Command Palette
Search for a command to run...
Pusa-VidGen 비디오 생성 모델 데모
1. 튜토리얼 소개

Pusa V1은 2025년 7월 25일 Yaofang-Liu 팀이 제안한 효율적인 멀티모달 비디오 생성 모델입니다. 벡터화된 시간 단계 적응(VTA)을 기반으로 높은 학습 비용, 낮은 추론 효율성, 낮은 시간 일관성 등 기존 비디오 생성 모델의 핵심 문제를 해결합니다. 방대한 데이터와 컴퓨팅 파워에 의존하는 기존 방식과 달리, Pusa V1은 가벼운 미세 조정 전략을 통해 Wan2.1-T2V-14B 기반 획기적인 최적화를 달성합니다. 학습 비용은 500달러(유사 모델의 200분의 1)에 불과하며, 데이터셋은 4K 샘플(유사 모델의 2500분의 1)만 필요합니다. 80GB GPU 8개로 학습을 완료할 수 있어 비디오 생성 기술의 진입 장벽을 크게 낮춥니다. 또한, 강력한 멀티태스킹 기능을 자랑하며, 텍스트 기반 비디오(T2V)와 이미지 기반 비디오(I2V)뿐만 아니라 비디오 완성, 첫 번째 및 마지막 프레임 생성, 장면 간 전환과 같은 제로샷 작업도 지원하여 장면별 추가 학습이 필요 없습니다. 더욱 중요한 것은 생성 성능이 특히 뛰어나다는 것입니다. 10단계 추론 전략을 채택하여 VBench-I2V의 총점은 87.32%에 달하며, 동적 디테일 복원(팔다리 움직임, 빛과 그림자 변화 등) 및 시간적 일관성 측면에서 탁월한 성능을 보입니다. 또한, VTA 기술이 구현한 비파괴 적응 메커니즘은 기본 모델에 시간적 동적 기능을 추가할 뿐만 아니라 원본 모델의 이미지 생성 품질을 유지하여 "1+1>2" 효과를 달성합니다. 배포 수준에서 추론 지연 시간이 낮아 빠른 미리보기부터 고화질 출력까지 다양한 요구를 충족할 수 있으며, 창의적인 디자인 및 짧은 영상 제작과 같은 시나리오에 적합합니다. 관련 논문 결과는 다음과 같습니다. PUSA V1.0: 벡터화된 타임스텝 적응을 통해 $500의 학습 비용으로 Wan-I2V를 능가 ".
이 튜토리얼에서는 듀얼 카드 RTX A6000 리소스를 사용합니다.
2. 프로젝트 예시
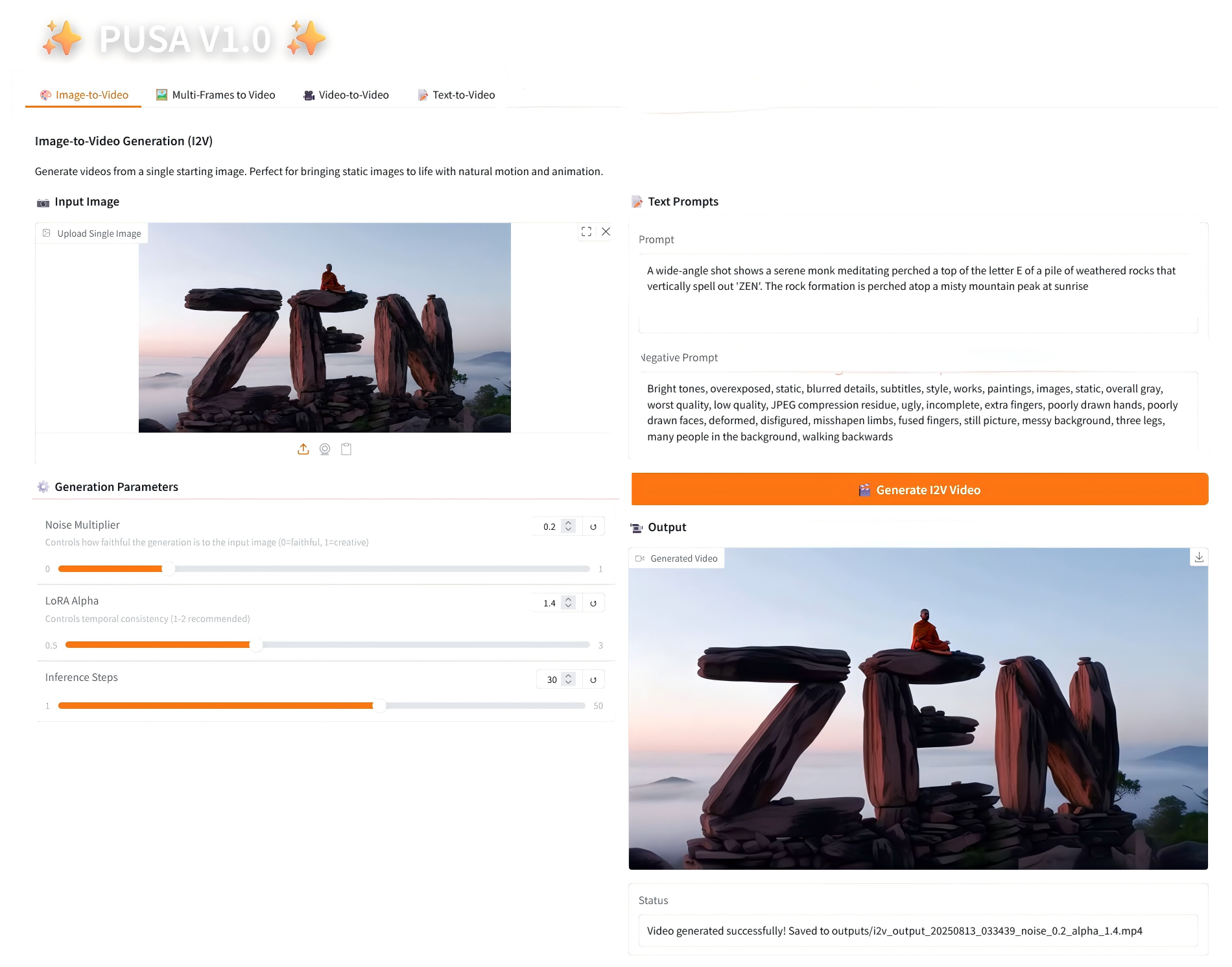
1. 이미지-비디오 변환
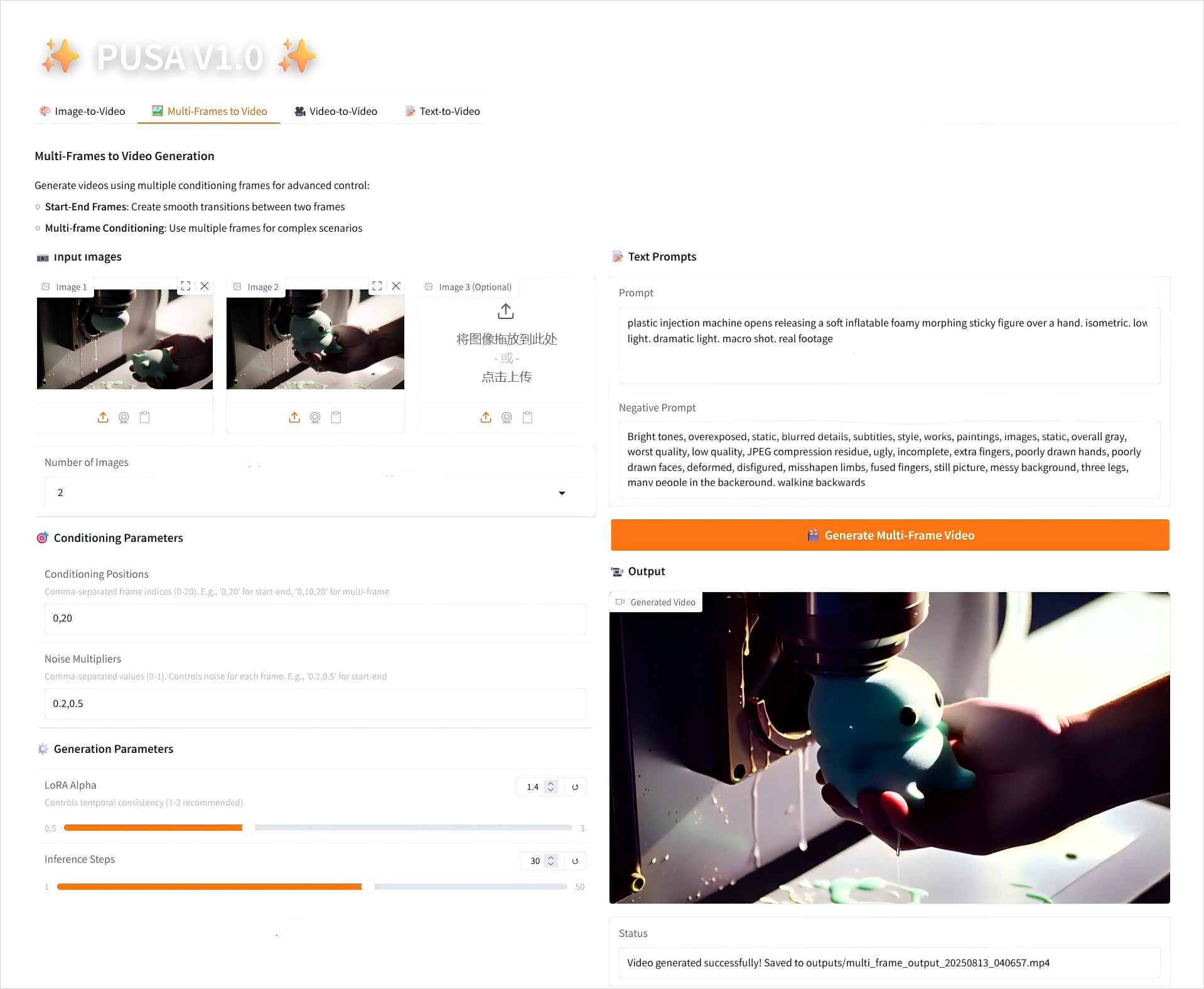
2. 비디오에 대한 다중 프레임
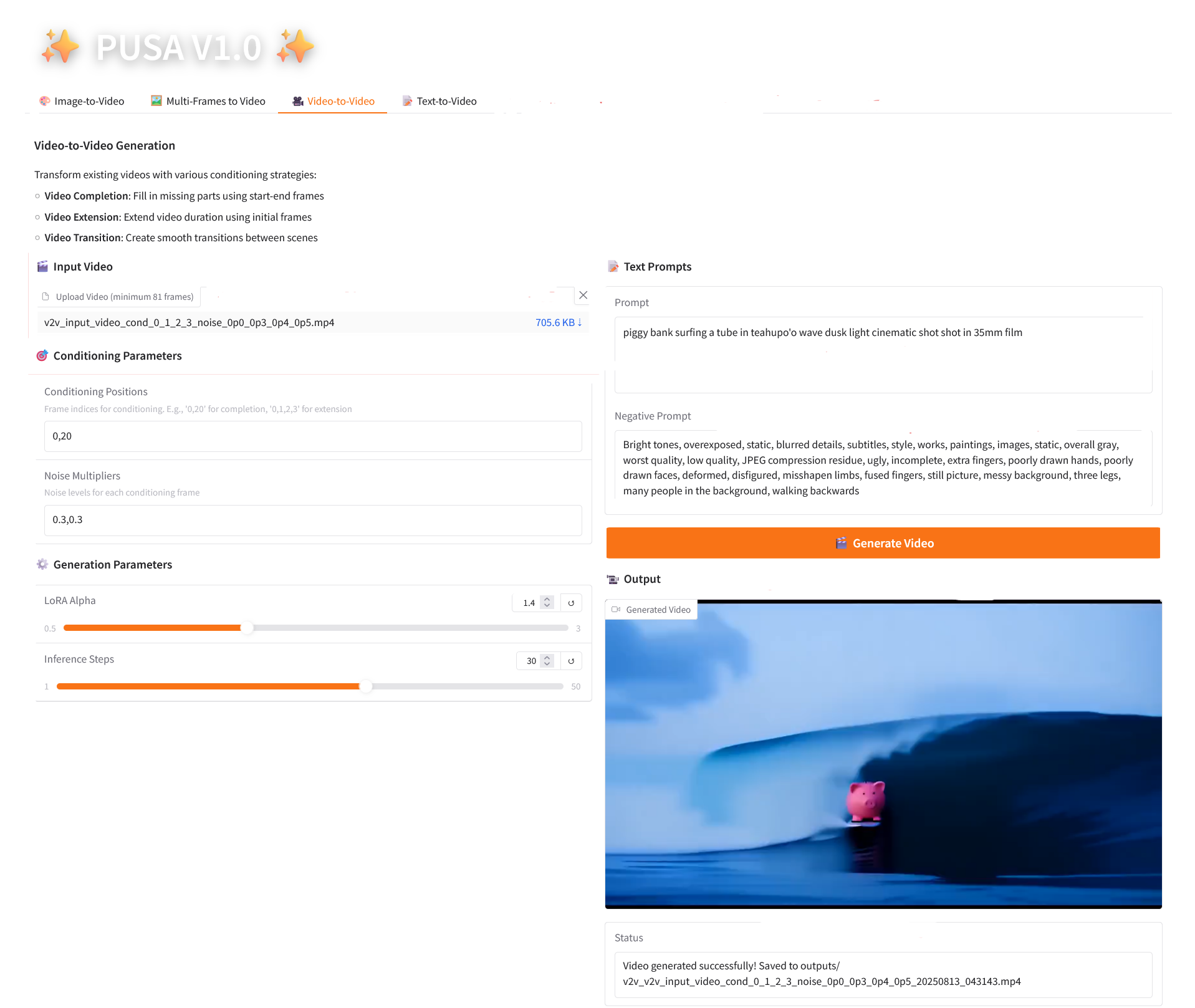
3. 비디오-비디오
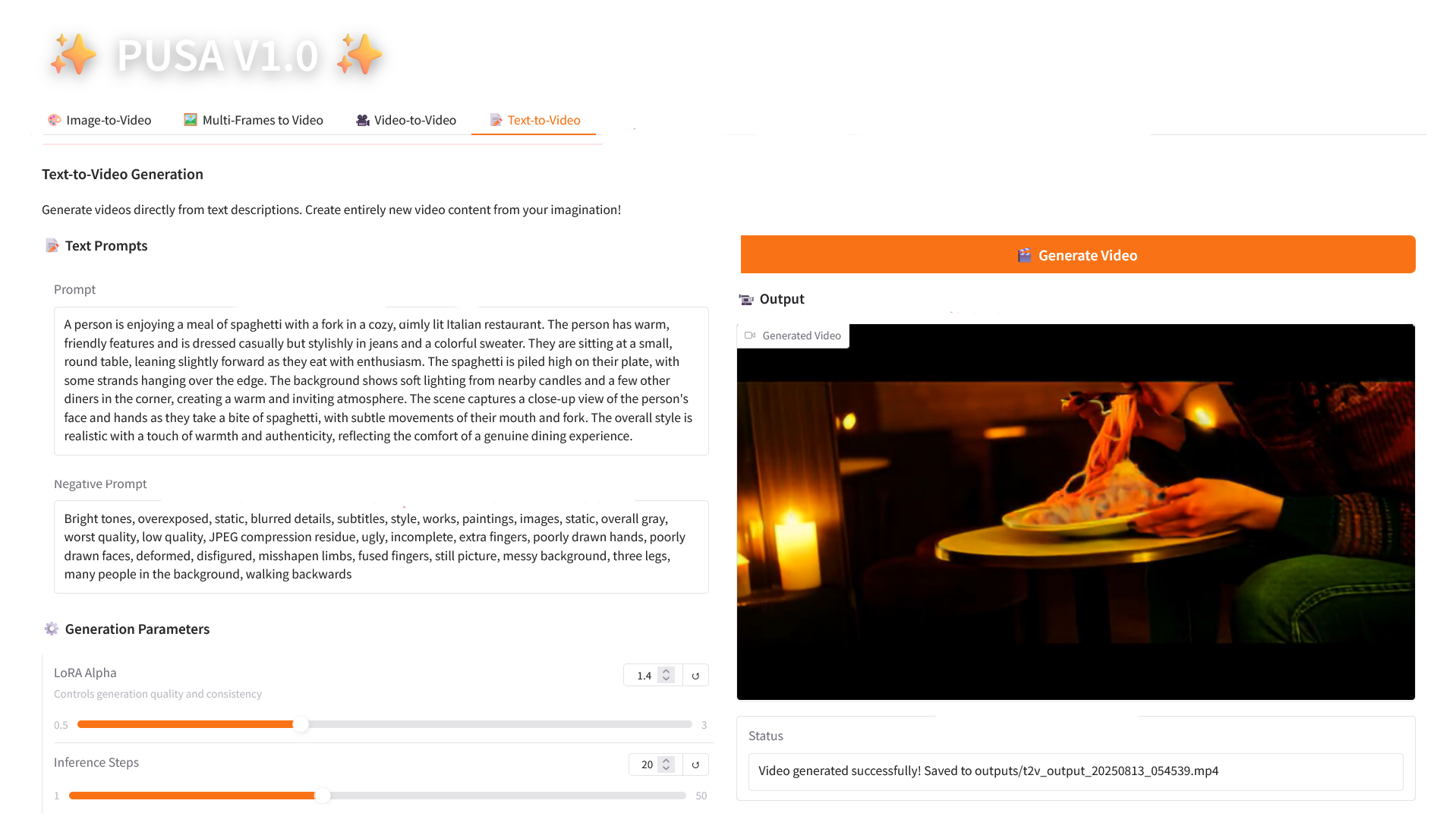
4. 텍스트-비디오 변환
3. 작업 단계
1. 컨테이너 시작 후 API 주소를 클릭하여 웹 인터페이스로 진입합니다.
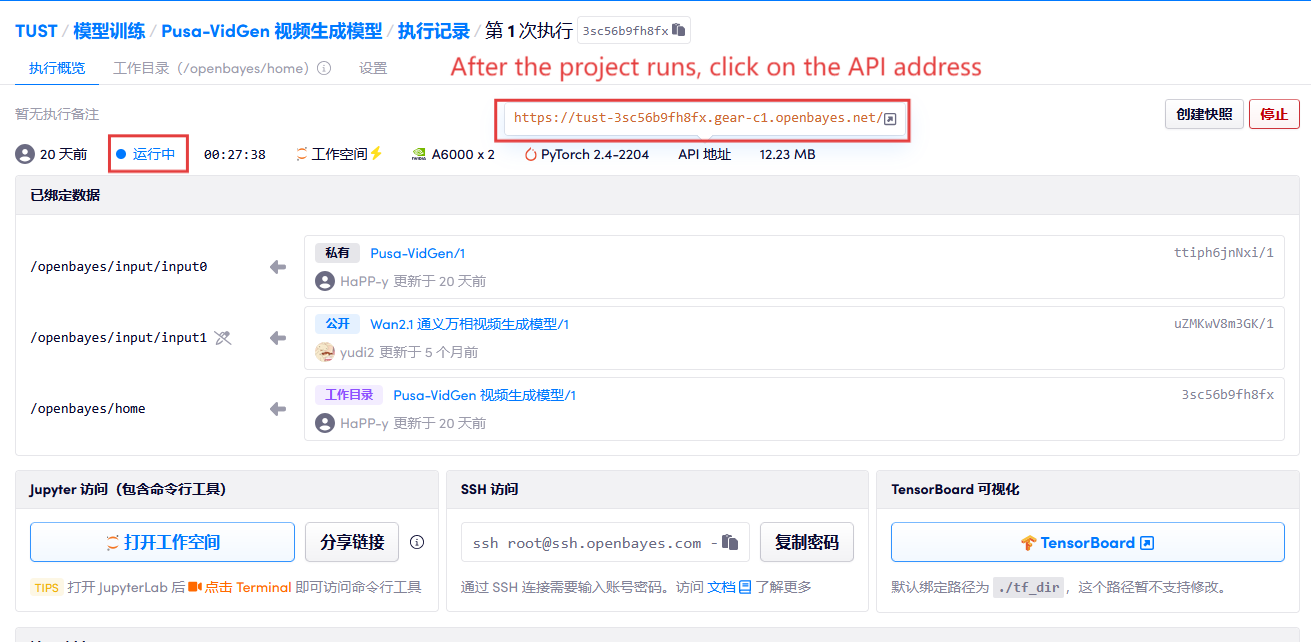
2. 사용 단계
"잘못된 게이트웨이"가 표시되면 모델이 초기화 중임을 의미합니다. 모델이 크기 때문에 약 2~3분 정도 기다리신 후 페이지를 새로고침해 주시기 바랍니다.
2.1 이미지-비디오 변환
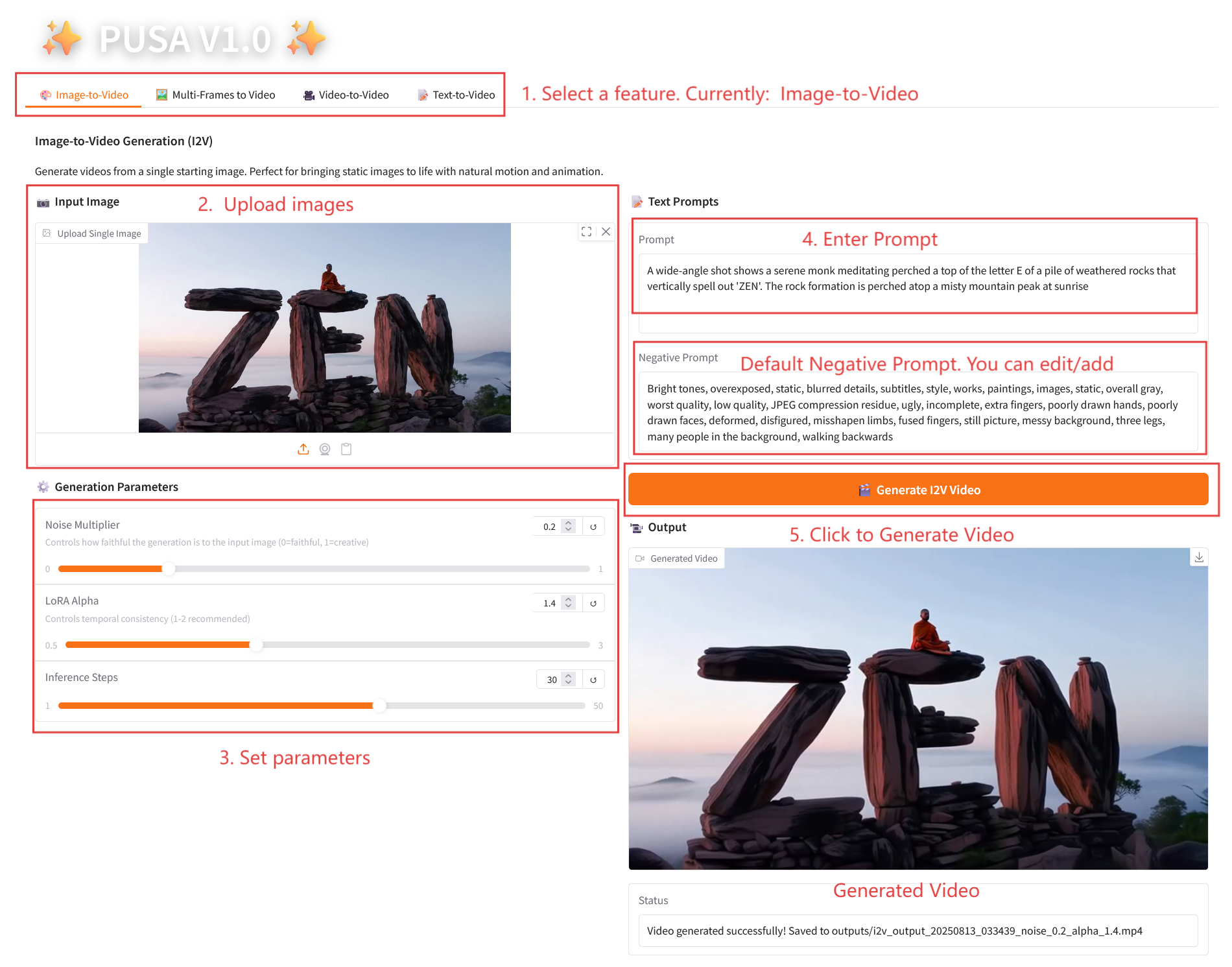
매개변수 설명
- 생성 매개변수
- 노이즈 배수: 0.0에서 1.0까지 조정 가능하며, 기본값은 0.2입니다(값이 낮을수록 입력 이미지에 더 충실하고, 값이 높을수록 더 창의적입니다).
- LoRA Alpha: 0.1에서 5.0까지 조정 가능, 기본값은 1.4(스타일의 일관성을 제어합니다. 너무 높으면 뻣뻣해지고, 너무 낮으면 일관성을 잃습니다).
- 추론 단계: 1에서 50까지 조정 가능하며, 기본값은 10입니다(단계 수가 높을수록 세부 정보가 풍부해지지만 시간 소모는 선형적으로 증가합니다).
2.2 비디오에 대한 다중 프레임
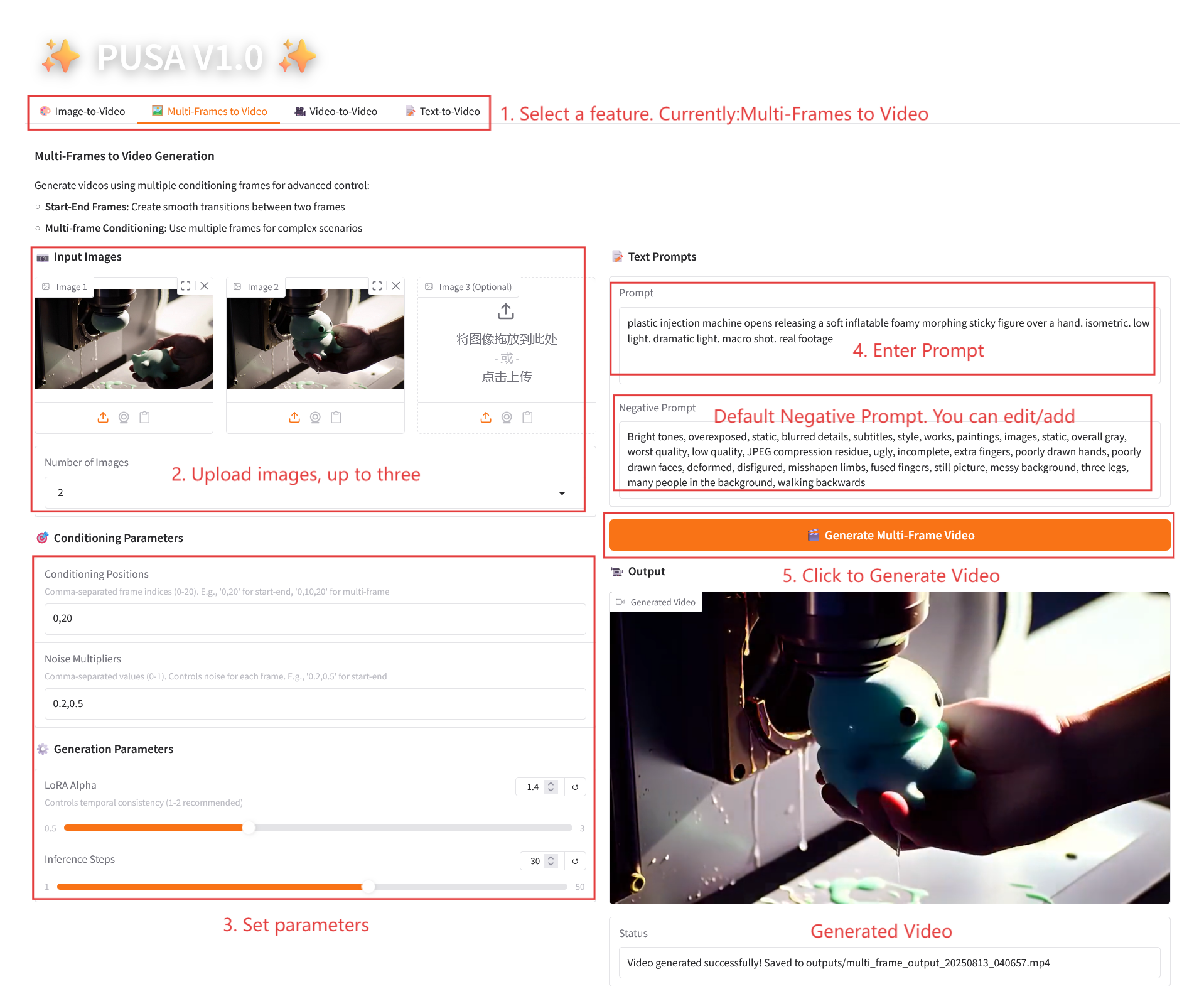
매개변수 설명
- 조건 매개변수
- 조건부 위치: 쉼표로 구분된 프레임 인덱스(예: "0,20"은 비디오의 키프레임 시간 지점을 정의함).
- 노이즈 배수: 쉼표로 구분된 0.0-1.0 값(예: "0.2,0.5"는 각 키프레임의 창의적 자유도에 해당하며, 값이 낮을수록 프레임에 더 충실하고, 값이 높을수록 더 다양함).
- 생성 매개변수
- LoRA Alpha: 0.1에서 5.0까지 조정 가능, 기본값은 1.4(스타일의 일관성을 제어합니다. 너무 높으면 뻣뻣해지고, 너무 낮으면 일관성을 잃습니다).
- 추론 단계: 1에서 50까지 조정 가능하며, 기본값은 10입니다(단계 수가 높을수록 세부 정보가 풍부해지지만 시간 소모는 선형적으로 증가합니다).
2.3 비디오-비디오
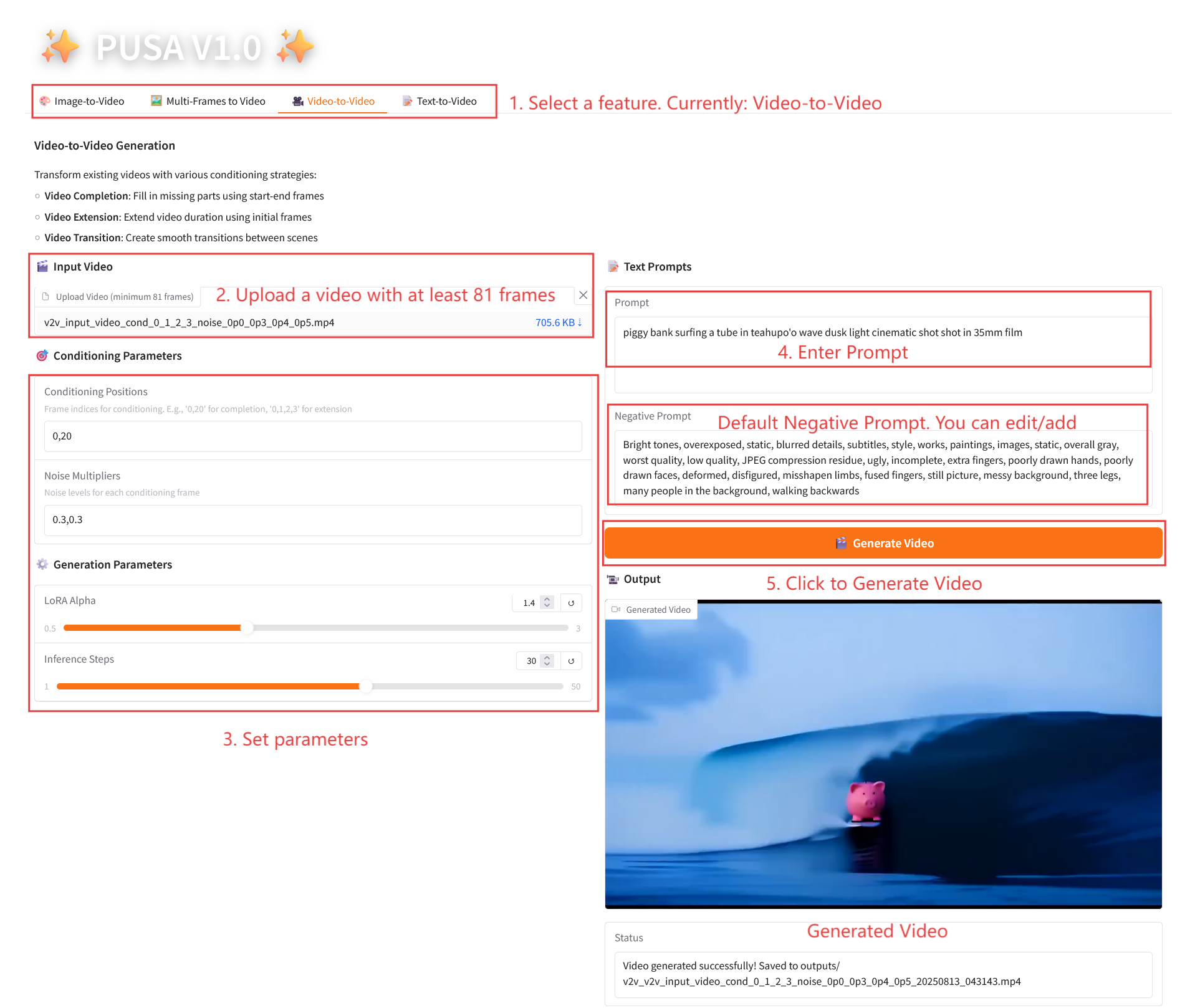
매개변수 설명
- 조건 매개변수
- 조건 지정 위치: 쉼표로 구분된 프레임 인덱스(예: "0,1,2,3"은 제약 조건 생성에 사용되는 원본 비디오의 키프레임 위치를 지정하며 필수임).
- 노이즈 배수: 쉼표로 구분된 0.0-1.0 값(예: "0.0,0.3"은 각 조건 프레임의 영향 정도에 해당하며, 값이 낮을수록 원래 프레임에 더 가깝고, 값이 높을수록 더 유연함).
- 생성 매개변수
- LoRA Alpha: 0.1에서 5.0까지 조정 가능, 기본값은 1.4(스타일의 일관성을 제어합니다. 너무 높으면 뻣뻣해지고, 너무 낮으면 일관성을 잃습니다).
- 추론 단계: 1에서 50까지 조정 가능하며, 기본값은 10입니다(단계 수가 높을수록 세부 정보가 풍부해지지만 시간 소모는 선형적으로 증가합니다).
2.4 텍스트-비디오
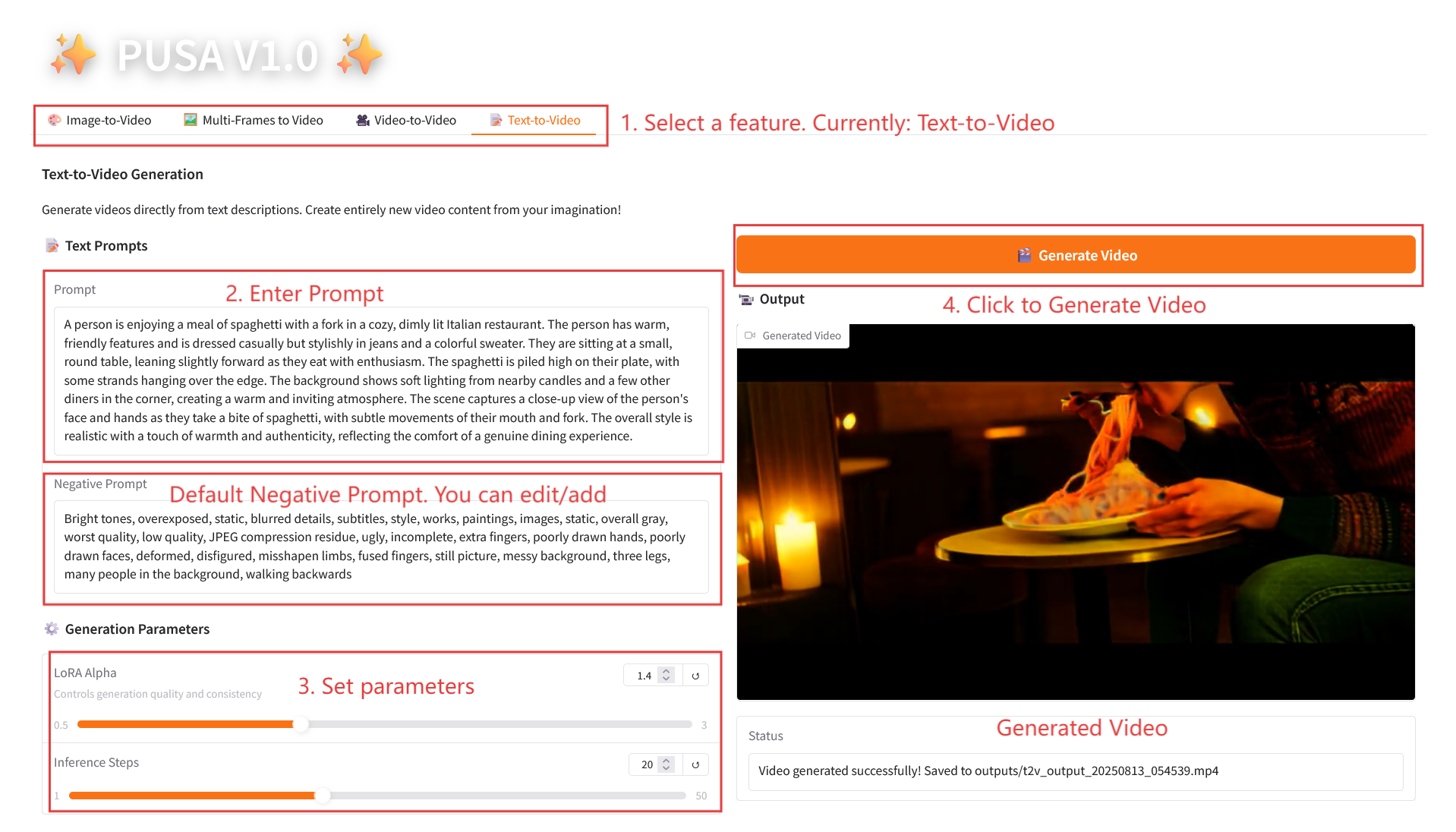
매개변수 설명
- 생성 매개변수
- LoRA Alpha: 0.1에서 5.0까지 조정 가능, 기본값은 1.4(스타일의 일관성을 제어합니다. 너무 높으면 뻣뻣해지고, 너무 낮으면 일관성을 잃습니다).
- 추론 단계: 1에서 50까지 조정 가능하며, 기본값은 10입니다(단계 수가 높을수록 세부 정보가 풍부해지지만 시간 소모는 선형적으로 증가합니다).
4. 토론
🖌️ 고품질 프로젝트를 발견하시면, 백그라운드에 메시지를 남겨 추천해주세요! 또한, 튜토리얼 교환 그룹도 만들었습니다. 친구들의 QR코드 스캔과 [SD 튜토리얼] 댓글을 통해 그룹에 가입하여 다양한 기술 이슈에 대해 논의하고 신청 결과를 공유해 주시기 바랍니다.↓

인용 정보
이 프로젝트에 대한 인용 정보는 다음과 같습니다.
@article{liu2025pusa,
title={PUSA V1. 0: Surpassing Wan-I2V with $500 Training Cost by Vectorized Timestep Adaptation},
author={Liu, Yaofang and Ren, Yumeng and Artola, Aitor and Hu, Yuxuan and Cun, Xiaodong and Zhao, Xiaotong and Zhao, Alan and Chan, Raymond H and Zhang, Suiyun and Liu, Rui and others},
journal={arXiv preprint arXiv:2507.16116},
year={2025}
}
@misc{Liu2025pusa,
title={Pusa: Thousands Timesteps Video Diffusion Model},
author={Yaofang Liu and Rui Liu},
year={2025},
url={https://github.com/Yaofang-Liu/Pusa-VidGen},
}
@article{liu2024redefining,
title={Redefining Temporal Modeling in Video Diffusion: The Vectorized Timestep Approach},
author={Liu, Yaofang and Ren, Yumeng and Cun, Xiaodong and Artola, Aitor and Liu, Yang and Zeng, Tieyong and Chan, Raymond H and Morel, Jean-michel},
journal={arXiv preprint arXiv:2410.03160},
year={2024}
}