Command Palette
Search for a command to run...
入选 NeurIPS 2024!中科院团队提出非侵入式大脑解码新框架,为脑机接口和认知模型发展奠定基础
你能想象自己看到、想到,甚至是梦到的画面被可视化出来吗?这并非天马行空的想象,早在 2008 年,美国加州伯克利分校神经系统科学家 Jack Gallant 就在 Nature 中提出了他的假设,他们利用功能磁共振成像 (functional Magnetic Resonance Imaging, fMRI) ——一种非侵入式脑功能成像技术「读取」受试者大脑视觉皮层的活动,然后通过视觉重建来可视化呈现受试者所看到画面,打响了世界范围内科学家解码大脑的号令枪。
相比侵入性脑解码技术,以 fMRI 为代表的非侵入性脑解码技术以更简单、更安全的方式实现大脑解码而倍受重视,在认知神经科学研究、脑机接口应用以及临床医学诊断等诸多领域都极具潜在应用价值。
然而,非侵入性脑信号的解码受碍于个体差异和神经信号表征的复杂性影响,依旧是大脑解码过程中的关键挑战。一方面传统方法需依赖于定制模型和大量昂贵的实验;另一方面由于缺乏准确语义和可解释性,导致传统方法在视觉重建任务中很难准确重现个人的视觉体验。
对此,中国科学院自动化研究所曾毅教授团队创新性地设计了一种多模态集成框架,该框架融合 fMRI 特征提取器与大语言模型,解决大脑活动的视觉重建问题。利用 Vision Transformer 3D (ViT3D),研究人员将三维大脑结构与视觉语义结合,通过高效统一特征提取器对 fMRI 特征与多层次视觉嵌入进行对齐,无需特定模型即可从单次实验数据中提取信息。此外,提取器整合了多层次视觉特征,简化了与大语言模型 (LLMs) 的整合,通过增强 fMRI 数据集以及与 fMRI 图像相关的文本数据,可开发多模态大模型。
该成果以「Neuro-Vision to Language: Enhancing Brain Recording-based Visual Reconstruction and Language Interaction」为题,已被 NeurIPS 2024 接收 。
研究亮点:
* 这项研究显著提升了通过大脑信号重建视觉刺激的能力,加深了对相关神经机制的理解,为解读大脑活动开辟了新途径
* 基于 Vision Transformer 3D 的 fMRI 特征提取器,将三维大脑结构和视觉语义相结合,并在多个层次上进行对齐,消除了对特定主题模型的需要,仅单次实验就能提取有效数据,极大降低了训练成本,增强了在现实场景中的可用性
* 通过扩展 fMRI 图像相关文本数据,构建了一个能够解码 fMRI 数据的多模态大模型,不仅提高了大脑解码性能,同时扩大了其应用范围,包括视觉重建、复杂推理、概念定位等任务
论文地址:
https://nips.cc/virtual/2024/poster/93607
关注公众号,后台回复「大脑信号解码」获取完整 PDF
开源项目「awesome-ai4s」汇集了百余篇 AI4S 论文解读,并提供海量数据集与工具:
https://github.com/hyperai/awesome-ai4s
数据集:基于自然场景数据集,严格评估测试可靠性
实验所用数据集涉及 Natural Scenes Dataset ( NSD) 数据集和 COCO 数据集,其中 NSD 数据集包含从 8 名健康成人参与者中收集到的高分辨率 7Tesla fMRI 扫描,但在具体实验分析时,研究人员主要分析了其中完成所有数据采集的 4 名受试者。
研究人员还对 NSD 数据集进行了预处理,以便纠正 slice 时序差异的时间重采样,以及空间插值来调整头部运动和空间失真。比如像裁剪这类的修改,会导致原始标题和实例边界框之间不匹配,如下图所示。为了确保数据一致性,研究人员会重新注释裁剪的图像,使用 BLIP2 为每个图像生成 8 个标题,并使用 DETTR 为这些图像生成边界框。

由于一些图像经过操作剪辑,原始标题和实例边界框之间存在不匹配
此外,为了确保 fMRI 数据与 LLMs 之间的兼容性,并实现指令遵循和多样化的交互,团队使用自然语言注释 NSD 时,扩展了 7 种类型的对话,分别是:简要说明 (brief descriptions) 、详细描述 (detailed descriptions) 、连续对话 (continuous dialogues) 、复杂推理任务 (complex reasoning tasks) 、指令重构 (instruction reconstruction) 和概念定位 (concept localization) 。
最后,为保证数据的标准化,研究人员使用三线性插值将数据调整到统一的维度,设置 fMRI 标准化为 83 × 104 × 81,在对边缘应用零填充后将数据划分为 14 × 14 × 14 个补丁以保留局部信息。
模型架构:融合 fMRI 特征提取与 LLMs 的多模态集成框架
为了解决大脑活动的视觉重建,同时消除 LLMs 与多模态数据的融合问题,研究团队创新性地设计了一种多模态集成框架,融合 fMRI 特征提取与大语言模型。如下图所示:
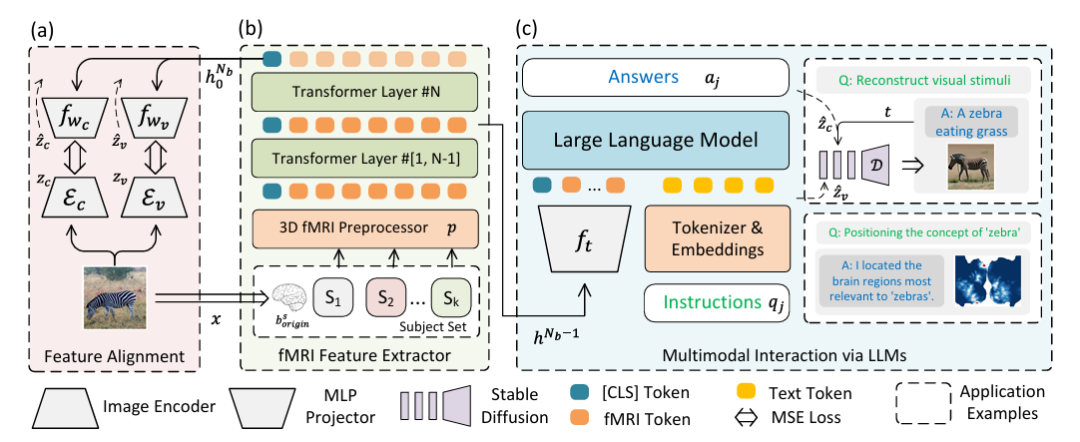
具体来说,上图 (a) 部分描述了使用 Variational Autoencoder (VAE) 和 CLIP 嵌入进行特征对齐 (Feature Alignment) 的双流路径。实验设置上集成了 CLIP ViT-L/14 和 AutocoderKL 作为图像特征提取器,两个隐藏维度为 1024 的双层感知器 fwc 和 fwv,分别用于与 VAE (zv = Ev) 和 CLIP (zc = Ec) 特征对齐。
上图 (b) 部分描述了一个 3D fMRI 预处理器 p 和一个 fMRI 特征提取器 (fMRl Feature Extractor) 。对于 fMRI 数据,使用的是一个 16 层的 Transform Encoder,隐藏大小为 768 来提取特征,并使用最后一层的类标记作为输出。然后回到图 (a) 进行对齐,以实现高质量视觉重建。
上图 (c) 部分描述了与 fMRI 集成的多模态 LLMs,即通过 LLM 实现多模态互动 (Multimodal Interaction via LLMs) 。主要是将提取的特征输入 LLMs,用于处理自然语言指令并生成响应或视觉重建。这部分利用网络的倒数第二个隐藏状态 hᴺᵇ⁻¹ 作为 fMRI 数据的多模态标记,fₜ 为一个两层感知器,「Instruction」表示自然语言指令,「Answer」表示 LLMs 生成的相应。
经过基于指令的微调后,该模型便可直接通过自然语言进行交流,并支持对自然语言表达的概念进行视觉重建和位置识别,分别通过 UnCLIP 进行视觉重建和 GradCAM 进行概念定位,图中 D 表示冻结的 UnCLIP 。
实验结果:三大实验、多方对比,新框架在解码大脑信号方面表现卓越
为了评估所提框架的性能,研究人员通过进行字幕和问答、视觉重建以及概念定位等多种类型实验,并与其他不同的方法进行比较,从而验证了该框架的可行性和高效性。
如下图所示,所提框架在大脑字幕任务 (Brain Caption) 的大多数指标上都表现出了卓越的性能。此外,该框架具有良好的泛化能力,不必为每个受试者训练单独的模型或引入特定于受试者的参数。研究人员还结合了用于详细描述 (Detail Description) 和复杂推理 (Complex Reasoning) 的任务,该框架在这两个任务上也取得了最佳性能,这表明它不仅可以生成简单的标题,还可以实现详细的描述并执行复杂的推理。
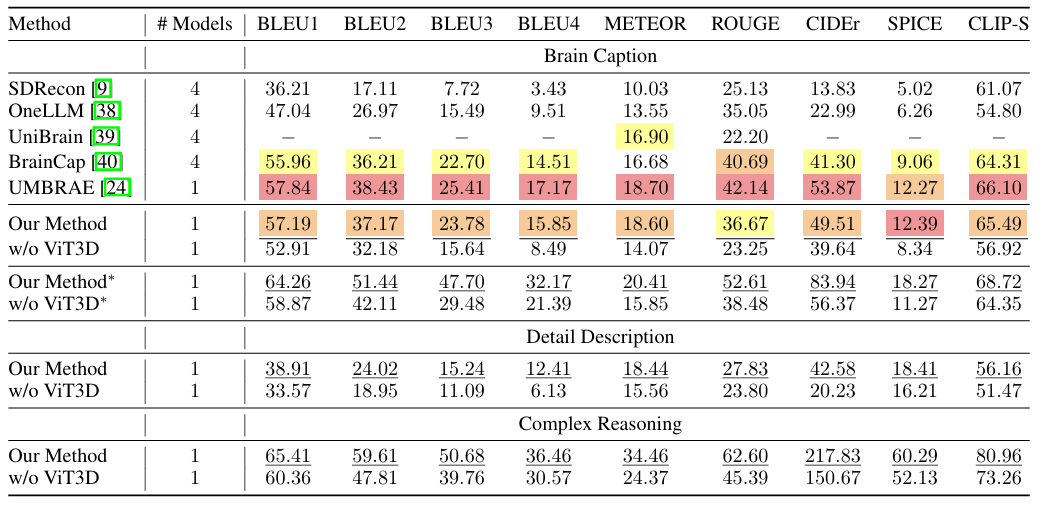
在视觉重建实验中,如下图所示。本研究所提方法在高层特征匹配方面表现出色,证明了该模型有效利用 LLMs 解释复杂视觉数据的能力。在各种视觉刺激上的鲁棒性证实了所提方法对 fMRI 数据的全面理解。没有 LLM 和 VAE 特征等关键成分的实验出现分数结果的下降,突出了研究方法中每种元素的重要性,这对于获得最先进的结果至关重要。
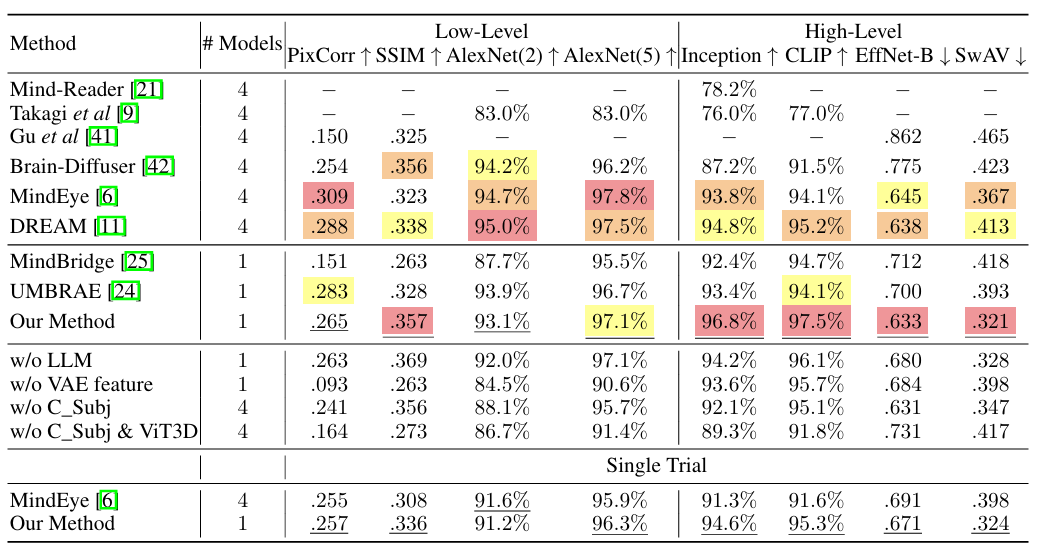
此外,研究人员还进行了单次试验验证,选择只使用第一个视觉刺激,类似于 MindEye 的方法。结果显示即使在更严格的条件下,所提方法也只是显示了性能轻微下降,证明了它实际应用的可行性。
在概念定位实验中,研究人员首先对 LLMs 进行了微调,以从自然语言中提取目标概念,这些概念一旦通过 CLIP 文本编码器编码,就会成为 GradCAM 的目标。为提高定位精度,研究人员训练了 3 个不同 patch 大小 (14 、 12 、 10) 的模型,并利用所有模型的倒数第二层来提取语义特征。如下图所示,这表明了所提方法能够区分相同视觉刺激的大脑信号中各种语义的位置。

为验证这一方法的有效性,研究人员对语义概念进行了消融研究。在原始脑信号中对概念定位后,对识别出的体素中的信号进行置零,然后使用修改后的脑信号进行特征提取和视觉重建。如下图所示,移除与某些语义概念相关的特定大脑区域的神经活动,会导致视觉重建中忽略相应的语义,这证实了在脑信号中进行概念定位方法的有效性,并证明了该方法在大脑活动中提取和修改语义信息的能力,这对于理解大脑中的语义信息处理至关重要。

总的来说,该框架利用 Vision Transformer 3D 与 fMRI 数据的能力,通过 LLMs 的集成得到增强,让大脑信号重建视觉刺激方面得到了显著的改善,并为潜在的神经机制提供了更精确和可解释的理解。这一成果对于解码和解释大脑活动提供了新的研究路径,在神经科学和脑机接口方面具有重要意义。
解码人脑运作真相,探索自然界最神秘仪器
大脑作为人类最重要的生物器官,也是自然界中最精密的仪器——拥有上千亿个神经细胞和百万亿个连接突触,形成了神经网络和主导各种脑功能的神经环路。而随着生命科学技术和人工智能的不断发展,大脑运作的真相正在变得越来越清晰。
值得一提的是,本次论文出处的中国科学院自动化研究所作为我国人工智能发展的领头羊,很早就已经在脑科学领域布局研究,尤其是人脑视觉信息编解码研究方面。除了上述提到的曾毅教授团队,该院曾发表多篇脑科学相关高水平论文,并被国际知名期刊杂志收录。
比如在 2008 年底,该院何晖光教授领导的团队发表的题为「Reconstructing Perceived Images from Human Brain Activities with Bayesian Deep Multiview Learning」的相关研究成果,被收录于神经网络及机器学习领域国际权威期刊 IEEE Transactions on Neural Networks and Learning Systems 。
在这篇研究中,研究团队以一种科学合理的方式建立起了视觉图像和大脑响应之间的关系,将视觉图像重建问题转化成多视图隐含变量模型中缺失视图的贝叶斯推断问题。这项研究不仅为探究大脑的视觉信息处理机制提供了一个强有力的工具,而且为脑机接口的发展,以及类脑智能的发展起到一定的促进作用。
除了中国科学院自动化研究所外,新加坡国立大学的研究团队也在通过研究使用 fMRI 记录被试者看到的图像,然后使用机器学习算法将其还原成图像。其相关成果以「Seeing Beyond the Brain: Conditional Diffusion Model with Sparse Masked Modeling for Vision Decoding」为题,发表在 arXiv 上。

除此外,不少商业公司也在窥探「脑世界」的路上狂奔。就在不久前,埃隆·马斯克在 2024 年神经外科医生大会上也分享了他对旗下脑机接口公司 Neuralink 以及脑机接口技术的见解,甚至提出了脑机接口费用不应价格过高的言论。
总而言之,针对大脑的解码技术可以说是一个不断且快速发展的过程,无论是科研单位的推动,或者是商业公司的推动,都在乘着着人工智能和机器学习的东风不断加速智脑时代的到来。同样值得相信的是,科学的进步也必将会反馈在应用上,比如脑机接口的发展,用机器造福神经系统受损的患者等等。