Command Palette
Search for a command to run...
首个!四大高校联合推出药物研发大语言模型 Y-Mol,性能全面领先 LLaMA2

以 ChatGPT 、 ChatGLM 和 LLaMA 等为代表的大语言模型已成为人们探索未知世界的有力工具,这些拥有数十亿参数的模型,通过大规模文本语料库的精心训练,在生成文本和理解上下文方面展现出强大的能力。然而,这些模型大多在一般任务中表现出色,在某些特定领域,尤其是药物研发领域,却面临着不小的挑战。
与自然语言处理领域不同,药物研发领域缺乏统一的标准范式,研发过程复杂且成本高昂。此外,它还涉及计算化学、结构生物学和生物信息学等多个学科,相关数据难以获取,且药物相关实体之间的交互数据需要精细的领域知识才能进行标注,这些因素共同限制了大语言模型在药物研发领域的应用。
对此,湖南大学、中南大学、湖南师范大学、湘潭大学的研究团队联合提出了一种多尺度生物医学知识指导的大语言模型 Y-Mol 。 Y-Mol 是一种自回归的序列到序列模型,它能够在不同的文本语料库和指令上进行微调,大大增强了模型在药物研发方面的性能与潜力,这是大语言模型在药物研发领域的一次全新突破。
该研究以「Y-Mol: A Multiscale Biomedical Knowledge-Guided Large Language Model for Drug Development」为题,已在 arxiv 发表预印本。
研究亮点:
* Y-Mol 是首个为药物研发构建的大语言模型典范
* Y-Mol 通过整合多尺度生物医学知识,构建了一个信息丰富的指令数据集
* Y-Mol 在药物-药物相互作用、药物-靶标相互作用、分子属性预测等方面表现优异,在各种药物研发任务的理解和通用性方面表现出强大的能力

论文地址:
https://doi.org/10.48550/arXiv.2410.11550
关注公众号,后台回复「药物研发大模型」获取完整 PDF
开源项目「awesome-ai4s」汇集了百余篇 AI4S 论文解读,并提供海量数据集与工具:
https://github.com/hyperai/awesome-ai4s
充分挖掘两大类数据集,构建全面的生物医学语料库
在构建 Y-Mol 的预训练数据集方面,该研究挑选了两种类型的数据集:来自生物医学 PubMed 出版物的文本语料库;基于生物医学知识图谱构建的监督指令,以及从专家模型中提取的推理数据。
为了深入挖掘出版物中丰富的生物医学知识,该研究从在线出版平台(如 PubMed)中提取并预处理了超过 3,300 万份涵盖多个学科的出版物。如下图 A 所示,研究人员从这些出版物中提取了可见的摘要和简介,将其作为生物医学文本数据 (Reconstructed Text),确保语料库的质量和相关性。
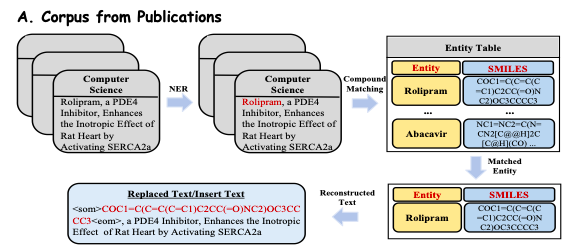
为了从生物医学知识库中高效提取领域知识,该研究将知识库中的事实转化为自然语言提示。如下图 B 所示,该研究认为子图中的每个推理链 (Reasoning Chains) 都具有明确的关系语义,因此提取了每个连贯的路径 (Pathway),并使用精心设计的模板将其转换为自然语言描述,作为提示上下文。然后,该研究将这些构建的上下文与相应的问题结合,输入到 Y-Mol 中,以输出有监督的答案。
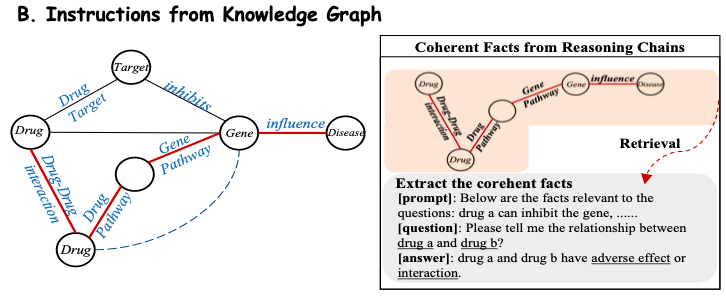
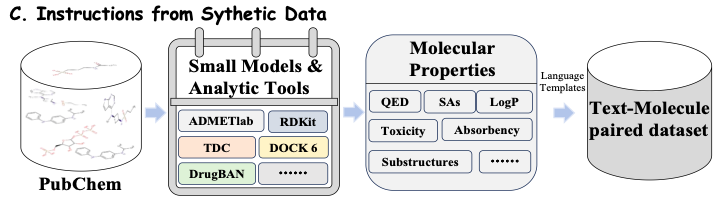
此外,为了获取基于药物属性和领域知识的大规模指令,该研究利用现有小模型的专家合成数据构建指令,将药物知识谱提炼到 Y-Mol,最终,该研究汇集了 1,120 万个语料库条目和 230 万个精心设计的指令。
如下图 C 所示,针对给定的药物分子,为了提取更全面的分子性质 (Molecular Properties),该研究汇集了一系列先进的分子工具和计算模型,如 ADMETlab 、 RDKit 、 TDC 和 DrugBAN 。这些工具和模型从公开可用的数据集中提取了具有不同特性的分子信息,包括 QED 、 SAs 、 LogP 、毒性 (Toxicity) 、吸收性 (Absorbency) 以及亚结构 (Substructures) 等。通过这种方式,该研究可以持续集成最新的模型和工具,并利用它们的预测数据来训练模型,从而使 Y-Mol 实时进化,保持其在药物研发领域的领先地位。
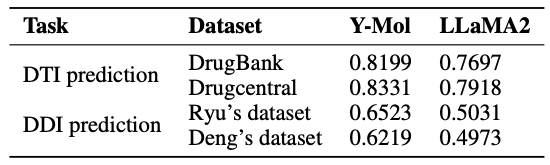
最后,如下图所示,该研究展示了 Y-Mol 在预训练和监督微调阶段,针对不同任务的数据分布情况。在推理能力的评估方面,为了全面测试 Y-Mol 在药物-靶标相互作用 (DTI) 预测和药物-药物相互作用 (DDI) 预测方面的性能,研究团队选用了业界广泛认可的基准数据集 DrugBank 和 DrugCentral 来进行 DTI 预测。
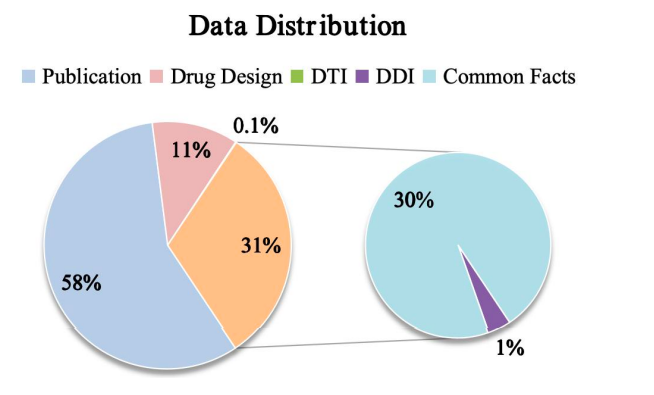
同时,为了对 DDI 预测的性能进行评估,研究者们采用了 Ryu 和 Deng 提供的数据集。这些评估方法经过精心选择,确保 Y-Mol 能在药物研发领域的行业标准下得到公正和全面的检验,证明其有效性。
Ryu’s dataset: https://doi.org/10.1073/pnas.1803294115
Deng’s dataset: https://doi.org/10.1093/bioinformatics/btaa501
Y-Mol:基于 LLaMA2-7b,专用于药物研发
该研究选用了 LLaMA2-7b 作为基础的大语言模型,进而构建一个专门用于药物研发的高级训练和推理框架——Y-Mol 。如下图所示,Y-Mol 的开发分为两个关键阶段:
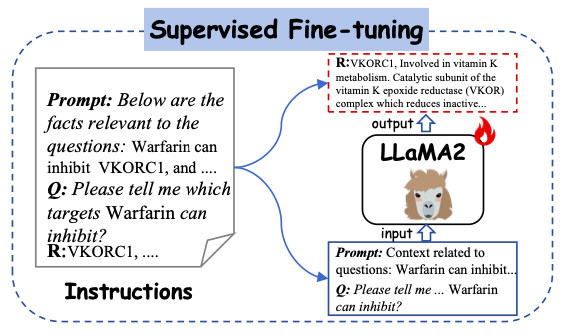
首先,Y-Mol 在生物医学出版物的大规模语料库上进行预训练,通过自监督预训练 (self-supervised pretrain) 的方式微调 LLaMA2,使 Y-Mol 能够对药物研发的背景知识有一个基本的掌握。接着,进一步监督 LLaMA2,利用药物相关领域知识和专家合成数据进行微调 (finetuning) 。这一过程将大量药物相关信息输入 Y-Mol,增强了模型对药物研发流程中相互作用机制的理解。
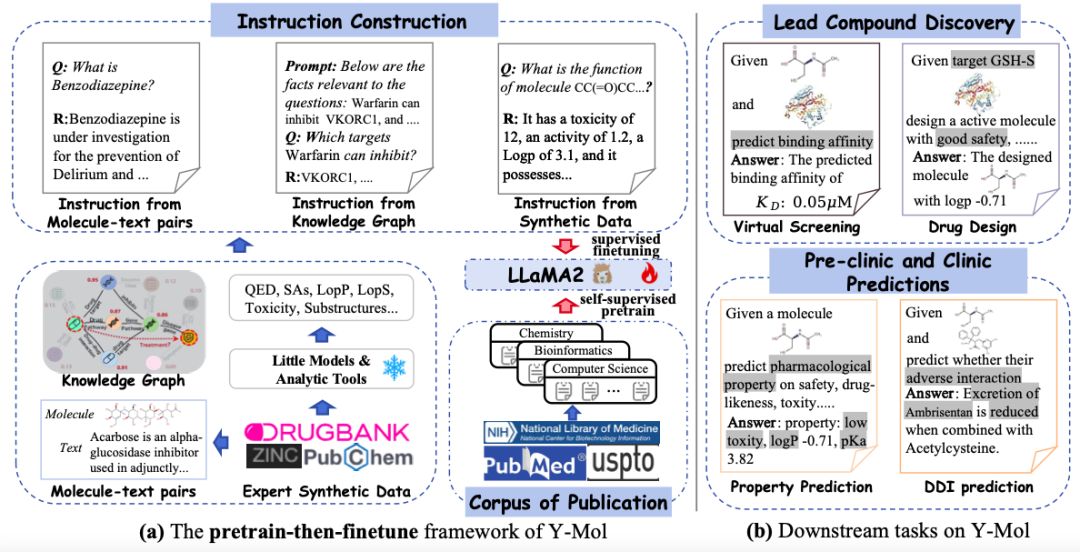
该研究精心设计了多样化的指令集,对 Y-Mol 进行细致的微调,这些指令包括了分子文本对的说明 (Instructions from Molecule-text Pairs),以及从药物数据库中提取的描述 (Descriptions from drug databases),这些描述以自然语言的形式呈现了药物的属性、结构和功能,蕴含了丰富的语义信息,有助于加强人类与大语言模型在药物实体感知上的一致性。
如下图所示,该研究采用生成的指令 (Instructions) 作为监督学习的输入 (input),并将其送入 Y-Mol 中。具体来说,将构建的提示上下文 (prompt contexts) 和问题输入到 Y-Mol 中,并使用这些构建的答案来监督模型生成的输出。
在根据这些生成的指令对 Y-Mol 进行细致的微调之后,研究人员将其应用于一系列下游任务,涵盖了从先导化合物的发现 (Lead compund Discovery) 到临床前和临床预测等 (Clinic Predictions) 多个环节。通过这种监督微调 (Supervised Fine-tuning) 的方法,Y-Mol 能够更准确地理解和处理药物研发中的复杂问题,为计算机辅助药物研发提供了一个强大的工具。
研究结果:Y-Mol 具备最优预测性能
为了全面验证 Y-Mol 在药物研发领域的有效性,该研究精心设计了一系列覆盖先导化合物发现 (lead compound discovery) 、临床前研究 (pre-clinic) 和临床预测 (clinic predictions) 等不同阶段的任务。具体来说,不同的关键任务如下:(1) 用于先导化合物发现的虚拟筛选、药物设计;(2) 临床前阶段对已发现先导化合物的物理和化学性质进行预测;(3) 预测临床阶段潜在的药物不良事件。
在虚拟筛选中,识别未知的药物-靶标相互作用对是至关重要的。如下表所示,相较于 LLaMA2,Y-Mol 在 DrugBank 和 DrugCentral 数据集上的 AUC 得分分别提升了 5.02% 和 4.13% 。这表明,Y-Mol 在多尺度数据源的 DTI 预测上表现优异,证明了其在虚拟筛选中的优越性能。
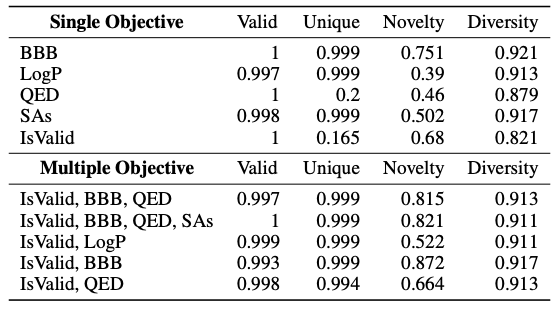
在药物设计中,为了验证 Y-Mol 在发现新先导化合物方面的性能,该研究还设计了一个针对特定条件产生有效化合物的任务,即给定一个目标条件和描述性查询,评估 Y-Mol 能否从上下文信息中精准生成对应的 SMILES 序列分子。
如下表所示,该研究引入 Valid 、 Unique 、 Novelty 、 Diversity 等标准指标,对 BBB 、 LogP 等不同的单一目标 (Single Objective) 进行预测。结果表明,Y-Mol 整体性能更好,相比之下,只有 LLaMA2-7b 模型的结构域适应能力表现不佳,无法生成有效的分子。同时,该研究还同时测试了多重目标 (Multiple Objective) 下 Y-Mol 的药物设计性能。结果表明,Y-Mol 在这种情况下也表现良好。
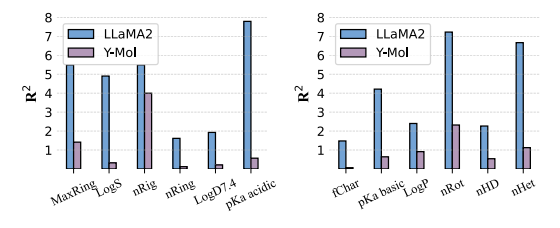
在分子属性预测中,如下图所示,Y-Mol 在所有任务中都展现出比 LLaMA2 更低的 R² 分数,这表明 Y-Mol 在预测理化属性方面具有更强的泛化能力。
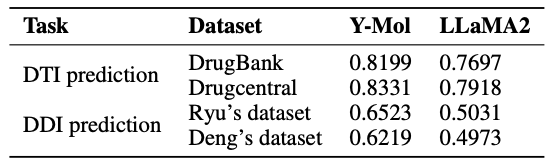
在药物研发的临床阶段,预测潜在的药物-药物相互作用是确保药物安全使用的关键。如下图所示,Y-Mol 在识别潜在的药物相互作用任务方面表现出色 (DDI) 。
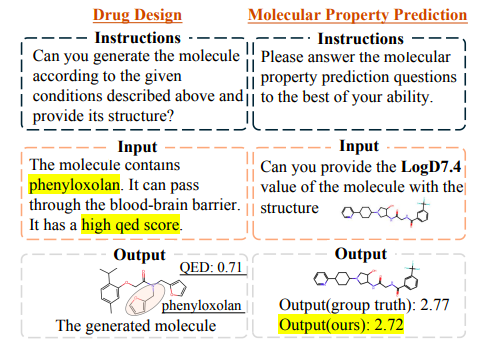
如下图所示,Y-Mol 设计的药物有效地满足了在查询中 (query) 提出的约束条件。同样地,Y-Mol 能够准确地预测给定分子 LogD7.4,且预测结果与实际值非常接近,这证明了 Y-Mol 在解决药物研发任务方面的有效性。
AI 技术:药物研发领域的新引擎
事实上,在药物研发的漫长旅程中,科学家们一直在寻找能够加速这一过程的新技术。近年来,AI 技术在这一领域展现出了巨大的应用潜力,它们不仅能够深入理解疾病机制,还能在药物发现和临床试验等关键阶段发挥重要作用。
在企业界,一些公司已经在 AI 药物研发方面取得了显著成果。例如,AI 药物研发公司 Insilico Medicine 在今年初宣布,他们发现了一种全新机制的用于治疗特发性肺纤维化的临床候选新药,该药物已经通过了多次人类细胞和动物模型实验验证。此外,华为云与中国科学院上海药物研究所合作,推出了盘古药物分子大模型,该模型能够实现针对小分子药物全流程的人工智能辅助药物设计,提高药物研发的效率和准确性。
在科研领域,本文研究的作者之一,湖南大学曾湘祥教授团队也曾设计了一款多肽序列大语言模型,通过逐步添加计算和筛选条件,对模型进行训练。仅用 3 个月时间,该模型便成功设计并合成了 29 种潜在的抗菌肽,其中 26 种显示出广谱抗菌活性。在小鼠实验中,有 3 种抗菌肽表现出与 FDA 批准的抗生素相当抗菌效果,且在长达 25 天的连续培养和监测中未观察到明显的耐药性产生。这一成果已被《Nature Communications》正式接收。
论文链接:
https://www.nature.com/articles/s41467-024-51933-2
此外,本文研究的另一作者,中南大学曹东升教授联合浙江大学的侯廷军教授和谢昌谕教授,前不久也共同开发了分子优化工具 Prompt-MolOpt 。该算法利用提示学习的训练策略,实现了零样本学习和少样本学习在多性质优化中的应用。
论文链接:
https://www.nature.com/articles/s42256-024-00916-5
从深入理解疾病机制到加速药物发现,再到优化临床试验设计,AI 技术正在成为药物研发的新引擎,随着技术的不断进步,它将在未来的医药研究中发挥出愈发关键的作用。









