HyperAI
Command Palette
Search for a command to run...
VEGA 科学论文图文数据理解数据集
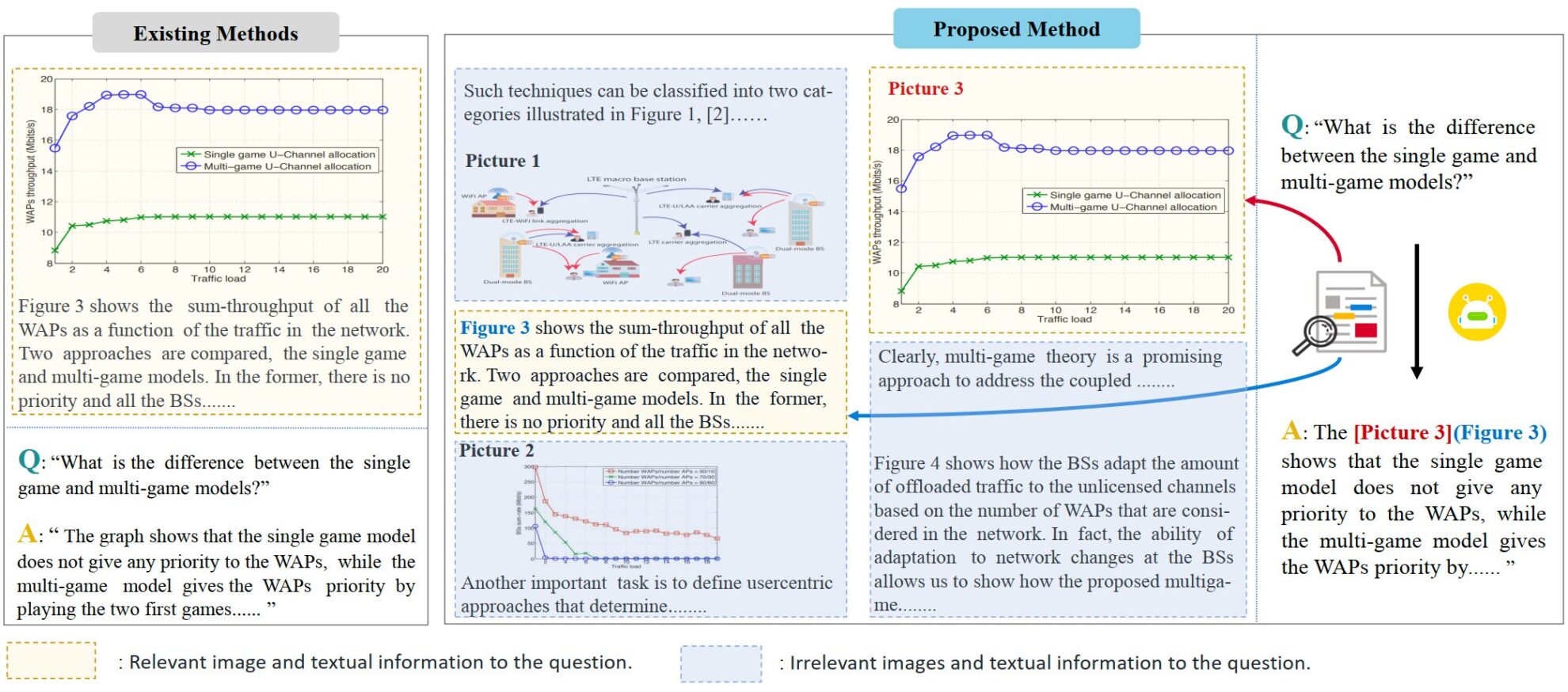
VEGA 是一个专注于科学论文理解的多模态数据集,它由厦门大学纪荣嵘团队于 2024 年提出,并被设计用于评估和提升模型在处理包含复杂图文交错信息的输入时的表现,相关论文为「VEGA : Learning Interleaved Image-Text Comprehension in Vision-Language Large Models」。该数据集包含超过 50,000 篇科学论文的图文数据,并且特别为交错图文阅读理解(Interleaved Image-Text Comprehension, IITC)任务而构建。 VEGA 数据集的构建过程包括问题筛选、上下文构建和答案修改三个步骤,旨在提供更长、更复杂的图文交错内容作为输入,并要求模型在回答时指明参考的图片 VEGA 源自 SciGraphQA 数据集,后者是一个论文图片理解任务的数据集,包含 295k 个问答对,研究团队在其基础上进行了问题筛选、上下文构建、答案修改三个步骤,得到 VEGA 数据集。包含 593,000 条论文类型训练数据,2 个不同任务的 2,326 条测试数据,旨在提供更长、更复杂的图文交错内容作为输入,并要求模型在回答时指明参考的图片。
- 问题筛选:原数据集中部分问题缺乏明确的图片指向,当将输入的信息拓展到多图时会造成理解的混淆。
- 上下文构建:原数据集中问答仅针对一张图片,且提供的上下文信息较少。为了拓展文本和图片的数量,研究团队在 arxiv 上下载了相关论文的源文件,并构建了 4k token 和 8k token 两个长度的数据,每个问答对包含至多 8 张图片。
- 答案修改:作者修改了原数据集中的答案,指明了回答时参考的图片,以符合 IITC 任务的要求。
VEGA.torrent
做种 1正在下载 0已完成 220总下载量 299
此数据集由社区用户贡献,仅用于教育和信息目的。如有任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。