HyperAI
Command Palette
Search for a command to run...
HellaSwag 大模型常识推理数据集
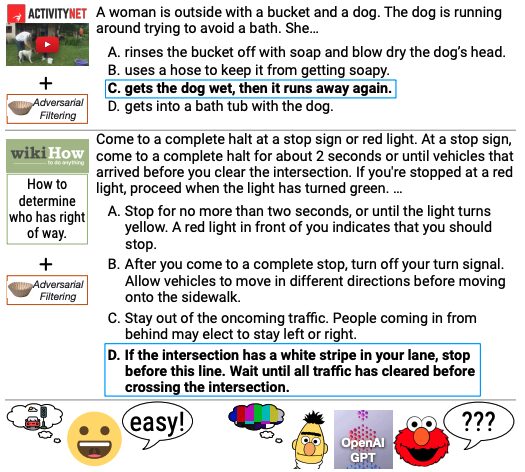
HellaSwag 数据集是一个用于测试常识性自然语言推理 (commonsense NLI) 的新挑战数据集。该数据集由华盛顿大学和 Allen AI 于 2019 年推出,旨在通过构建一个对现有最先进模型具有挑战性的数据集,来探索深度预训练模型在常识推理方面的表现。相关论文成果「HellaSwag: Can a Machine Really Finish Your Sentence?」已被 ACL 2019 接受。 HellaSwag 数据集包含 70,000 个问题,尽管这些问题对人类来说非常简单(准确率超过 95%),但即使是最先进的模型也难以达到接近人类水平的性能(准确率约为 48%)。该数据集通过对抗性过滤 (Adversarial Filtering, AF) 方法构建,该方法利用一系列判别器迭代选择机器生成的错误答案,以提高数据集的难度。 HellaSwag 的创建揭示了深度预训练模型的内部工作机制,并为 NLP 研究提供了一个新的发展方向,即基准测试与不断发展的最先进模型以对抗的方式共同演化,以提供更具挑战性的任务。
hellaswag.torrent
做种 1正在下载 0已完成 218总下载量 429
此数据集由社区用户贡献,仅用于教育和信息目的。如有任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。