Command Palette
Search for a command to run...
VoxCPM: 단어 분할 없는 TTS 기술
1. 튜토리얼 소개
VoxCPM은 2025년 9월 면비 인텔리전스와 칭화대학교 선전 국제대학원이 공동 개발한 0.5B 매개변수 음성 생성 모델입니다. 업계 최고 수준의 자연스러움, 음색 유사성, 그리고 음성 합성의 운율적 표현력을 구현합니다. VoxCPM은 종단간 확산 자기회귀 아키텍처를 활용하여 텍스트에서 직접 연속적인 음성 표현을 생성함으로써 기존 이산 단어 분할의 한계를 뛰어넘습니다. 계층적 언어 모델링과 유한 상태 양자화 제약 조건을 통해 의미론과 음향학의 암묵적 분리를 실현하여 음성의 표현력과 생성 안정성을 크게 향상시킵니다. VoxCPM은 제로샷 음성 복제를 지원하여 단 하나의 참조 오디오 클립만으로 화자의 음색, 악센트, 감정적 억양 및 기타 특징을 정확하게 복제하여 매우 사실적인 음성을 생성합니다.
이 튜토리얼에서 사용된 컴퓨팅 리소스는 RTX 4090 카드 1개입니다.
2. 효과 표시
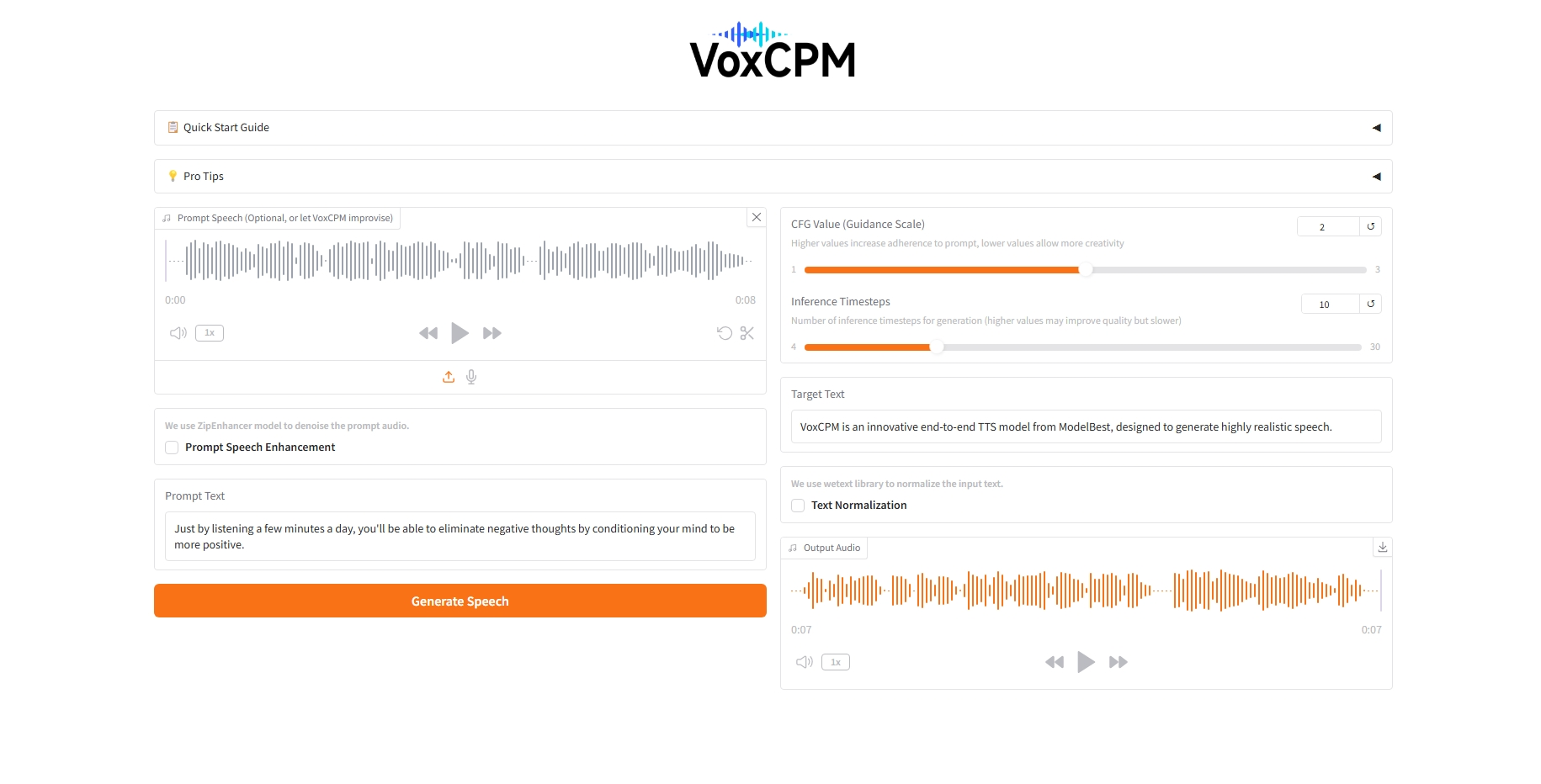
3. 작업 단계
1. 컨테이너를 시작하세요
"잘못된 게이트웨이"가 표시되면 모델이 초기화 중임을 의미합니다. 모델이 크기 때문에 약 2~3분 정도 기다리신 후 페이지를 새로고침해 주시기 바랍니다.
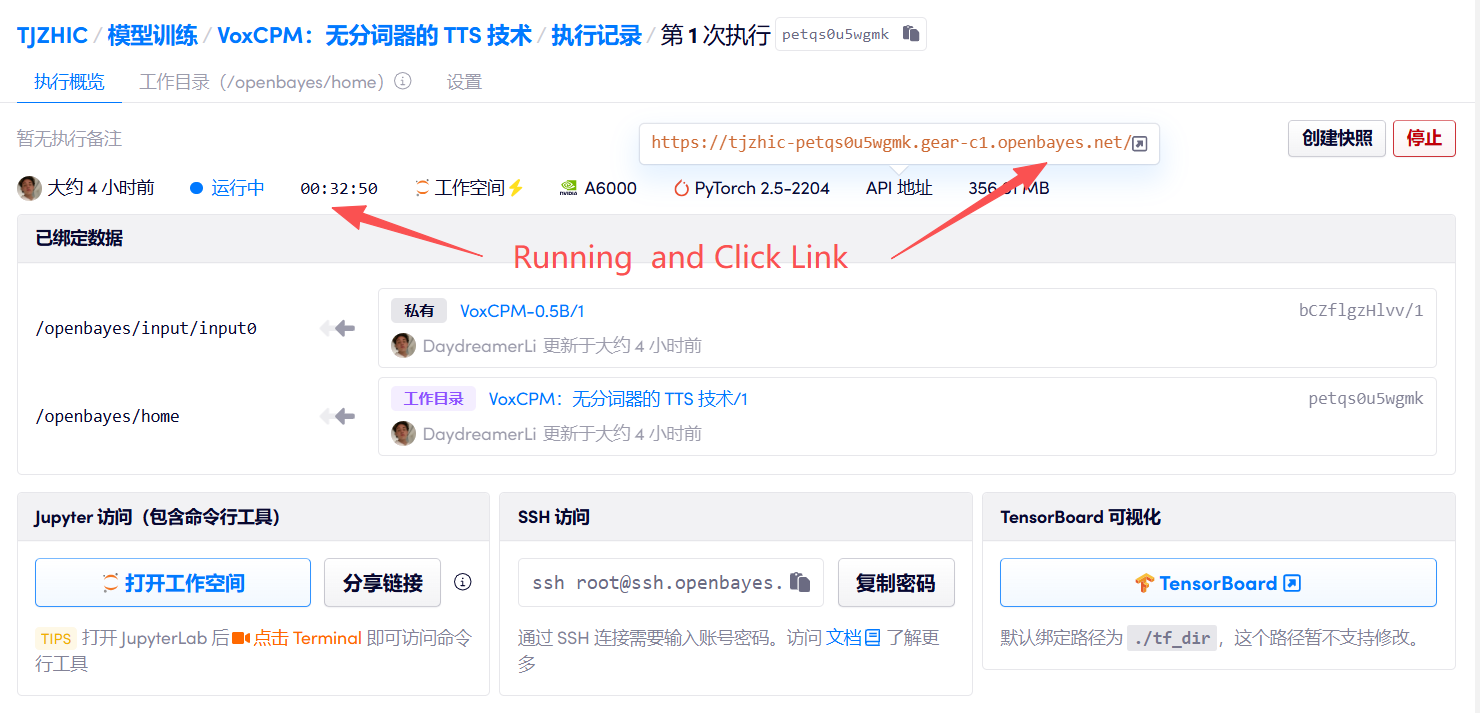
2. 사용 단계
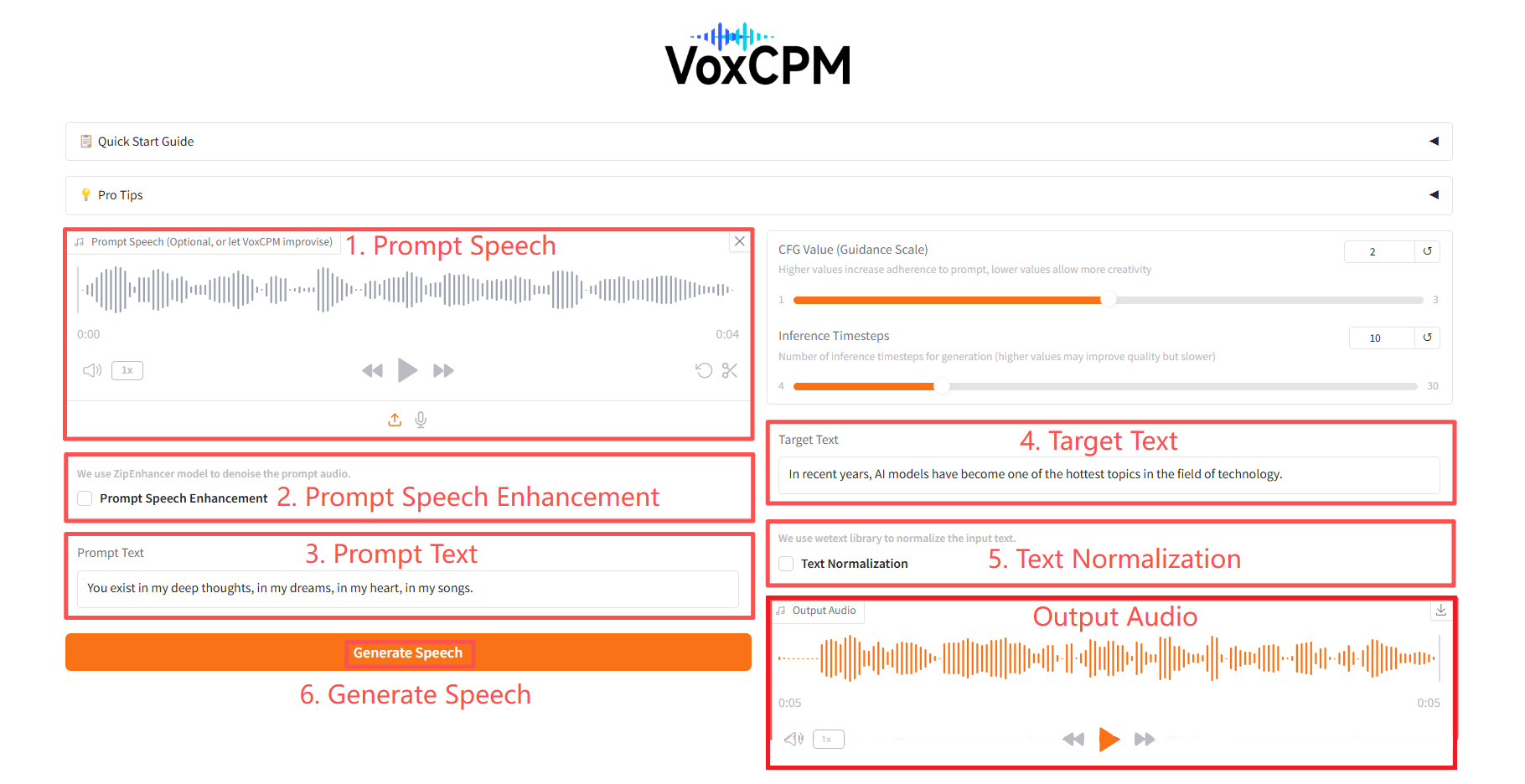
구체적인 매개변수:
- CFG 값: 값이 높을수록 프롬프트에 대한 준수성이 높고, 값이 낮을수록 창의성이 높습니다.
- 추론 타임스텝: 생성할 추론 타임스텝의 수(값이 높을수록 품질은 향상되지만 속도가 느려집니다).
- 프롬프트 음성 향상: ZipEnhancer 모델을 사용하여 프롬프트 오디오의 잡음을 제거합니다.
- 텍스트 정규화: wetext 라이브러리를 사용하여 입력 텍스트를 정규화합니다.
4. 토론
🖌️ 고품질 프로젝트를 발견하시면, 백그라운드에 메시지를 남겨 추천해주세요! 또한, 튜토리얼 교환 그룹도 만들었습니다. 친구들의 QR코드 스캔과 [SD 튜토리얼] 댓글을 통해 그룹에 가입하여 다양한 기술 이슈에 대해 논의하고 신청 결과를 공유해 주시기 바랍니다.↓

인용 정보
이 프로젝트에 대한 인용 정보는 다음과 같습니다.
@misc{voxcpm2025,
author = {{Yixuan Zhou, Guoyang Zeng, Xin Liu, Xiang Li, Renjie Yu, Ziyang Wang, Runchuan Ye, Weiyue Sun, Jiancheng Gui, Kehan Li, Zhiyong Wu, Zhiyuan Liu}},
title = {{VoxCPM}},
year = {2025},
publish = {\url{https://github.com/OpenBMB/VoxCPM}},
note = {GitHub repository}
}