Command Palette
Search for a command to run...
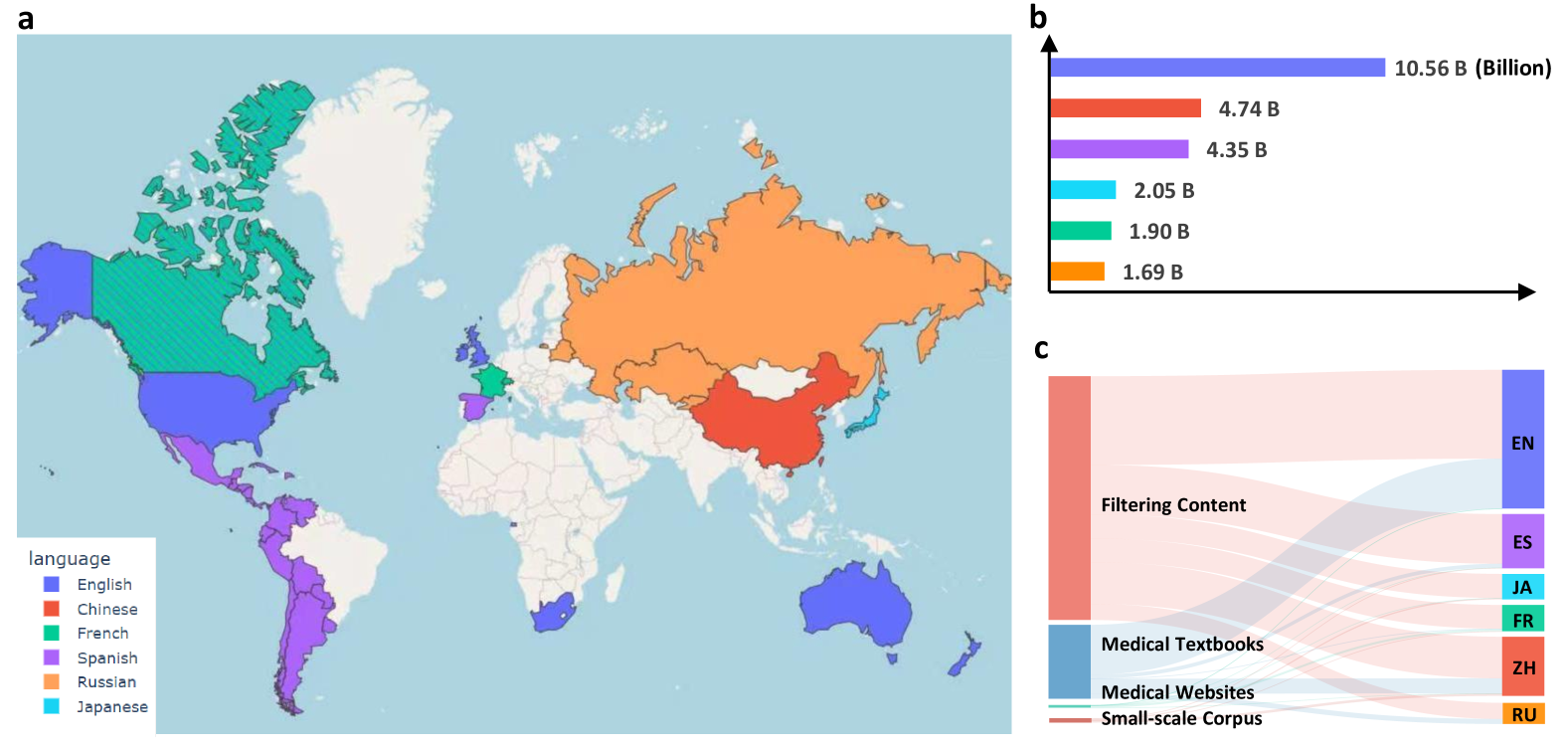
MMedC 大规模多语言医疗语料库
大规模多语医疗语料 (MMedC) 是一个由上海交通大学人工智能学院智慧医疗团队于 2024 年构建的多语言医疗语料库,它包含了约 255 亿个 tokens,涵盖了 6 种主要语言:英语、中文、日语、法语、俄语和西班牙语。这个数据集的构建是为了推动多语言医学大语言模型的发展,它覆盖了全球大部分地区,并且对更多语言的支持仍在不断更新和扩展中。相关论文成果为「Towards Building Multilingual Language Model for Medicine」,已发表于《nature communications》。 MMedC 的数据来源主要包括 4 个方面:首先,通过启发式算法从大规模通用文本数据库中(例如 CommonCrawl)筛选出医学相关内容;其次,使用光学字符识别技术(OCR)从医学教科书中提取文本;再者,从多国的官方许可医疗网站上爬取数据;最后,整合了一些现有的小规模医疗数据集。 此外,为了评估医学领域多语言模型的发展,研究团队还设计了一项全新的多语言选择题问答评测标准,命名为 MMedBench 。 MMedBench 的所有问题均直接源自各国的医学考试题库,而非简单地通过翻译获得,避免了由于不同国家医疗实践指南差异导致的诊断理解偏差。在评测过程中,模型不仅需要选择正确的答案,还必须提供合理的解释,从而进一步测试模型理解和解释复杂医疗信息的能力,实现更全面的评估。 研究团队还开源了多语言医疗基座模型 MMed-Llama 3,该模型在多项基准测试中表现卓越,显著超越了现有的开源模型,特别适用于医学垂直领域的定制微调。所有数据和代码均已开源,进一步促进了全球研究社区的合作和技术共享。 MMedC 的构建和开源,为多语言医学语言模型的训练和评估提供了丰富而高质量的数据支持,有助于解决语言障碍和医疗资源全球化的问题,展现了在医疗领域应用的巨大潜力。