HyperAI
Command Palette
Search for a command to run...
GITQA 多模态图推理问答数据集
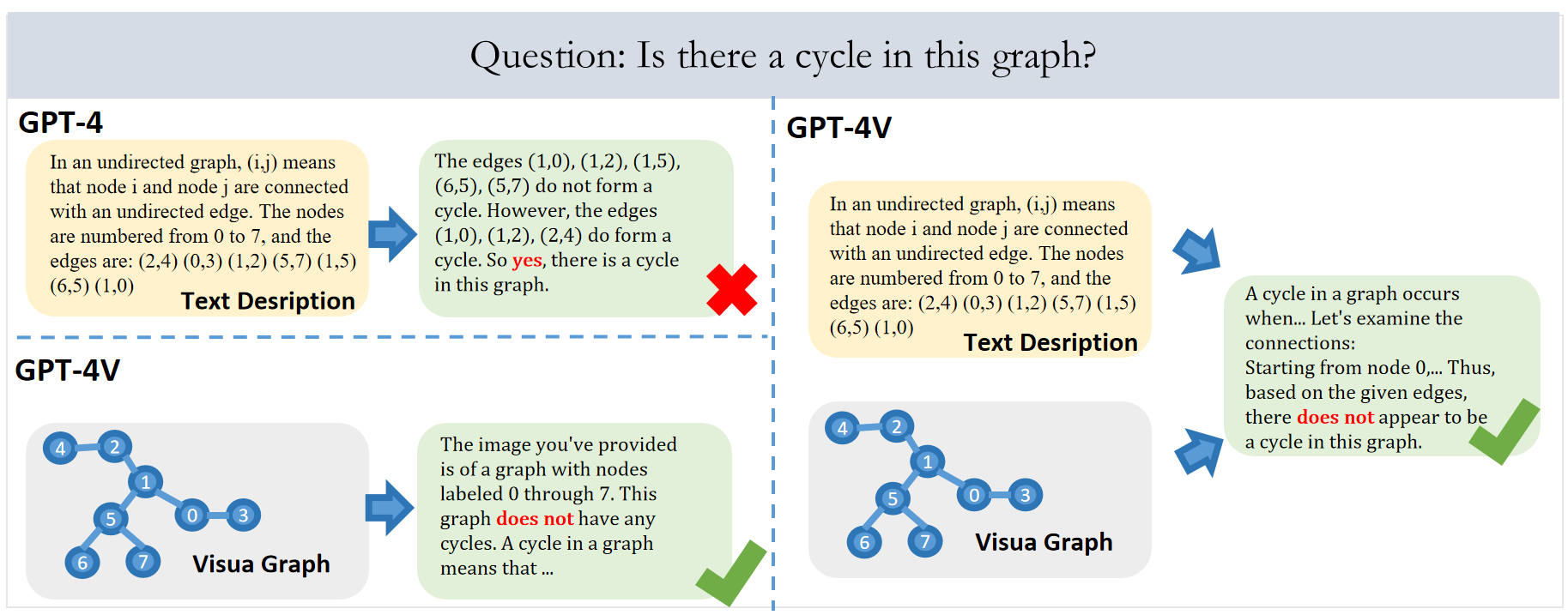
GITQA 是香港科技大学和南方科技大学,通过将图结构绘制为不同风格的视觉图像,构建的首个包含视觉图的推理问答数据集。该数据集包含超过 423K 个问答实例,每个实例包含相互对应的图结构-文本-视觉信息及其相应的问答对。 数据集包含两个版本:GITQA-Base 和 GITQA-Aug,其中 GITQA-Base 只包含单一风格的视觉图。 GITQA-Aug 则更加丰富,它对视觉图进行了多种数据增强处理,包括改变布局、点的形状、边的宽度和点的风格等,从而提供了更多样化的视觉图表现。该数据集可用于评估基于文字描述的 LLM 和基于多模态的 MLLM 在图推理任务上的性能,并研究视觉信息对图推理的影响。
此数据集由社区用户贡献,仅用于教育和信息目的。如有任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。