기울기 축적
그래디언트 축적은 신경망을 훈련하는 데 사용되는 샘플 배치를 순차적으로 실행되는 여러 개의 작은 샘플 배치로 나누는 메커니즘입니다.
그래디언트 축적에 대해 더 자세히 논의하기 전에 신경망의 역전파 과정을 검토하는 것이 좋습니다.
신경망의 역전파
딥 러닝 모델은 각 단계에서 샘플이 순방향 전파를 통해 전파되는 많은 상호 연결된 계층으로 구성됩니다. 네트워크는 모든 계층을 통과한 후 샘플에 대한 예측을 생성한 다음 각 샘플에 대한 손실 값을 계산합니다. 이 손실 값은 "네트워크가 해당 샘플에 대해 얼마나 잘못 판단했는지"를 나타냅니다. 그런 다음 신경망은 모델 매개변수를 기준으로 이러한 손실 값의 기울기를 계산합니다. 이러한 기울기는 다양한 변수에 대한 업데이트를 계산하는 데 사용됩니다.
모델을 구축할 때 손실을 최소화하는 데 사용되는 알고리즘을 담당하는 최적화 프로그램을 선택합니다. 최적화 프로그램은 프레임워크(SGD, Adam 등)에 구현된 일반적인 최적화 프로그램 중 하나가 될 수도 있고, 원하는 알고리즘을 구현하는 사용자 정의 최적화 프로그램이 될 수도 있습니다. 그래디언트 외에도 최적화 프로그램은 학습률, 현재 단계 인덱스(적응 학습률의 경우), 모멘텀 등과 같은 더 많은 매개변수를 관리하고 사용하여 업데이트를 계산할 수 있습니다.
기술의 점진적 축적
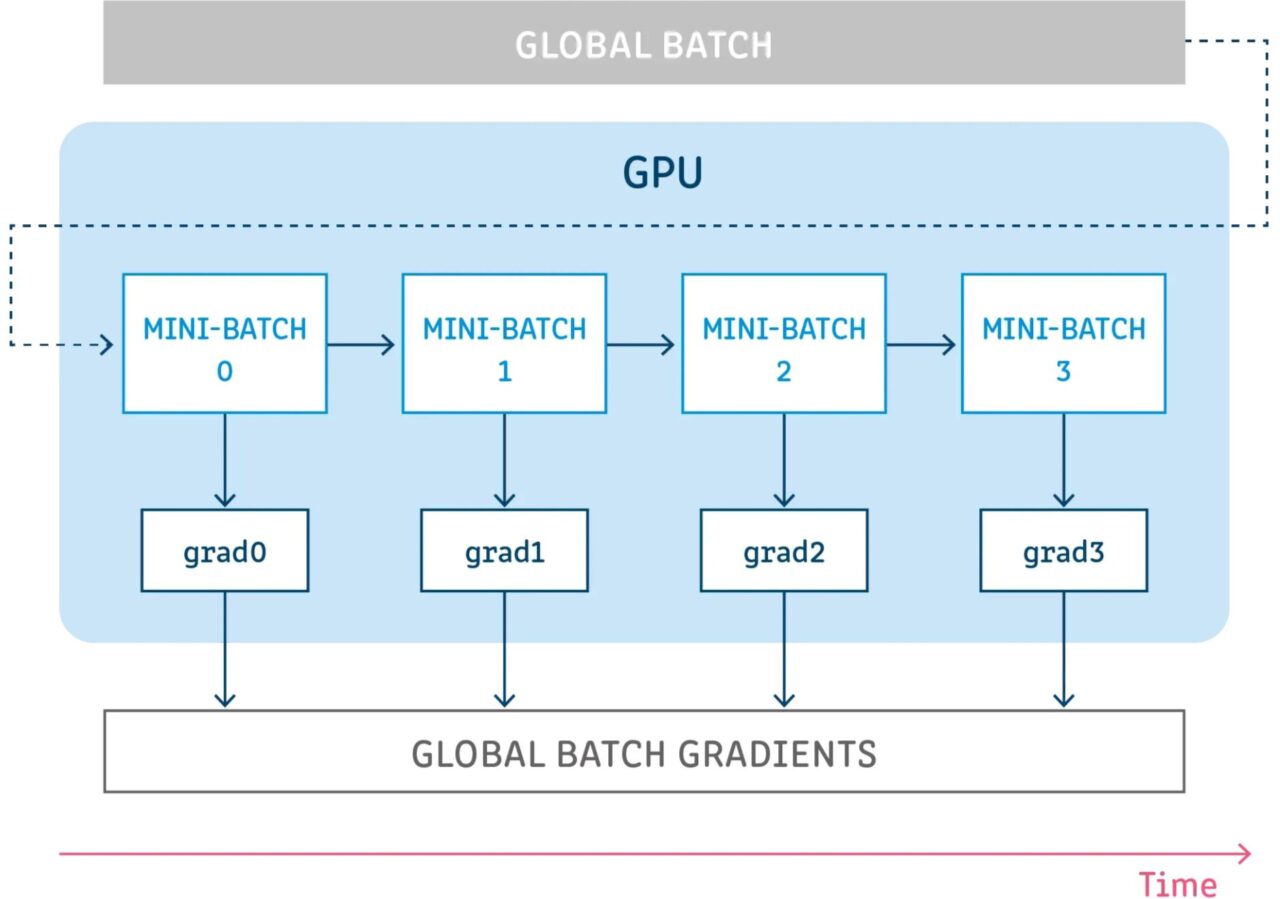
그래디언트 누적이란 모델 변수를 업데이트하지 않고 특정 단계 동안 구성을 실행하면서 해당 단계에서 그래디언트를 누적한 다음 누적된 그래디언트를 사용하여 변수 업데이트를 계산하는 것을 의미합니다.
모델 변수를 업데이트하지 않고 일부 단계를 실행하면 샘플 배치를 여러 개의 작은 배치로 논리적으로 분할할 수 있습니다. 각 단계에서 사용되는 샘플 배치는 실제로는 미니 배치이고, 모든 단계의 샘플을 합친 것은 실제로 글로벌 배치입니다.
모든 단계에서 변수를 업데이트하지 않으면 모든 미니 배치가 동일한 모델 변수를 사용하여 그래디언트를 계산합니다. 이는 글로벌 배치 크기가 사용된 것처럼 동일한 그래디언트와 업데이트가 계산되도록 보장하기 위한 필수적인 동작입니다.
모든 단계에서 기울기를 누적하면 동일한 기울기 합계가 생성됩니다.
참고문헌
【1】https://towardsdatascience.com/what-is-gradient-accumulation-in-deep-learning-ec034122cfa