Command Palette
Search for a command to run...
GMAI-MMBench 医疗多模态评估基准数据集
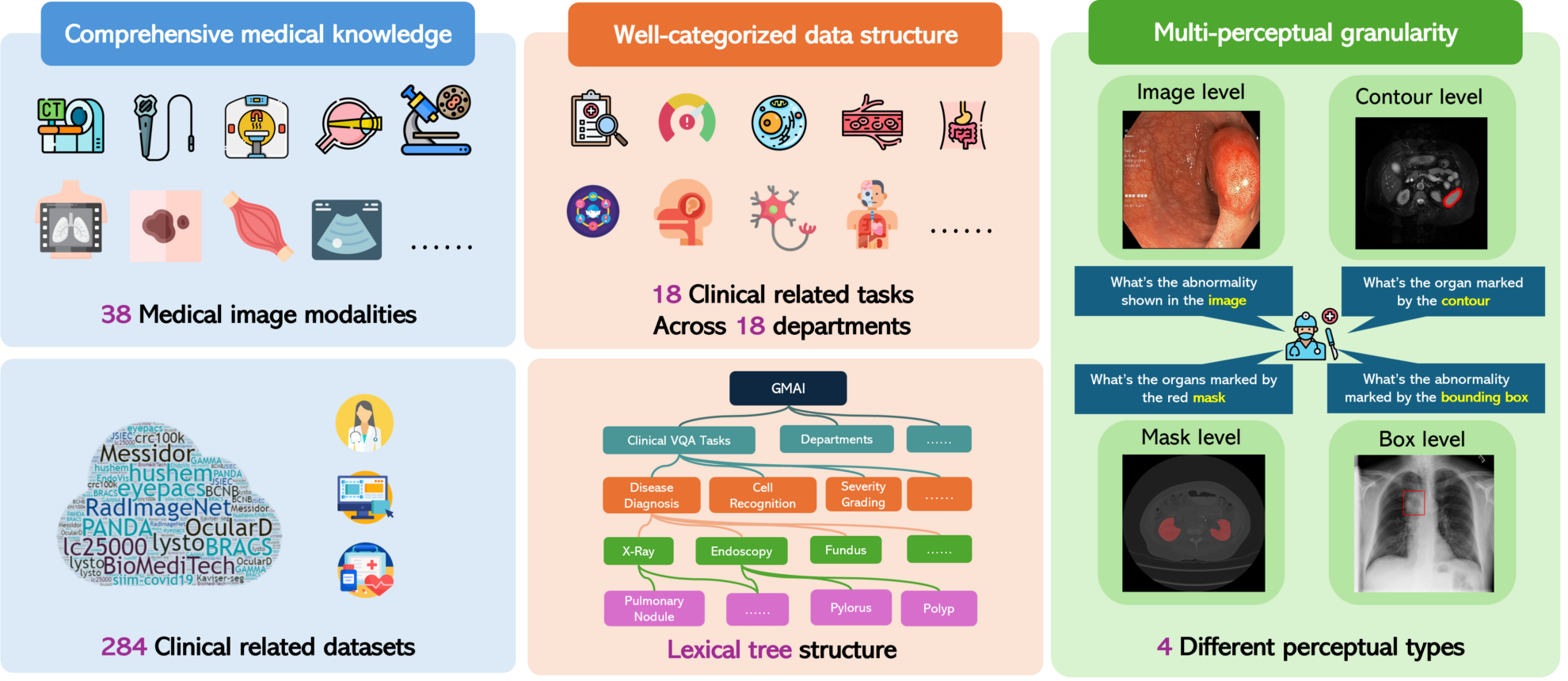
GMAI-MMBench 是一个为推动通用医疗人工智能领域发展而设计的多模态评估基准,由来自上海人工智能实验室、华盛顿大学、莫纳什大学、华东师范大学、剑桥大学、上海交通大学、香港中文大学(深圳)、深圳市大数据研究院和中国科学院深圳先进技术研究院 9 个机构于 2024 年联合推出,相关论文成果为「GMAI-MMBench: A Comprehensive Multimodal Evaluation Benchmark Towards General Medical AI」。它通过提供全面和细致的评估,帮助研究者和开发者深入了解大型视觉语言模型 (LVLMs) 在医疗领域的应用效果,并识别技术短板。这个基准测试覆盖了广泛的数据集,包含 284 个不同来源的数据集,涉及 38 种医学图像模态和 18 个临床相关任务,覆盖了 18 个不同的医学部门,并在 4 种不同的感知粒度上进行了评估,从而从多个维度对 LVLMs 的性能进行考量。 GMAI-MMBench 的一个显著特点是其对多感知粒度的评估,它不仅关注于图像整体级别的评估,还深入到区域级别,提供了更为细致和全面的评估视角。此外,由于数据集主要来源于医院并由专业医生进行标注,GMAI-MMBench 的评估任务更贴近真实的临床场景,具有高度的临床相关性。这种相关性使得基准测试的结果对于实际医疗应用具有指导意义。 GMAI-MMBench 还允许用户自定义评估任务,通过实现词汇树结构,用户可以根据自己的需求来定义评估任务,这为医学 AI 研究和应用提供了灵活性。研究团队通过评估 50 个 LVLMs,包括一些先进的 GPT-4o 模型,发现即使是最先进的模型在处理医疗专业问题上也仅达到了 52% 的准确率,这表明当前的 LVLMs 在医疗领域的应用上还有很大的提升空间。 GMAI-MMBench 的开发为评估和提升 LVLMs 在医疗领域的应用提供了宝贵的资源,同时也揭示了当前技术面临的挑战,为未来的研究指明了方向。
Citation
@misc{chen2024gmaimmbenchcomprehensivemultimodalevaluation,
title={GMAI-MMBench: A Comprehensive Multimodal Evaluation Benchmark Towards General Medical AI},
author={Pengcheng Chen and Jin Ye and Guoan Wang and Yanjun Li and Zhongying Deng and Wei Li and Tianbin Li and Haodong Duan and Ziyan Huang and Yanzhou Su and Benyou Wang and Shaoting Zhang and Bin Fu and Jianfei Cai and Bohan Zhuang and Eric J Seibel and Junjun He and Yu Qiao},
year={2024},
eprint={2408.03361},
archivePrefix={arXiv},
primaryClass={eess.IV},
url={https://arxiv.org/abs/2408.03361},
}