NeuTTS-Air: 가볍고 효율적인 음성 복제 모델
1. 튜토리얼 소개

NeuTTS-Air는 Neuphonic이 2025년 10월에 출시한 종단간 음성 합성 모델(TTS)입니다. 0.5B Qwen LLM 백본과 NeuCodec 오디오 코덱을 기반으로 하며, 온디바이스 배포 및 즉각적인 음성 복제에서 퓨샷 학습(Few-Shot Learning) 기능을 보여줍니다. 시스템 평가 결과, NeuTTS-Air는 오픈소스 모델 중 SOTA 수준에 도달했으며, 특히 초현실적 합성 및 실시간 추론 벤치마크에서 우수한 성능을 보였습니다. 또한 임베디드 에이전트 및 스타일 전송과 같은 새로운 시나리오로 일반화하고, 3초 오디오 복제를 지원하며, 자연스러운 대화 콘텐츠를 생성할 수 있습니다. 사후 학습에서는 GGML/ONNX 지원 및 워터마킹 메커니즘을 도입하여 온디바이스 TTS 및 전력 최적화 평가 분야에서 오픈소스 분야를 선도하고 있으며, 일부 시나리오는 클로즈드 소스 모델과 유사합니다.
이 튜토리얼에서는 리소스로 단일 RTX 5090 카드를 사용하며, 모델은 영어만 지원합니다.
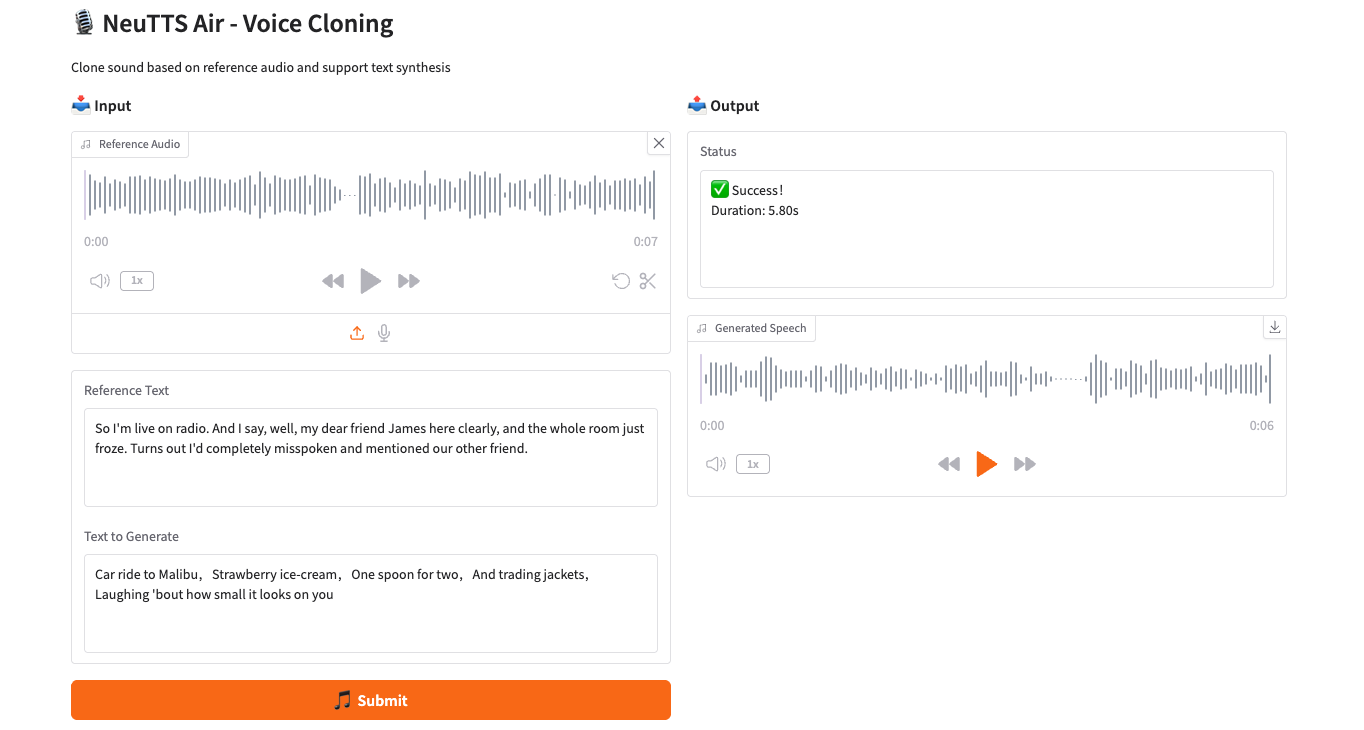
2. 프로젝트 예시
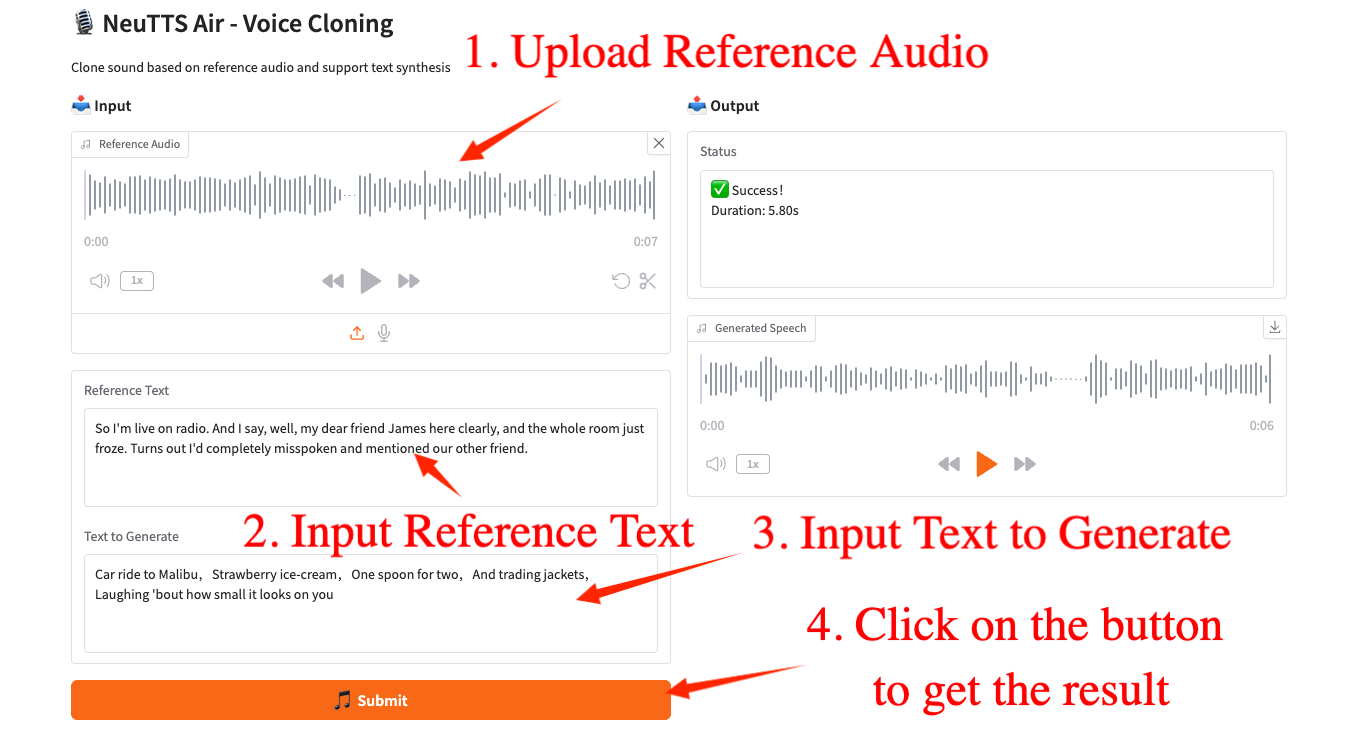
3. 작업 단계
1. 컨테이너 시작 후 API 주소를 클릭하여 웹 인터페이스로 진입합니다.
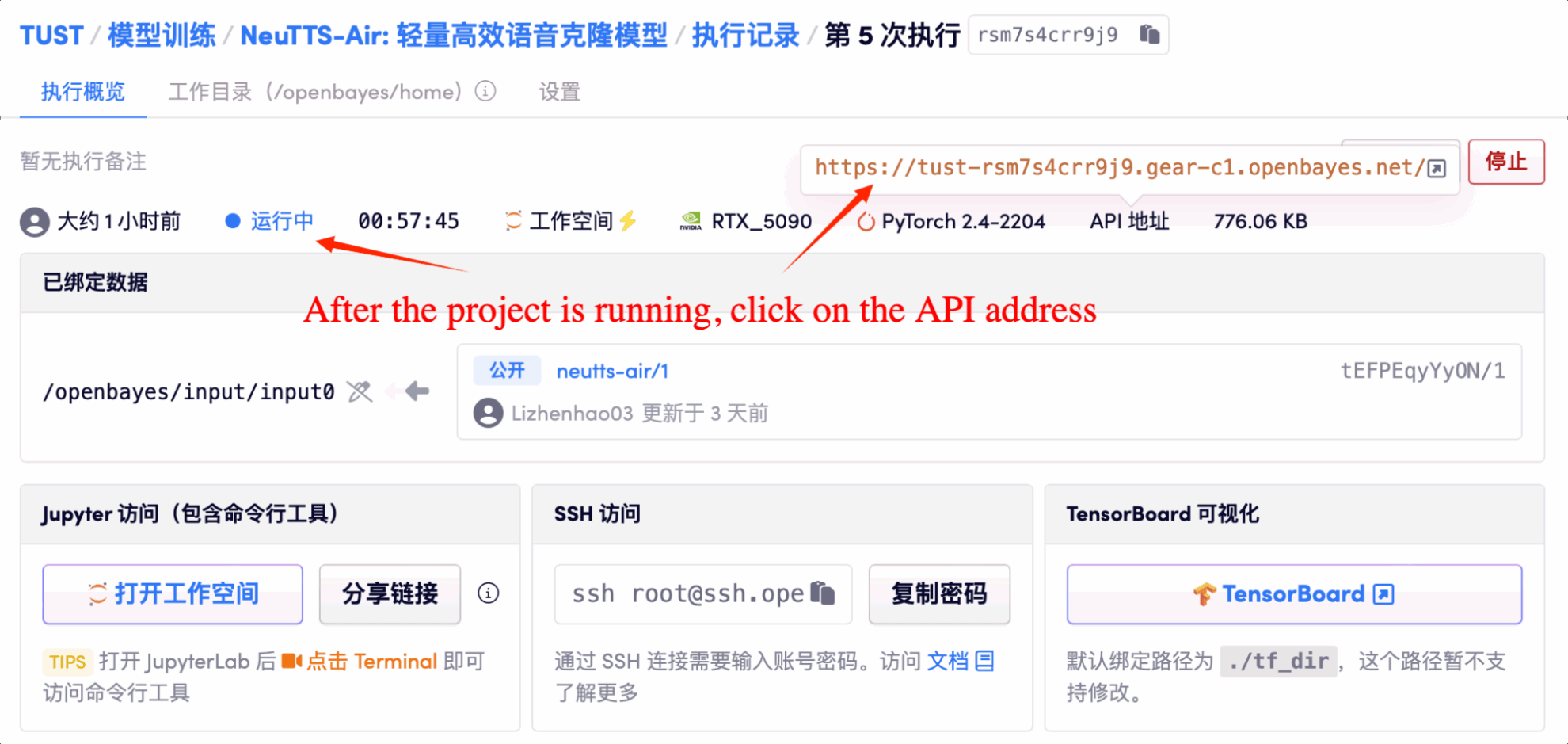
2. 웹페이지에 접속하시면 모델을 이용하실 수 있습니다.
"잘못된 게이트웨이"가 표시되면 코드가 백그라운드에서 실행 중임을 의미합니다. 약 2~3분 정도 기다린 후 페이지를 새로고침하세요.
Safari 브라우저를 사용하는 경우 오디오가 직접 재생되지 않을 수 있으며, 재생하기 전에 다운로드해야 합니다.
사용 방법