Command Palette
Search for a command to run...
MMDU 超长多图多轮对话理解数据集
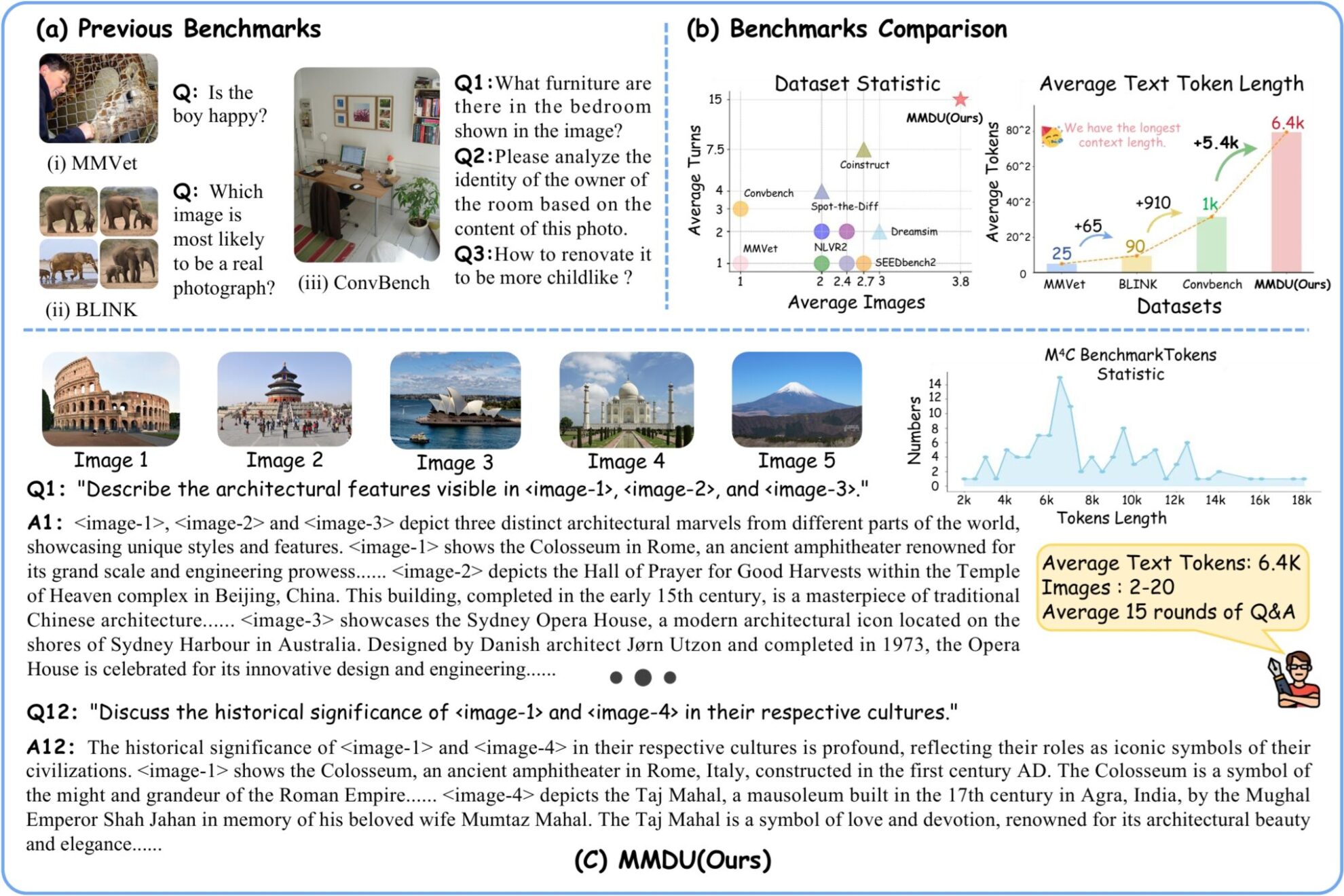
MMDU (Multi-Turn Multi-Image Dialog Understanding) 是超长多图多轮对话理解数据集,由武汉大学、上海人工智能实验室、香港中文大学和摩尔线程于 2024 年联合推出。研究团队在论文「MMDU: A Multi-Turn Multi-Image Dialog Understanding Benchmark and Instruction-Tuning Dataset for LVLMs」中提出了全新多图多轮评测基准 MMDU 及大规模指令微调数据集 MMDU-45k,旨在评估和提升 LVLMs 在多轮及多图像对话中的性能。 该基准包括 110 个高质量的多图像多轮对话,其中包含 1,600 多个问题,每个问题都附有详细的长篇答案。以前的基准通常只涉及单张图片或少量图片,问题轮次较少,答案简短。然而,MMDU 显著增加了图像数量、问答轮次以及问答的上下文长度。 MMUD 中的问题涉及 2 到 20 张图像,平均图像和文本标记长度为 8.2k 个标记,最大图像和文本长度达到 18K 个标记,对现有的多模态大型模型提出了重大挑战。 在 MMDU-45k 中,研究团队共构建了 45k 条指令调优数据对话。 MMDU-45k 数据集中每条数据都具有超长上下文,平均图文 token 长度为 5k,最大图文 token 长度为 17k 。每条对话平均包含 9 轮问答,最多 27 轮。此外,每条数据包含 2-5 张图片的内容。该数据集的构建格式经过精心设计,具有极佳的可扩展性,可通过组合生成更多数量、更长的多图多轮对话。 MMDU -45k 中的图文长度和轮数显著超越了所有现有的指令调优数据集。这一增强大大提高了模型在多图识别理解方面的能力,以及处理长上下文对话的能力。 MMDU 基准测试具有以下优势: **(1)多轮对话与多图像输入:**MMDU 基准测试最多包括 20 幅图像和 27 轮问答对话,从而超越了先前的多种 benchmark,并真实地复制了复现了现实世界中的聊天互动情景。 **(2)长上下文:**MMDU 基准测试通过最多 18k 文本+图像 tokens,评估 LVLMs 处理和理解带有长上下文历史的情况下理解上下文信息的能力。 **(3)开放式评估:**MMDU 摆脱传统基准测试依赖的 close-ended 问题和短输出(例如,多项选择题或简短的答案),采用了更贴合现实和精细评估的方法,通过自由形式的多轮输出评估 LVLM 的性能,强调了评估结果的可扩展性和可解释性。 在构建 MMDU 的过程中,研究者们从开源的维基百科中选取具有较高相关程度的图像及文本信息,并在 GPT-4o 模型的辅助下,由人工标注员构建问题和答案对。
Citation
@article{liu2024mmdu, title={MMDU: A Multi-Turn Multi-Image Dialog Understanding Benchmark and Instruction-Tuning Dataset for LVLMs}, author={Liu, Ziyu and Chu, Tao and Zang, Yuhang and Wei, Xilin and Dong, Xiaoyi and Zhang, Pan and Liang, Zijian and Xiong, Yuanjun and Qiao, Yu and Lin, Dahua and others}, journal={arXiv preprint arXiv:2406.11833}, year={2024} }