HyperAI
Command Palette
Search for a command to run...
Zebra-CoT 文本图像推理数据集
Zebra-CoT 是由哥伦比亚大学、马里兰大学、南加州大学和纽约大学于 2025 年联合发布的一个视觉语言推理数据集,相关论文成果为「Zebra-CoT: A Dataset for Interleaved Vision Language Reasoning」,旨在推动模型更好地理解图像与文本之间的逻辑关系,广泛应用于视觉问答、图像描述生成等领域,帮助提升推理能力和准确性。 该数据集包含 182,384 个样本,涵盖 4 个主要类别:科学推理、二维视觉推理、三维视觉推理以及视觉逻辑与策略游戏,这些样本包含逻辑连贯的交错文本-图像推理轨迹。
数据集结构:
- 问题描述:问题的文本描述。
- 问题图像:根据问题的性质,可能伴随零个或多个图像。
- 推理图像:在解决问题过程中,至少有一个或多个支持中间推理步骤的视觉辅助工具。
- 文本推理轨迹:一系列文本思考以及相应的视觉草图或图表占位符。
- 最终答案:问题的解决方案。
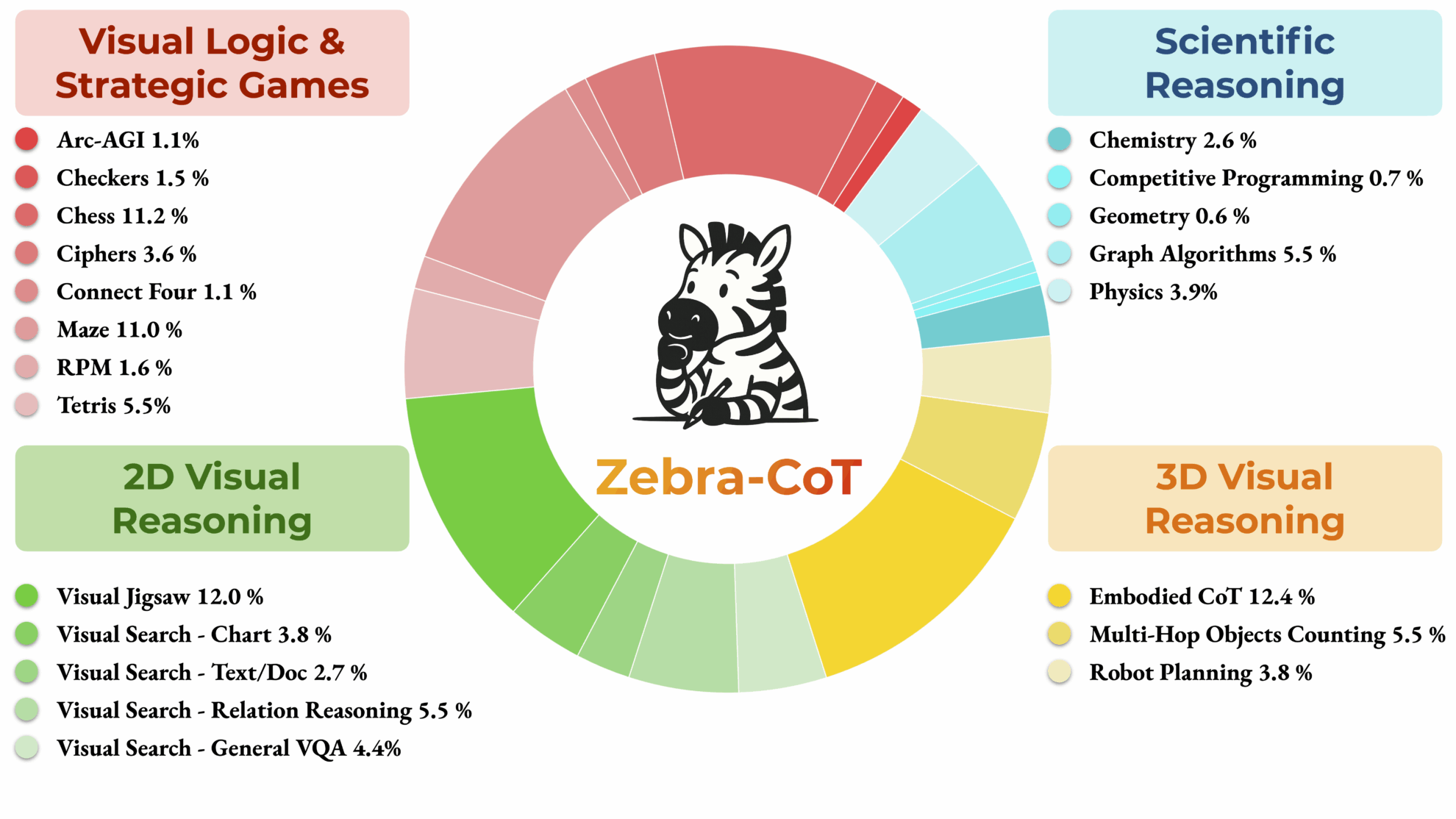
数据集领域分布图
Zebra-CoT.torrent
做种 1正在下载 0已完成 50总下载量 169
此数据集由社区用户贡献,仅用于教育和信息目的。如有任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。