Command Palette
Search for a command to run...
MINT-1T 文本图像对多模态数据集
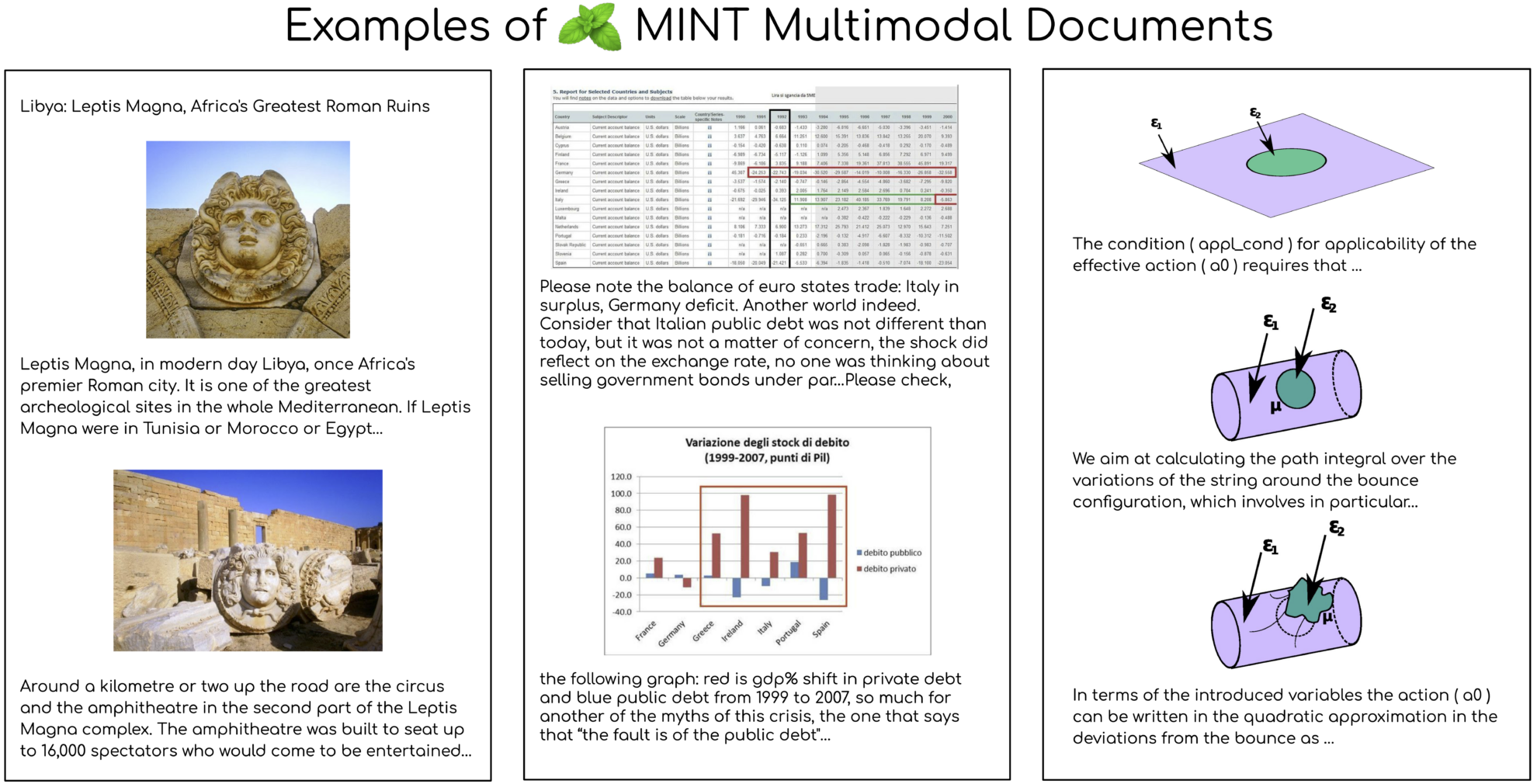
MINT-1T 数据集是由 Salesforce AI 联合多个机构于 2024 年共同开源的一个多模态数据集,它在规模上实现了显著的扩展,达到了一万亿个文本标记和 34 亿张图像,这一规模是之前最大开源数据集的 10 倍,相关论文成果为「MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset with One Trillion Tokens」。这个数据集的构建遵循了规模和多样性的核心原则,它不仅包括了 HTML 文档,还涵盖了 PDF 文档和 ArXiv 论文,这样的多样性显著提升了科学文档的覆盖率。 MINT-1T 的数据来源多样,包括但不限于网页、学术论文和文档,这些来源之前在多模态数据集中尚未被充分利用。
在模型实验方面,MINT-1T 上预训练的 XGen-MM 多模态模型在图像说明和视觉问答基准测试中表现出色,超越了之前的领先数据集 OBELICS 。通过分析,MINT-1T 在规模、数据来源多样性和质量上都有显著提升,特别是在 PDF 和 ArXiv 文档中,这些文档的平均长度明显更长,且图像密度更高。此外,通过 LDA 模型对文档进行主题建模的结果显示,MINT-1T 的 HTML 子集表现出更广泛的领域覆盖,而 PDF 子集则主要集中在科学和技术领域。
MINT-1T 在多个任务上展现了优异的性能,尤其是在科学和技术领域,这得益于 ArXiv 和 PDF 文档中这些领域的流行。评估模型在使用不同数量的示例时的上下文学习性能,基于 MINT-1T 训练的模型在所有示例数量上都优于基线模型 OBELICS 。 MINT-1T 的发布,不仅为研究人员和开发者提供了一个庞大的多模态数据集,也为多模态模型的训练和评估提供了新的挑战和机遇。