Command Palette
Search for a command to run...
Ovis-U1-3B: 다중 모드 이해 및 생성 모델
1. 튜토리얼 소개

Ovis-U1-3B는 알리바바 그룹의 Ovis 팀이 2025년 6월 29일에 발표한 멀티모달 통합 모델입니다. 이 모델은 멀티모달 이해, 텍스트-이미지 생성, 이미지 편집이라는 세 가지 핵심 기능을 통합합니다. 고급 아키텍처와 협업 통합 학습 방식을 기반으로, 고충실도 이미지 합성과 효율적인 텍스트-비주얼 상호작용을 구현합니다. 멀티모달 이해, 생성, 편집 등 여러 학술적 벤치마크에서 Ovis-U1은 뛰어난 일반화 기능과 탁월한 성능을 입증하며 탁월한 성과를 달성했습니다. 관련 논문 결과는 다음과 같습니다.Ovis-U1 기술 보고서".
이 튜토리얼에서는 RTX 4090 그래픽 카드 하나를 사용합니다. 테스트를 위한 세 가지 예시를 제공합니다. 이미지 + 텍스트 → 이미지, 텍스트 → 이미지, 이미지 → 텍스트.
2. 프로젝트 예시

3. 작업 단계
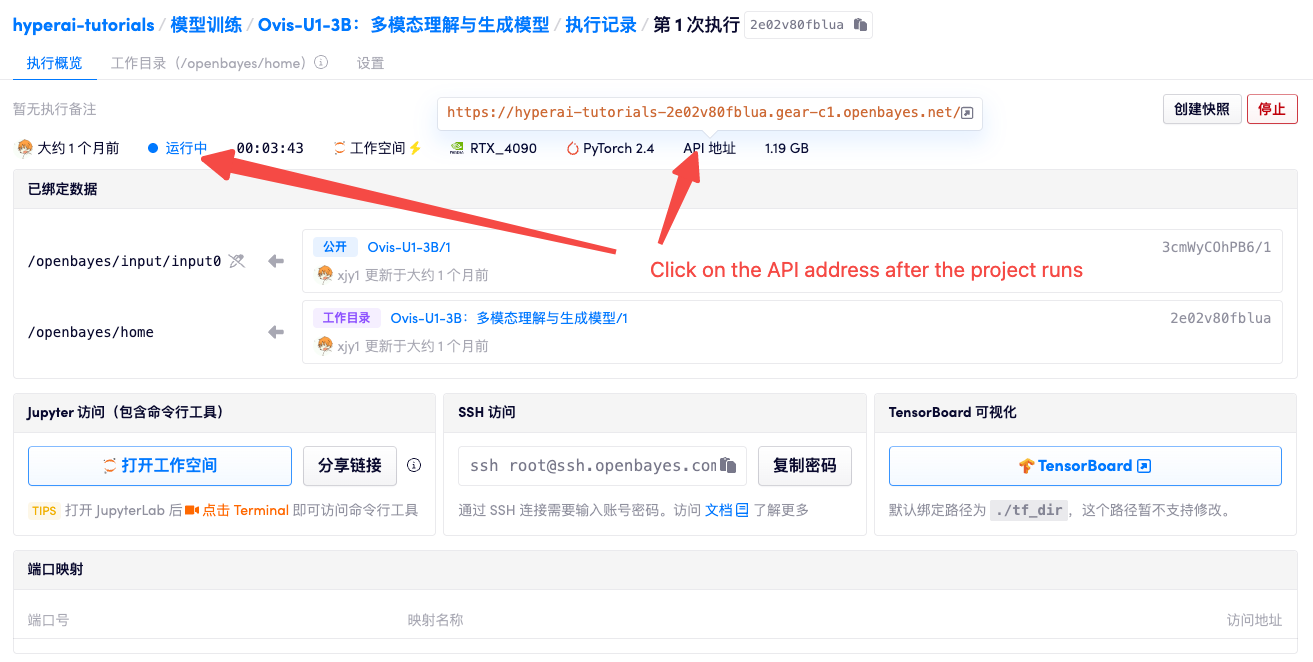
1. 컨테이너 시작 후 API 주소를 클릭하여 웹 인터페이스로 진입합니다.
2. 사용 단계
"잘못된 게이트웨이"가 표시되면 모델이 초기화 중임을 의미합니다. 모델이 크기 때문에 약 2~3분 정도 기다리신 후 페이지를 새로고침해 주시기 바랍니다.
2.1 이미지 + 텍스트 → 이미지
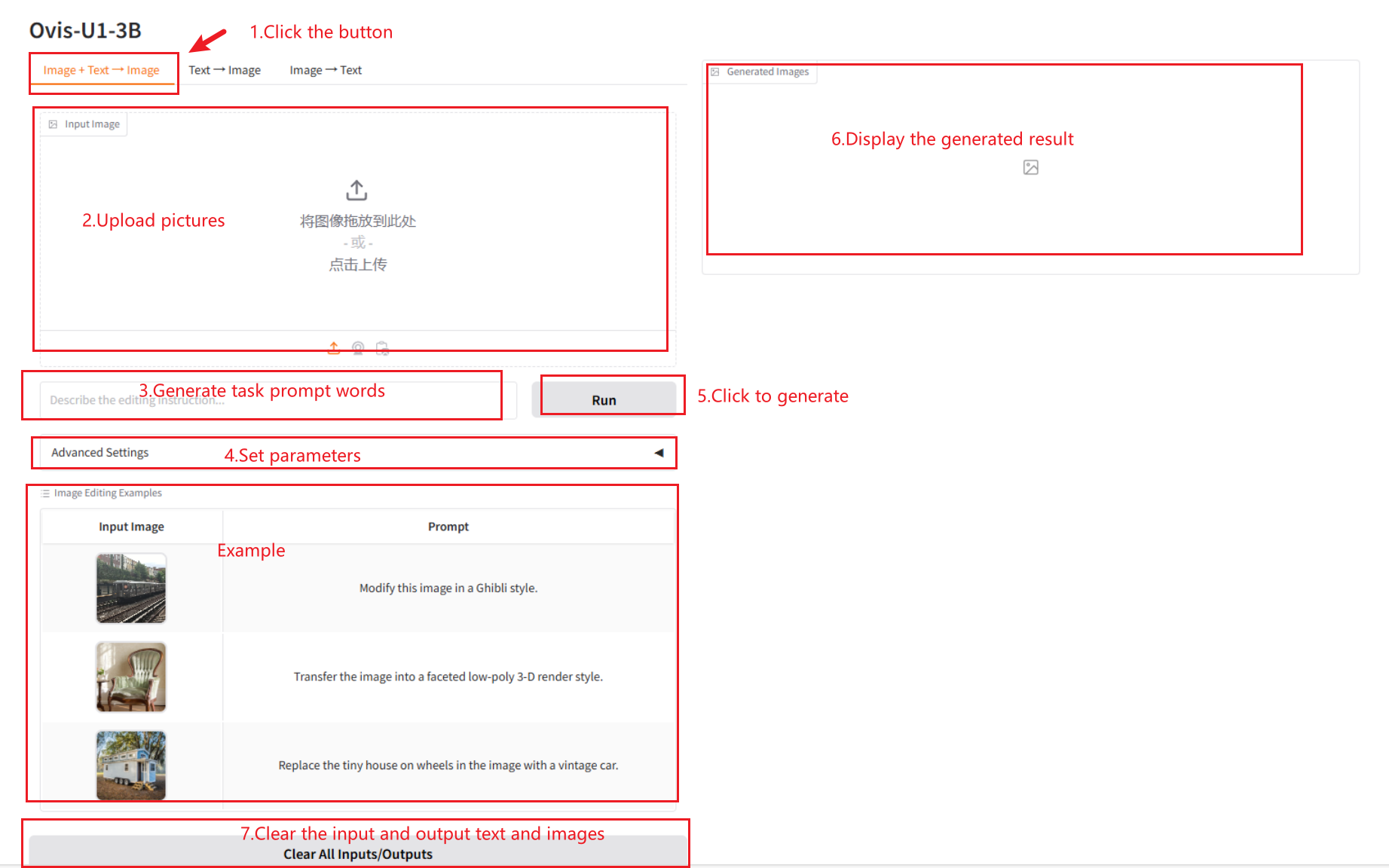
매개변수 설명
- 고급 설정
- 이미지 안내 척도: 생성된 이미지에 대한 텍스트 단서의 영향 강도를 제어합니다.
- 텍스트 안내 크기: 입력 이미지가 생성된 이미지에 미치는 영향을 제어합니다.
- 단계: 이미지 생성을 위한 반복 횟수.
- 시드: 이미지 생성 과정의 반복성을 위한 무작위 시드입니다.
- 시드 무작위화: 시드를 무작위로 생성합니다. 이미지가 생성될 때마다 새로운 시드가 무작위로 생성됩니다.
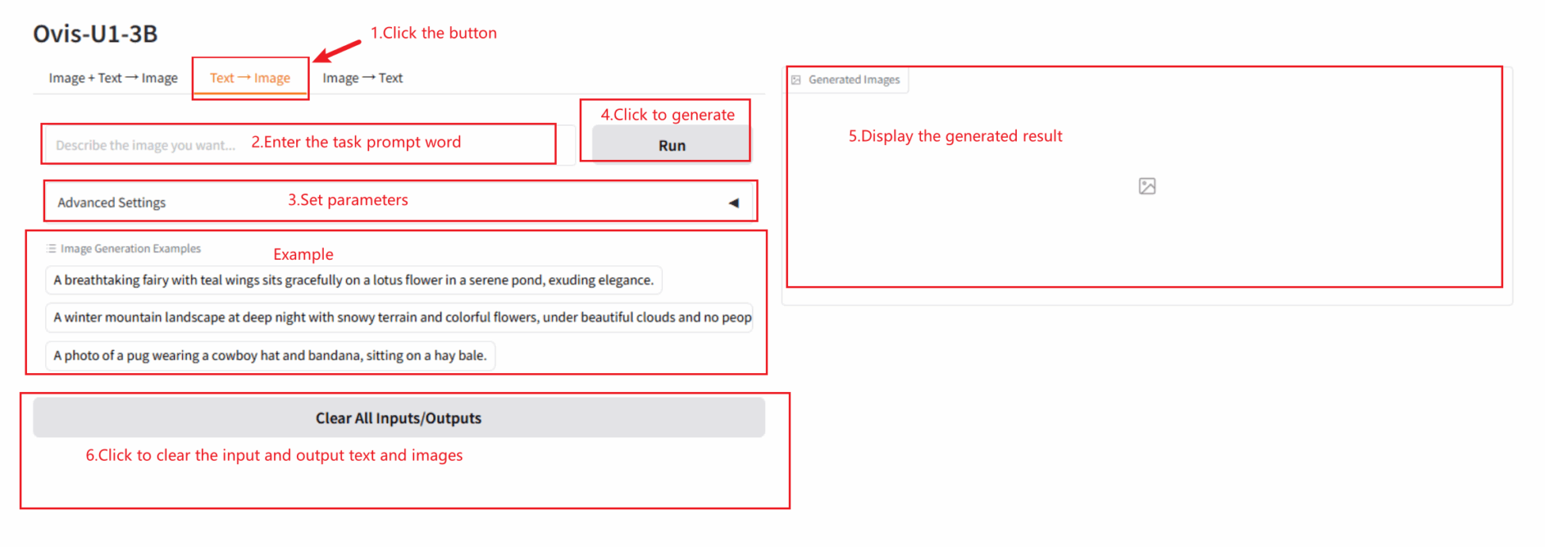
2.2 텍스트 → 이미지
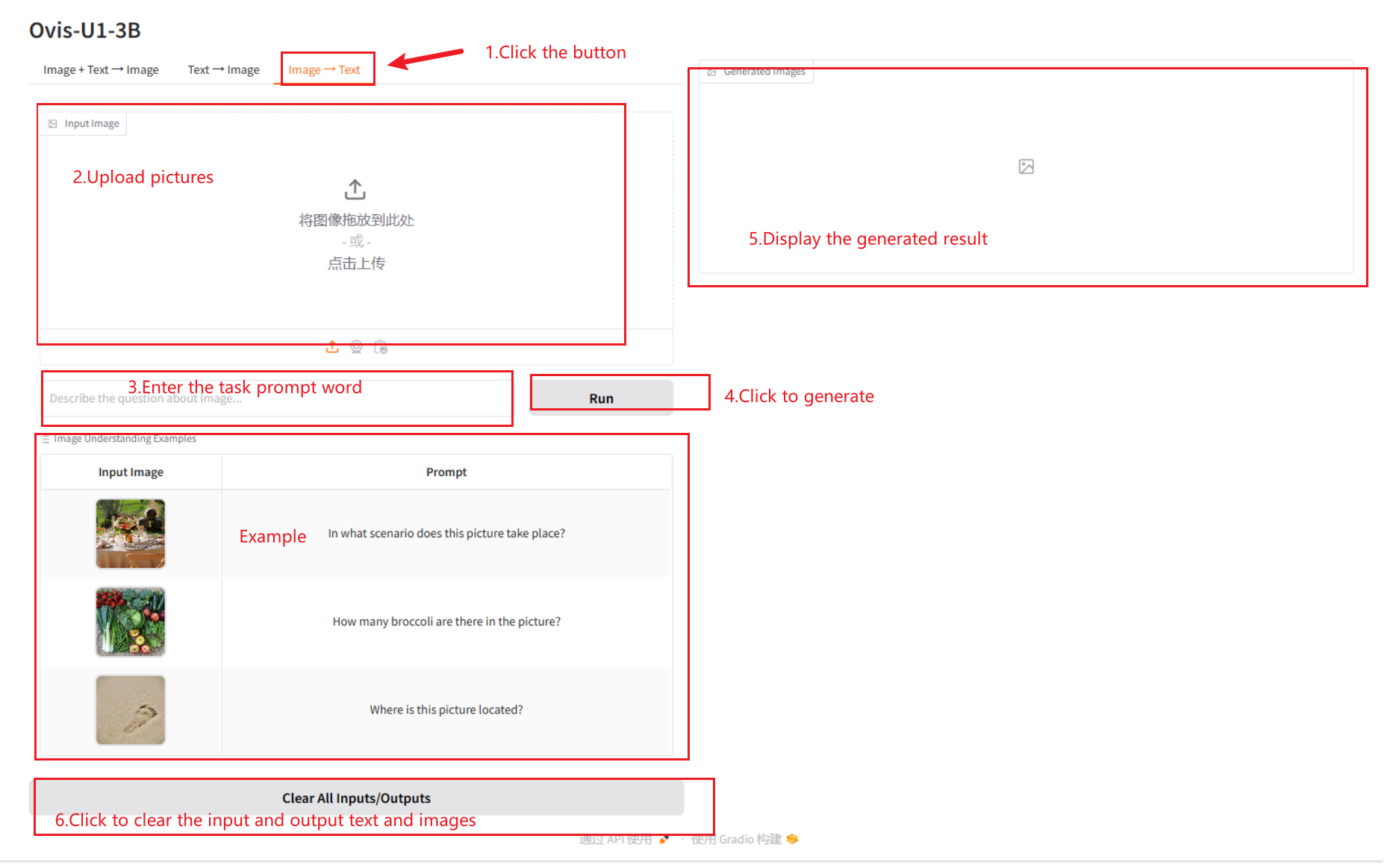
2.3 이미지 → 텍스트
4. 토론
🖌️ 고품질 프로젝트를 발견하시면, 백그라운드에 메시지를 남겨 추천해주세요! 또한, 튜토리얼 교환 그룹도 만들었습니다. 친구들의 QR코드 스캔과 [SD 튜토리얼] 댓글을 통해 그룹에 가입하여 다양한 기술 이슈에 대해 논의하고 신청 결과를 공유해 주시기 바랍니다.↓

인용 정보
이 프로젝트에 대한 인용 정보는 다음과 같습니다.
@article{wang2025ovisu1,
title={Ovis-U1 Technical Report},
author={Wang, Guo-Hua and Zhao, Shanshan and Zhang, Xinjie and Cao, Liangfu and Zhan, Pengxin and Duan, Lunhao and Lu, Shiyin and Fu, Minghao and Zhao, Jianshan and Li, Yang and Chen, Qing-Guo},
journal={arXiv preprint arXiv:2506.23044},
year={2025}
}