Command Palette
Search for a command to run...
以 Animated Drawings APP 为例,用 TorchServe 进行模型调优
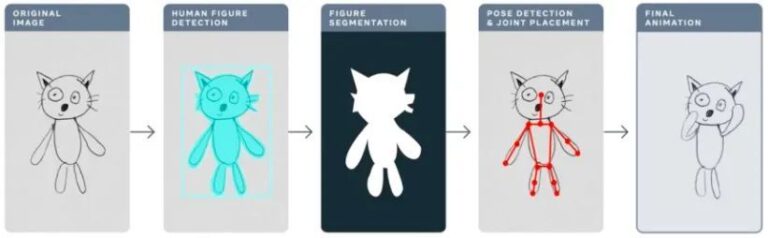
内容导读 上节介绍了 TorchServe 模型部署调优的 5 个步骤,将模型部署到生产环境中。本节以 Animated Drawings APP 为例,实际演示 TorchServe 的模型优化效果。 本文首发自微信公众号:PyTorch 开发者社区
去年,Meta 凭借 Animated Drawings 应用程序,用 AI 让儿童手工画「动」了起来,静态简笔画秒变动画~


Animated Drawingssketch.metademolab.com/
这对于 AI 来说并不简单。 AI 的设计初衷是为了处理真实世界中的图像,儿童绘画与真实图像相比,形态和风格迥异,更具有复杂性及不可预测性,因此先前的 AI 系统可能并不适用于处理 Animated Drawings 类似的任务。
本文将以 Animated Drawings 为例,详细讲解如何借助 TorchServe,对即将部署到生产环境中的模型进行调优。
4 大因素影响生产环境中的模型调优
下面的工作流程展示用 TorchServe 在生产环境中进行模型部署的总体思路。

大多数情况下,部署模型到生产环境中是基于吞吐量 (throughput) 或延迟 (latency) 服务级别协议 (SLA) 进行优化的。
通常实时应用程序 (real-time application) 更关心延迟,而离线应用程序 (off-line application) 则更关心吞吐量。
对于部署到生产环境中的模型,影响性能的因素众多,本文重点介绍 4 个:
1. Model optimizations
这是将模型部署到生产环境的前置步骤,包括量化、剪枝、使用 IR graphs(PyTorch 中的 TorchScript)、融合内核及其他众多技术。目前,TorchPrep 中提供很多类似技术作为 CLI 工具。
2. Batch inference
它是指将多个 input 输入到一个模型中,在训练过程中会频繁用到,对于在推理阶段控制成本也很有帮助。
硬件加速器对并行进行了优化,batching 有助于充分利用计算能力,这经常导致更高的吞吐量。推理的主要区别在于无需等待太久,就能从客户端获得一个 batch,也就是我们常说的动态批处理 (dynamic batching) 。
3. Numbers of Workers
TorchServe 通过 worker 部署模型。 TorchServe 中的 worker 属于 Python 进程,拥有用于推理的模型权重副本。 worker 数量太少,无法从足够的并行性中受益;worker 数量太多,又会导致 worker contention 及端到端性能降低。
4. Hardware
根据模型、应用程序及延迟、吞吐量预算,从 TorchServe 、 CPU 、 GPU 、 AWS Inferentia 中选择一个合适的硬件。
有些硬件配置是为了获取最好的 class 性能,有些是为了更符合预期的成本管控。实验表明,batch size 较大时更适合选用 GPU;batch size 较小或要求低延迟时,选用 CPU 和 AWS Inferentia 则更具备成本优势。
Tips 分享:TorchServe 性能调优的注意事项
开始之前,我们先分享一些用 TorchServe 部署模型、获得最佳性能的 Tips 。
硬件选择与模型优化选择也是紧密联系的。
* 模型部署的硬件选择,与延迟、吞吐量预期以及每次推理的成本密切相关。
由于模型大小和应用的不同, CPU 的生产环境通常无法负担类似计算机视觉模型的部署,大家可以注册使用 OpenBayes.com,注册即送 3 小时 RTX3090,每周还赠送 10 小时 RTX3090,满足一般的 GPU 需求。
此外,最近添加到 TorchServe 中的 IPEX 等优化,使得这类模型的部署成本更低、更能被 CPU 负担。
* TorchServe 中的 worker 属于 Python 进程,可以提供并行,应谨慎设定 worker 数量。默认情况下 TorchServe 启动的 worker 数量等于主机上的 VCPU 或可用 GPU 数量,这可能会给 TorchServe 启动增加相当长的时间。
TorchServe 公开了一个 config property 来设置 worker 的数量。为了让多个 worker 提供高效并行并避免它们竞争资源,建议在 CPU 和 GPU 上设置以下 baseline:
CPU:在 handler 中设置 torch.set _ num _ thread (1) 。然后将 workers 的数量设置成 num physical cores / 2 。但最好的线程配置可以通过利用 Intel CPU launcher script 来实现。
GPU:可用 GPU 的数量可以通过 config.properties 中的 number_gpus 进行设置。 TorchServe 使用循环分配 worker 到 GPU 。建议:Number of worker = (Number of available GPUs) / (Number of Unique Models)。注意, pre-Ampere 的 GPU 不提供任何与 Multi Instance GPU 的资源隔离。
* Batch size 直接影响延迟和吞吐量。为了更好地利用计算资源,需要增加 batch size 。在延迟和吞吐量之间存在 tradeoff;较大的 batch size 可以提高吞吐量,但也会导致较高的延迟。
TorchServe 中有两种设置 batch size 的方式,一种是通过 config.properties 中 model config 进行,另一种使用 Management API 来 registering model 。
下节展示如何用 TorchServe 的 benchmark suite 来决定模型优化中硬件、 worker 和 batch size 的最佳组合。
认识 TorchServe Benchmark Suite
要使用 TorchServe benchmark suite,首先需要一个 archived file,即上文提过的 .mar 文件。该文件包含模型、 handler 和其他所有用来加载和运行推理的其他 artifacts 。 Animated Drawing APP 使用 Detectron2 的 Mask-rCNN 目标检测模型
运行 benchmark suite
TorchServe 中的 Automated benchmark suite 可以在不同 batch size 和 worker 设置下,对多个模型进行基准测试,并输出报告。
开始运行:
git clone https://github.com/pytorch/serve.git cd serve/benchmarks pip install -r requirements-ab.txt apt-get install apache2-utils
在 yaml 文件中配置模型 level 设置:
Model_name:
eager_mode:
benchmark_engine: "ab"
url: "Path to .mar file"
workers:
- 1
- 4
batch_delay: 100
batch_size:
- 1
- 2
- 4
- 8
requests: 10000
concurrency: 10
input: "Path to model input"
backend_profiling: False
exec_env: "local"
processors:
- "cpu"
- "gpus": "all"
这个 yaml 文件将被 benchmark_config_template.yaml 引用。 Yaml 文件中包括用于生成报告的其他设置,也可以用 AWS Cloud 查看 logs 。
python benchmarks/auto_benchmark.py --input benchmark_config_template.yaml
运行 benchmark,结果被保存在一个 csv 文件中,可以在 _/tmp/benchmark/ab_report.csv_ 或完整报告 /tmp/ts_benchmark/report.md 中找到。
结果包括 TorchServe 平均延迟、模型 P99 延迟 (model P99 latency) 、吞吐量、并发 (concurrency) 、请求数、 handler time 及其他 metrics 。
重点跟踪以下影响模型调优的因素:并发、模型 P99 延迟、吞吐量 。
这些数字要与 batch size 、使用的设备、 worker 数量以及是否做了模型优化结合起来看。
这个模型的 latency SLA 已经设置为 100 ms,这是个实时应用程序,延迟是很重要的问题,在不违反 latency SLA 的情况下,吞吐量最好尽可能高。
通过搜索空间,在不同的 batch size (1-32) 、 worker 数量 (1-16) 和设备 (CPU, GPU) 上运行一系列实验,总结出最好的实验结果,见下表:

这个模型在 CPU 上的延迟、 batch size 、并发和 worker 数量等方面进行的所尝试,都没有到 SLA,实际上延迟降低了 13 倍。
将模型部署移动到 GPU 上,可以立即将延迟从 305ms 降到 23.6ms 。
可以为模型做的最简单的优化之一,就是把它的精度降低到 fp16,一行代码 (model. half ()) ,可以减少 32% 的模型 P99 延迟 ,并增加几乎相同数量的吞吐量。
模型优化方法还有将模型转化为 TorchScript 并使用 optimation_for_inference 或其他技巧(包括 onnx 或 tensort runtime optimizations)进行优化,这些优化利用了 aggressive fusions 。
在 CPU 和 GPU 上,设置 number of workers=1 对于本文的 case 效果最好。
* 将模型部署到 GPU,设置 number of workers = 1, batch size = 1,吞吐量增加 12 倍相比于 CPU 上 降低 13 倍延迟。
* 将模型部署到 GPU,设置 model.half()、 number of workers = 1 、 batch size = 8,可以获得吞吐量和可承受的延迟方面的最佳结果。与 CPU 相比,吞吐量增加 25 倍,延迟仍然满足 SLA (94.4 ms) 。
注意: 如果正在运行 benchmark suite,请确保设置了适当的 batch_delay,将并发性的请求设置为与 batch size 成比例的数字。这里的并发性是指发送到服务器的并发请求的数量。
总结
本文介绍了 TorchServe 在生产环境中调优模型的注意事项及性能优化方法 TorchServe benchmark suite,使用户对模型优化、硬件选择和总体成本的可能选择有了更深入的了解。
关注 PyTorch 开发者社区公众号,获取更多 PyTorch 技术更新、最佳实践及相关资讯!








