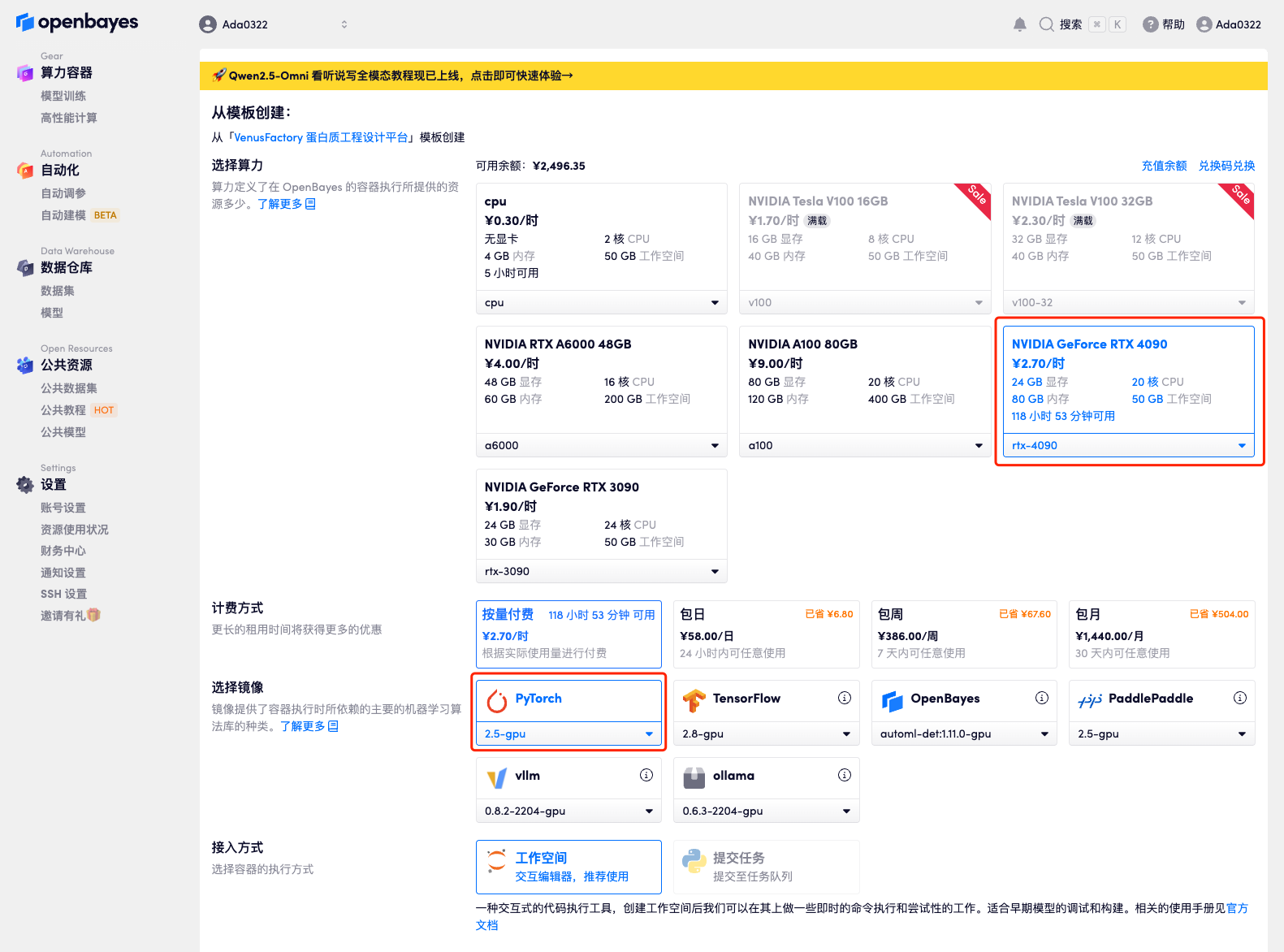
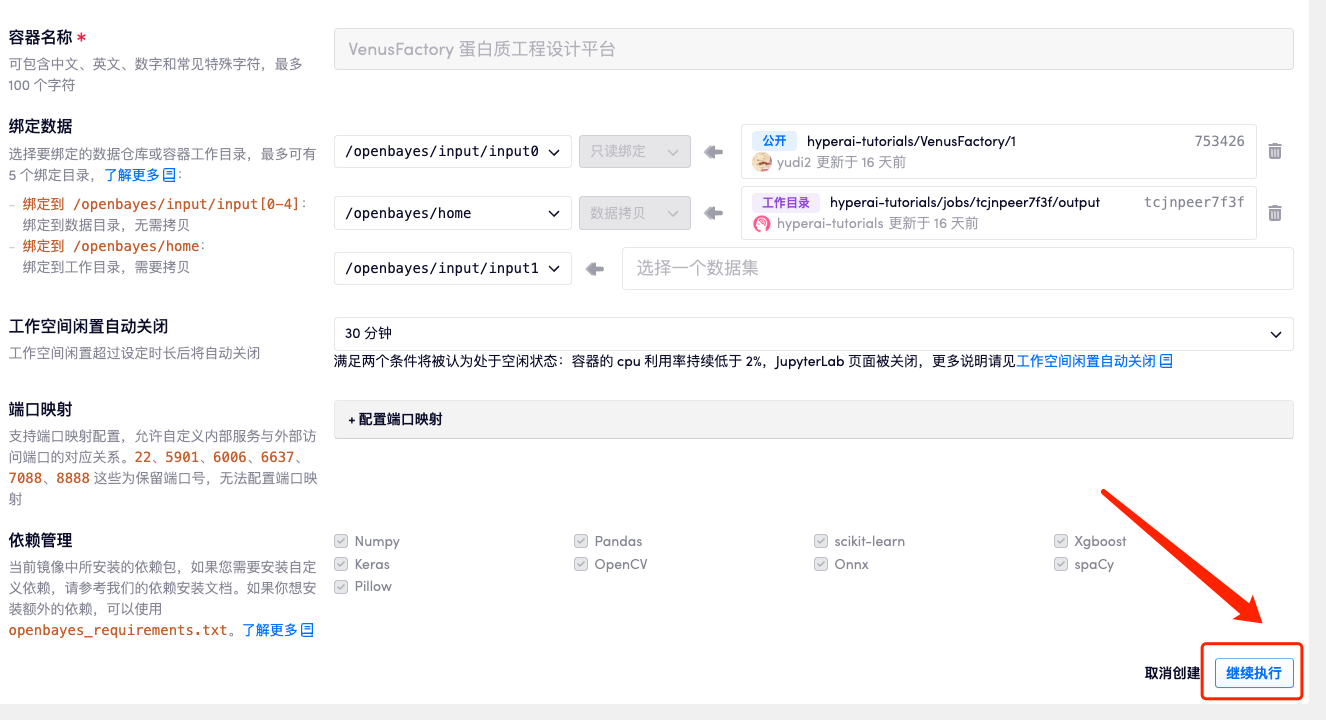
4. 等待分配资源,首次克隆需等待约 2 分钟左右的时间。当状态变为「运行中」后,点击「API 地址」旁边的跳转箭头,即可跳转至 Demo 页面。由于模型较大,需等待约 3 分钟显示 WebUI 界面,否则将显示「Bad Gateway」。请注意,用户需在实名认证后才能使用 API 地址访问功能。
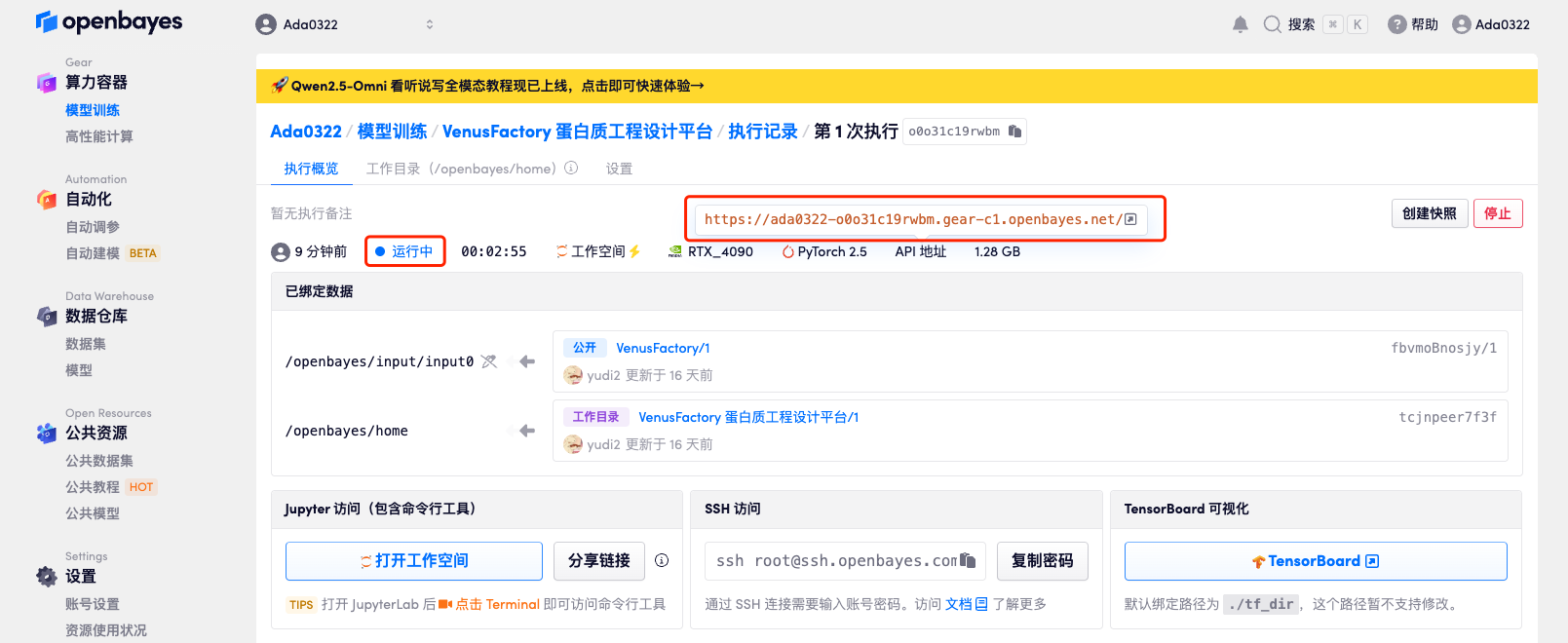
效果展示
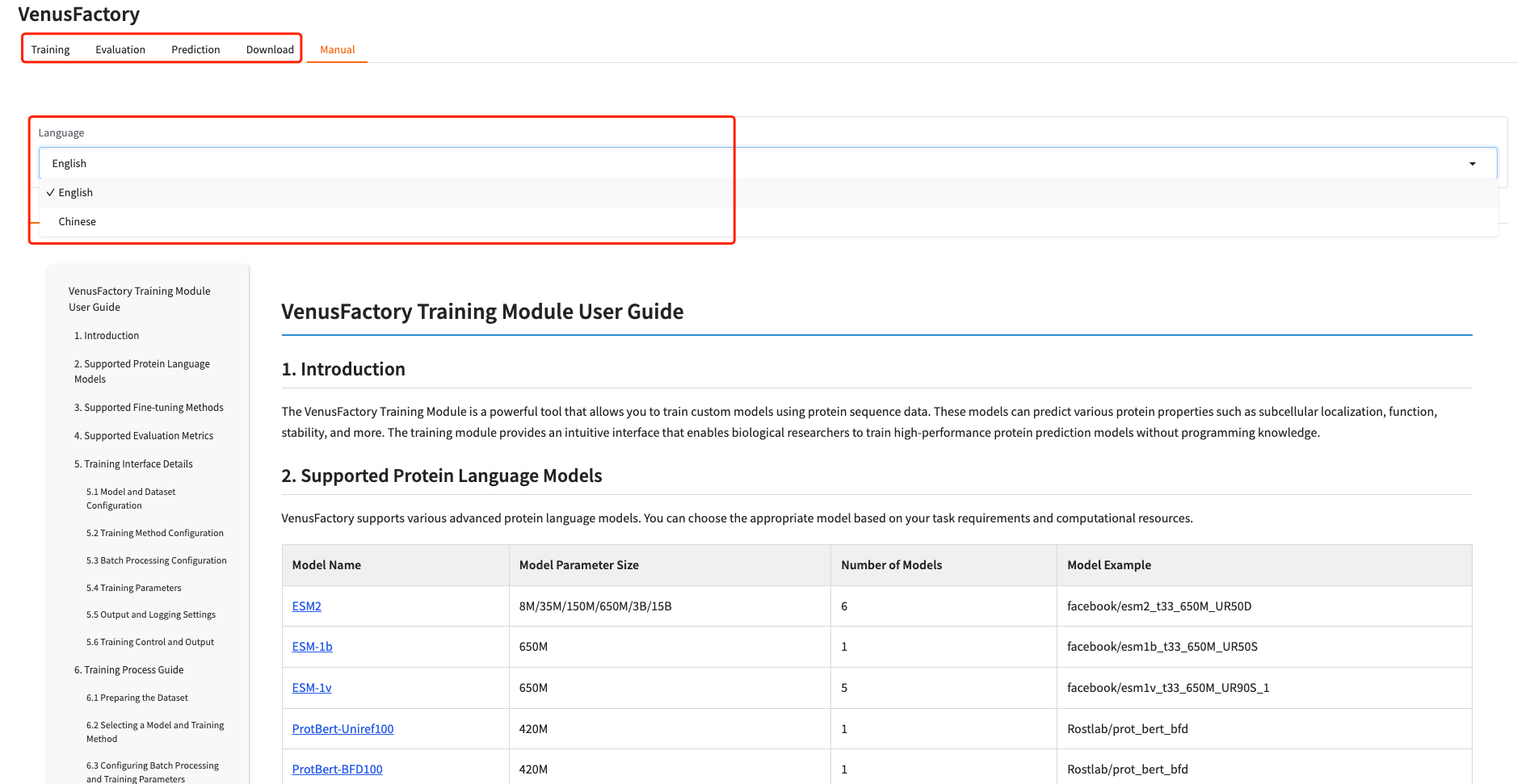
1. 本教程共包含 Training 、 Evaluation 、 Predict 、 Download 四个模块。点击 Manual,选择语言,可以看到每个模块的详细使用指南。
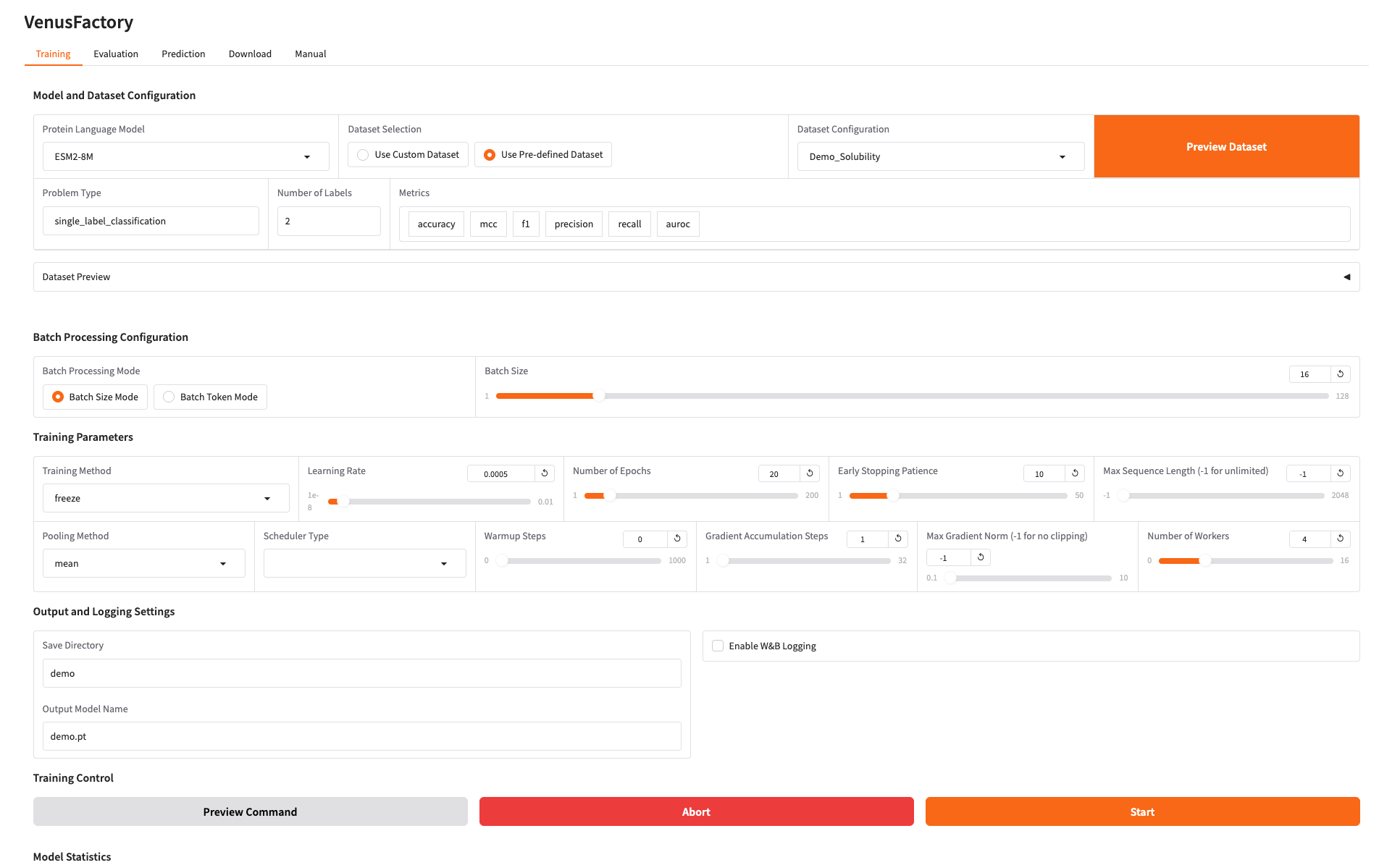
2.Training 模块
点击 Training 模块,在 Protein Language Model 选择想训练的模型,在 Dataset Configuration 配置训练数据
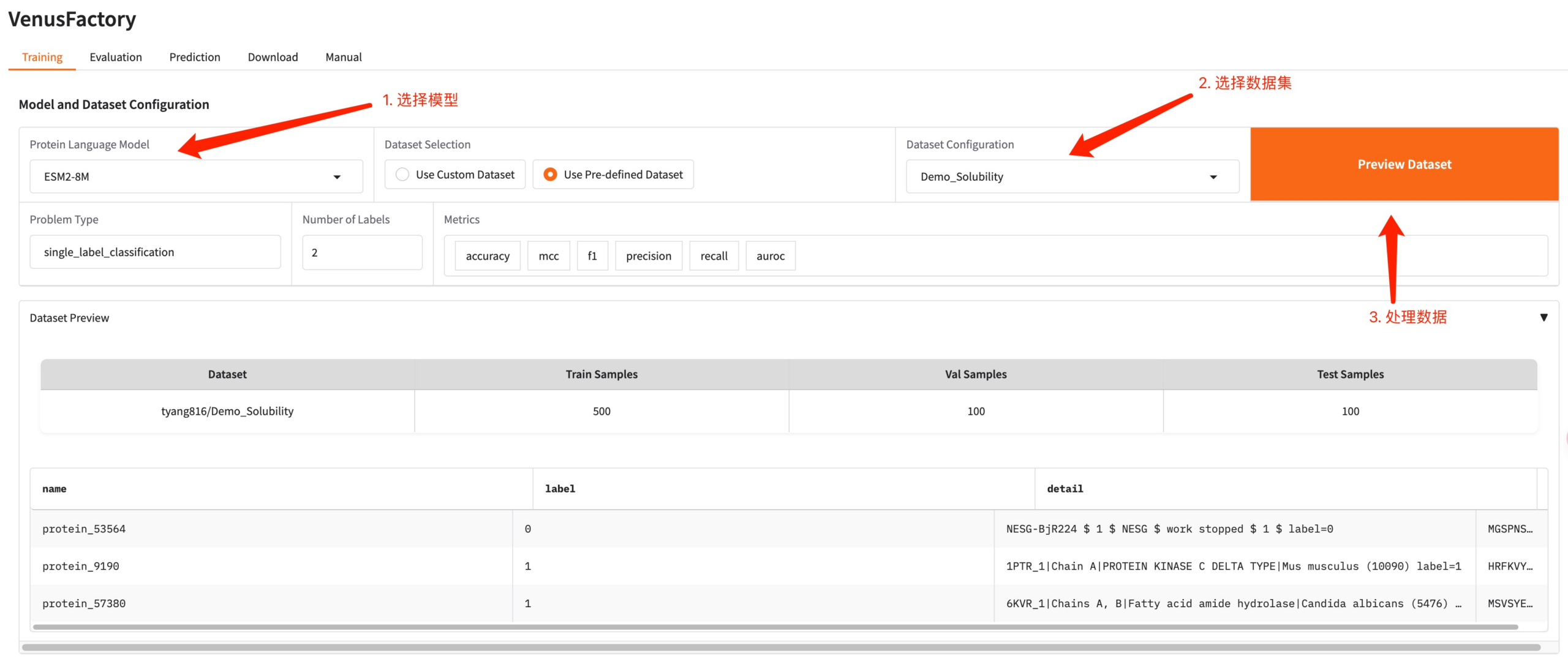
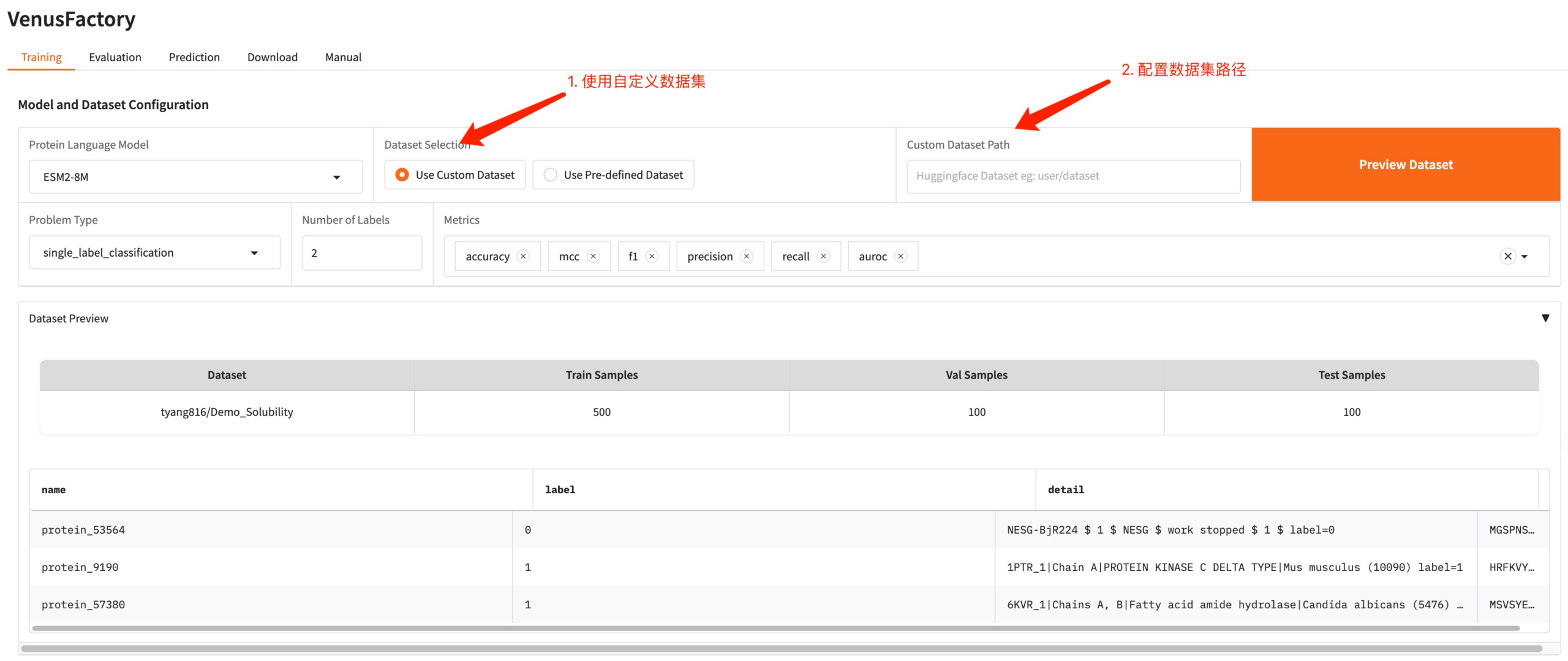
如需使用自有数据集,可以通过 Use Custom Dataset 配置,只需要填写数据集路径即可(详情请参阅 Manual 使用文档)。
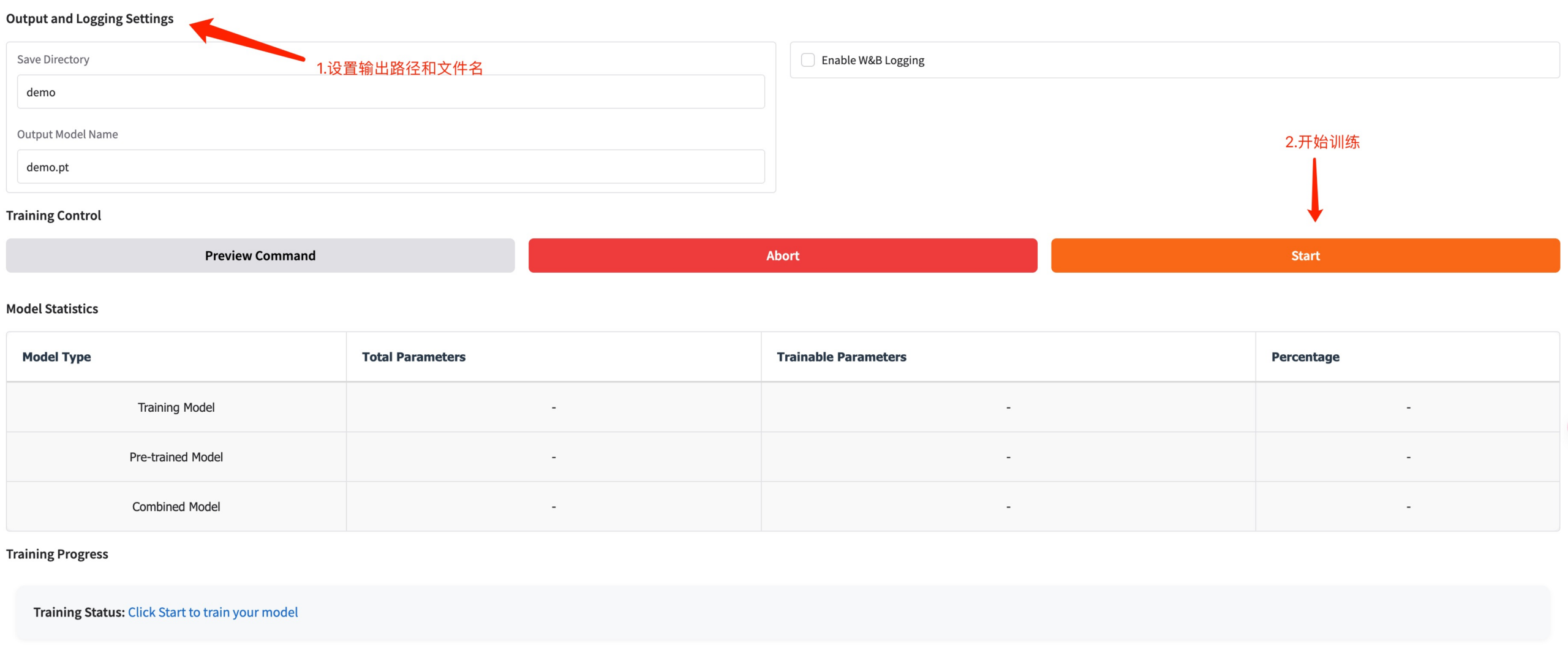
设置训练模型保存路径,点击 Start 开始训练。
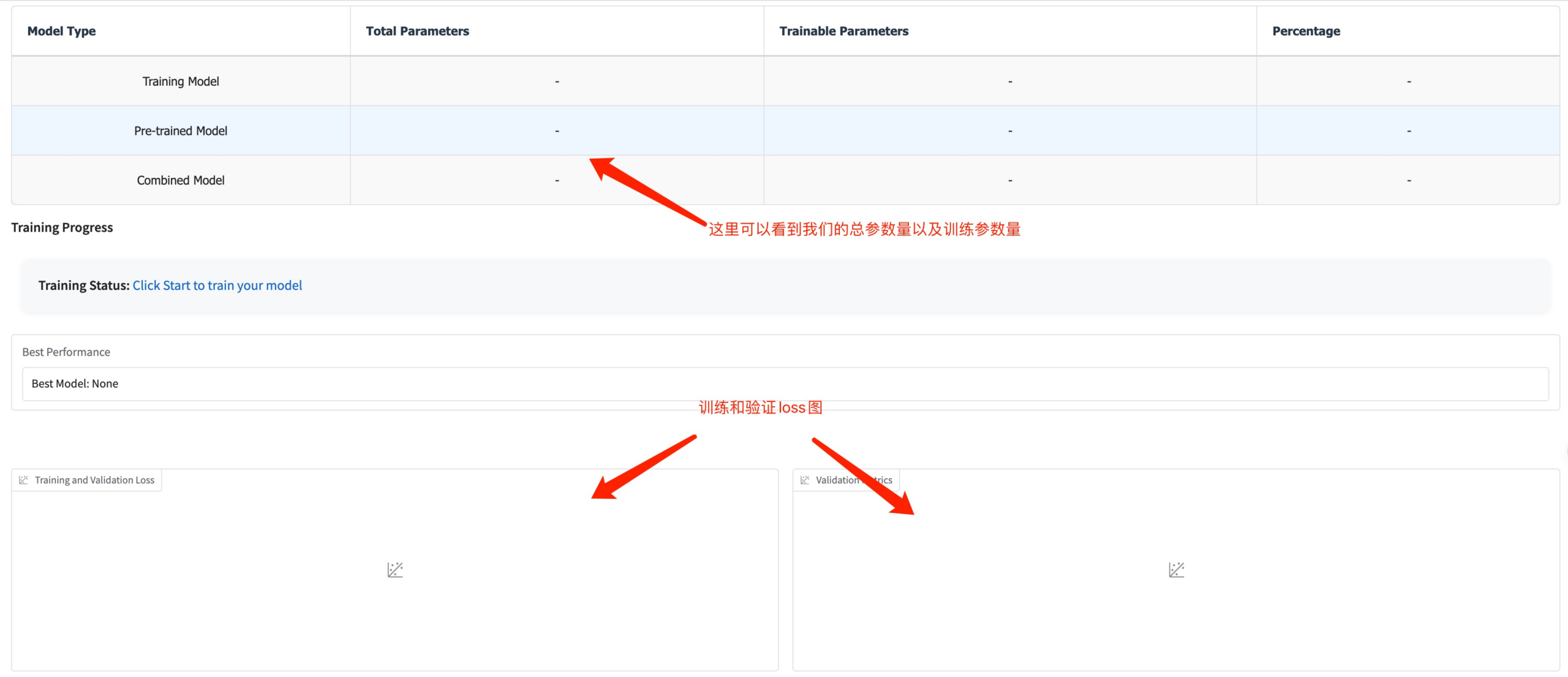
此时可以看到训练的参数量以及 loss 曲线图
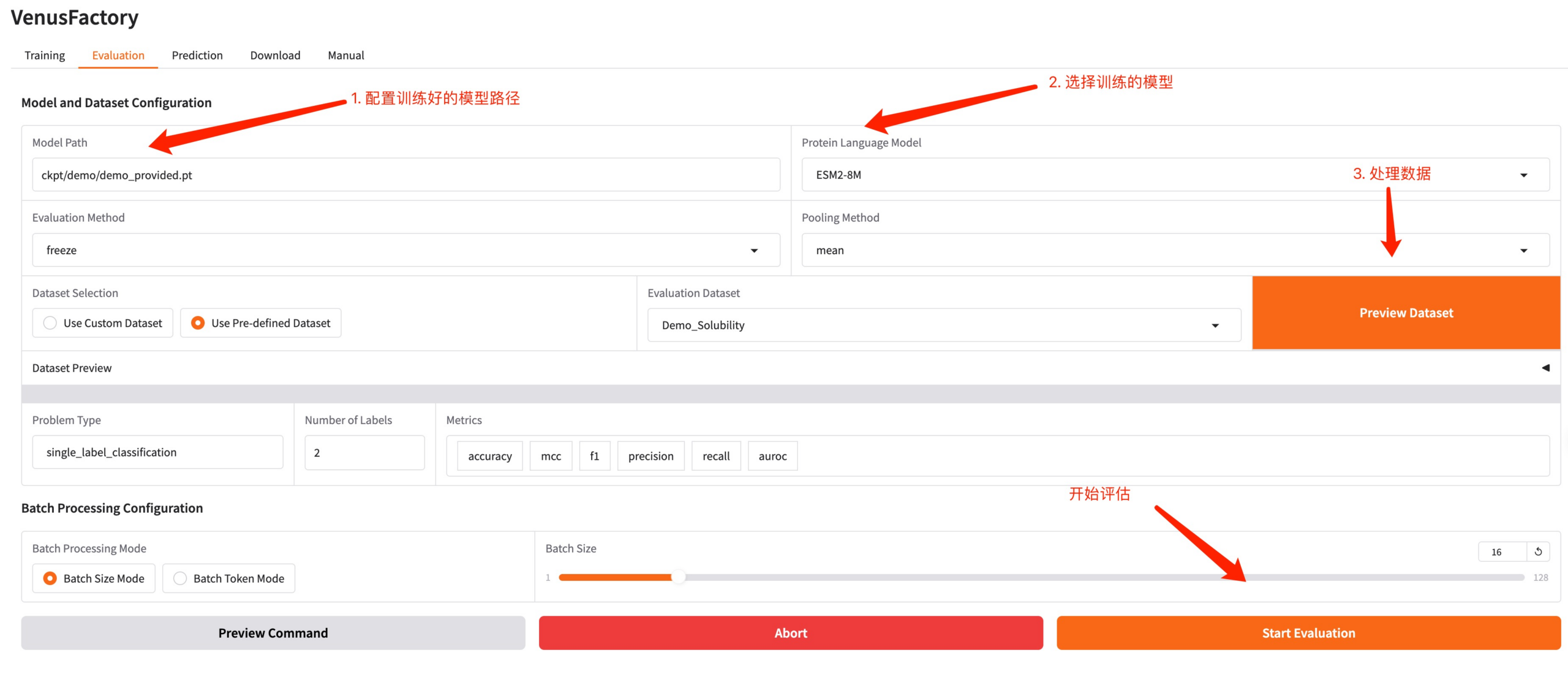
3. Evaluation 模块
点击 Evaluation 模块,配置好训练生成的模型路径以及训练的模型,进行处理数据,同时可以调整超参数然后开始评估。
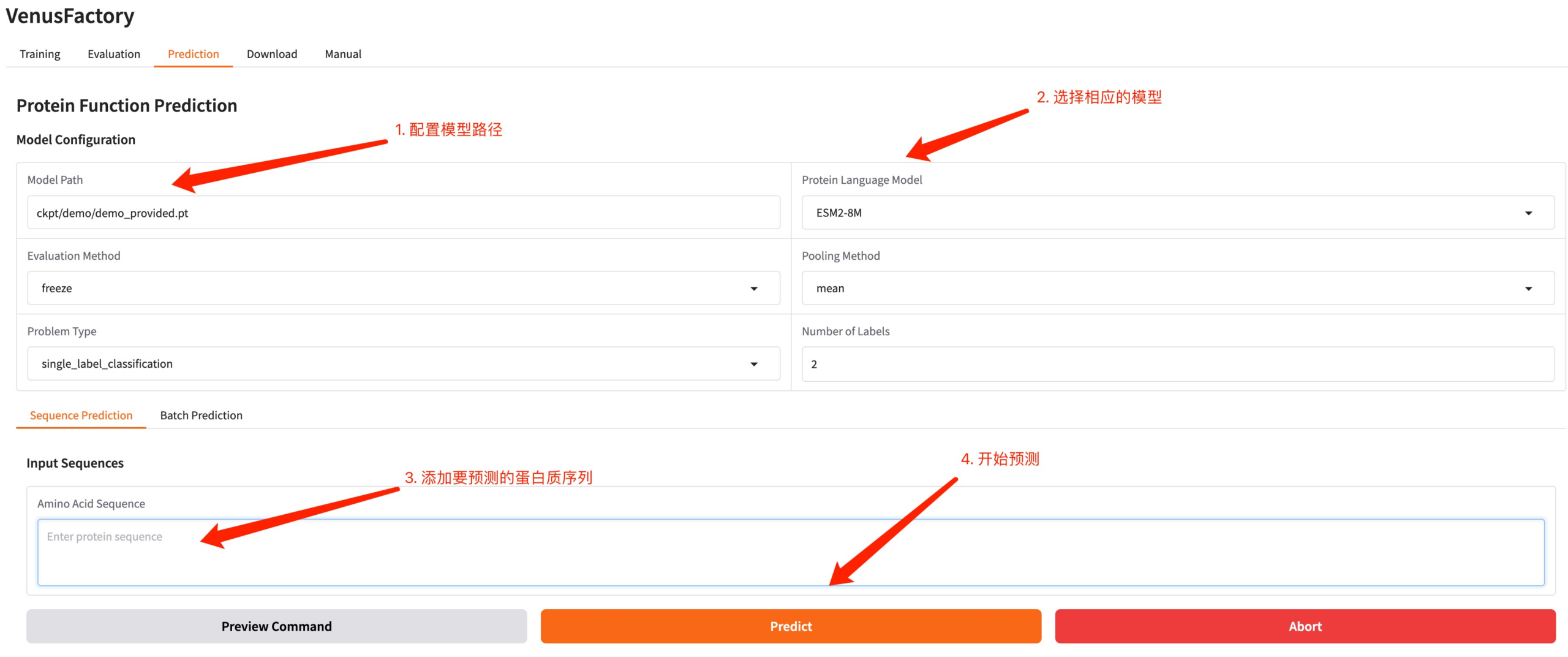
4.Predict 模块
点击 Predict 模块,配置好训练生成的模型路径以及训练的模型,输入想要预测的蛋白质序列,点击 Predict 进行预测。
蛋白质序列示例:MKTWFGHVLQ
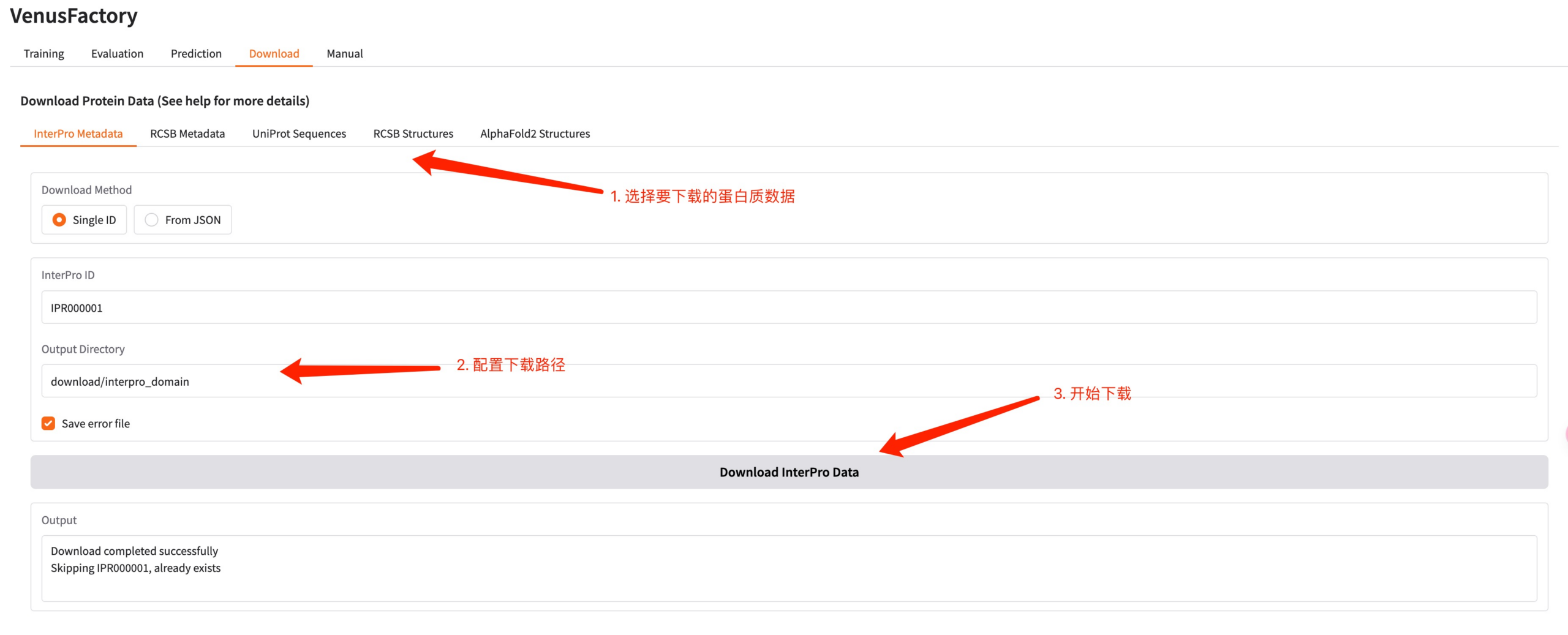
5.Download 模块
点击 Download 模块,可以在该界面下载蛋白质数据。
以上就是「VenusFactory 蛋白质工程设计平台」的详细使用教程,欢迎大家前来体验!








