Command Palette
Search for a command to run...
MOSS: 텍스트-음성 대화 생성
1. 튜토리얼 소개

이 튜토리얼에서는 리소스로 단일 RTX 5090 카드를 사용합니다.
2. 프로젝트 예시
3. 작업 단계
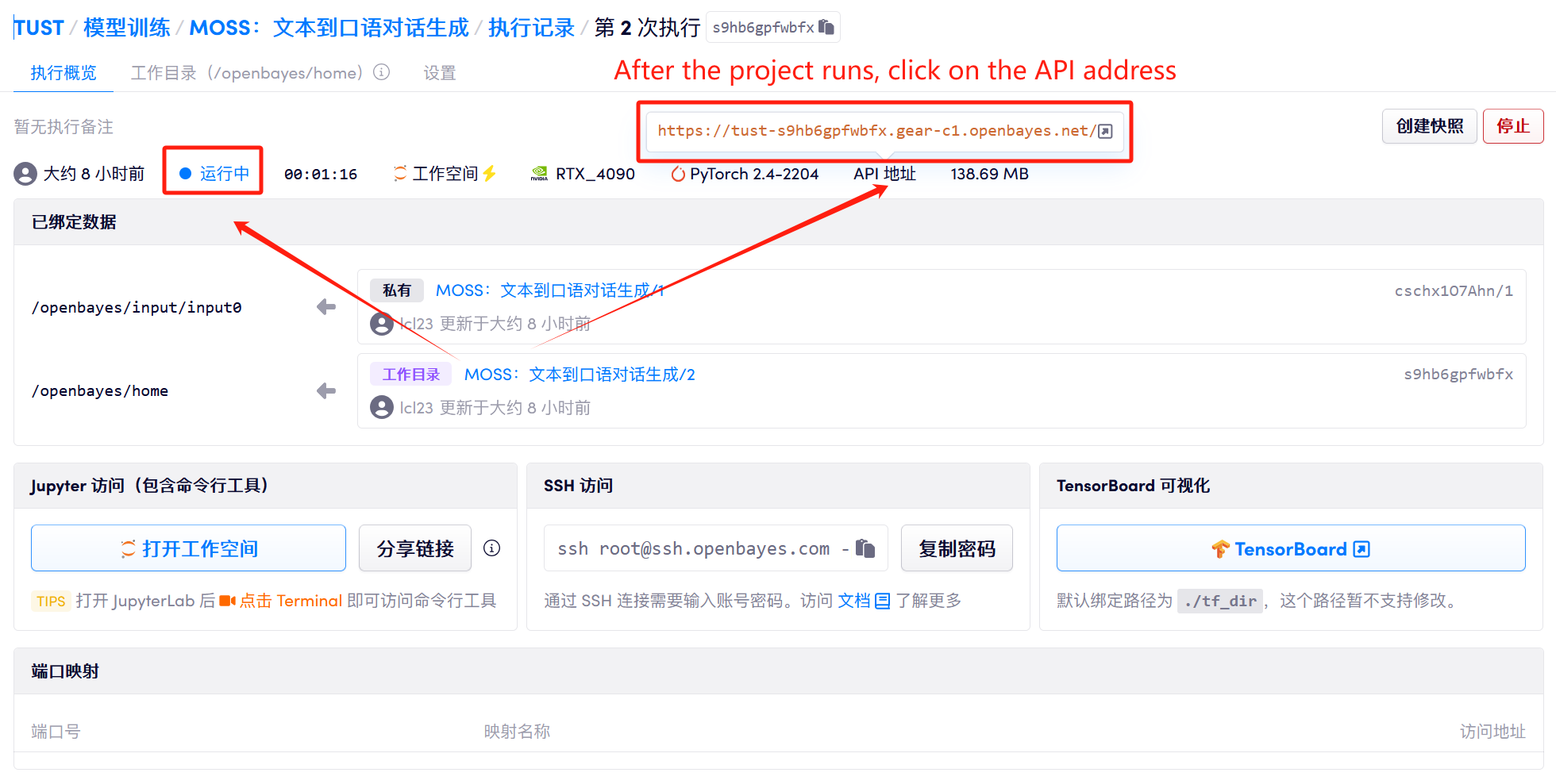
1. 컨테이너 시작 후 API 주소를 클릭하여 웹 인터페이스로 진입합니다.
2. 사용 단계
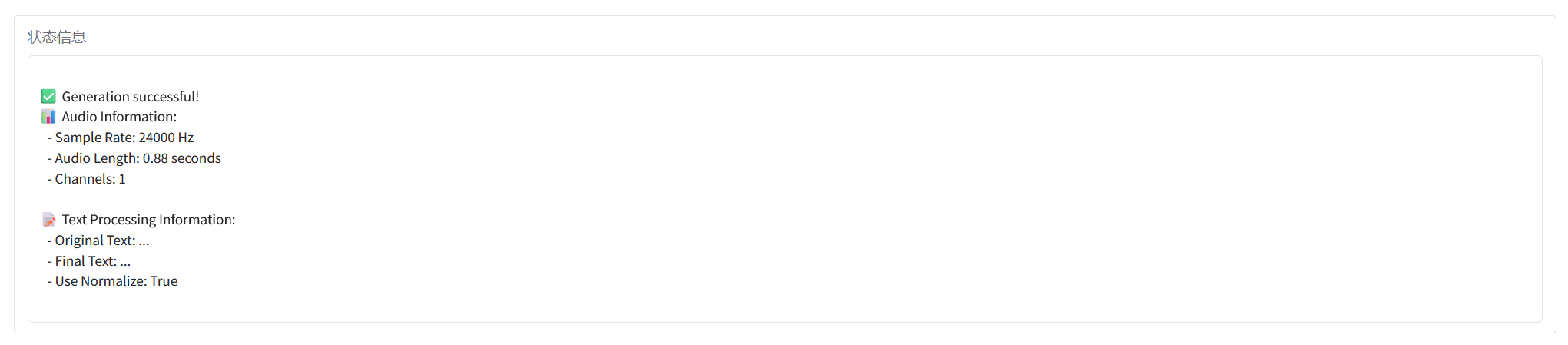
"잘못된 게이트웨이"가 표시되면 모델이 초기화 중임을 의미합니다. 모델이 크기 때문에 약 2~3분 정도 기다린 후 페이지를 새로고침해 주세요. Safari 브라우저를 사용하는 경우 오디오가 바로 재생되지 않을 수 있으므로 재생하기 전에 다운로드해야 합니다.
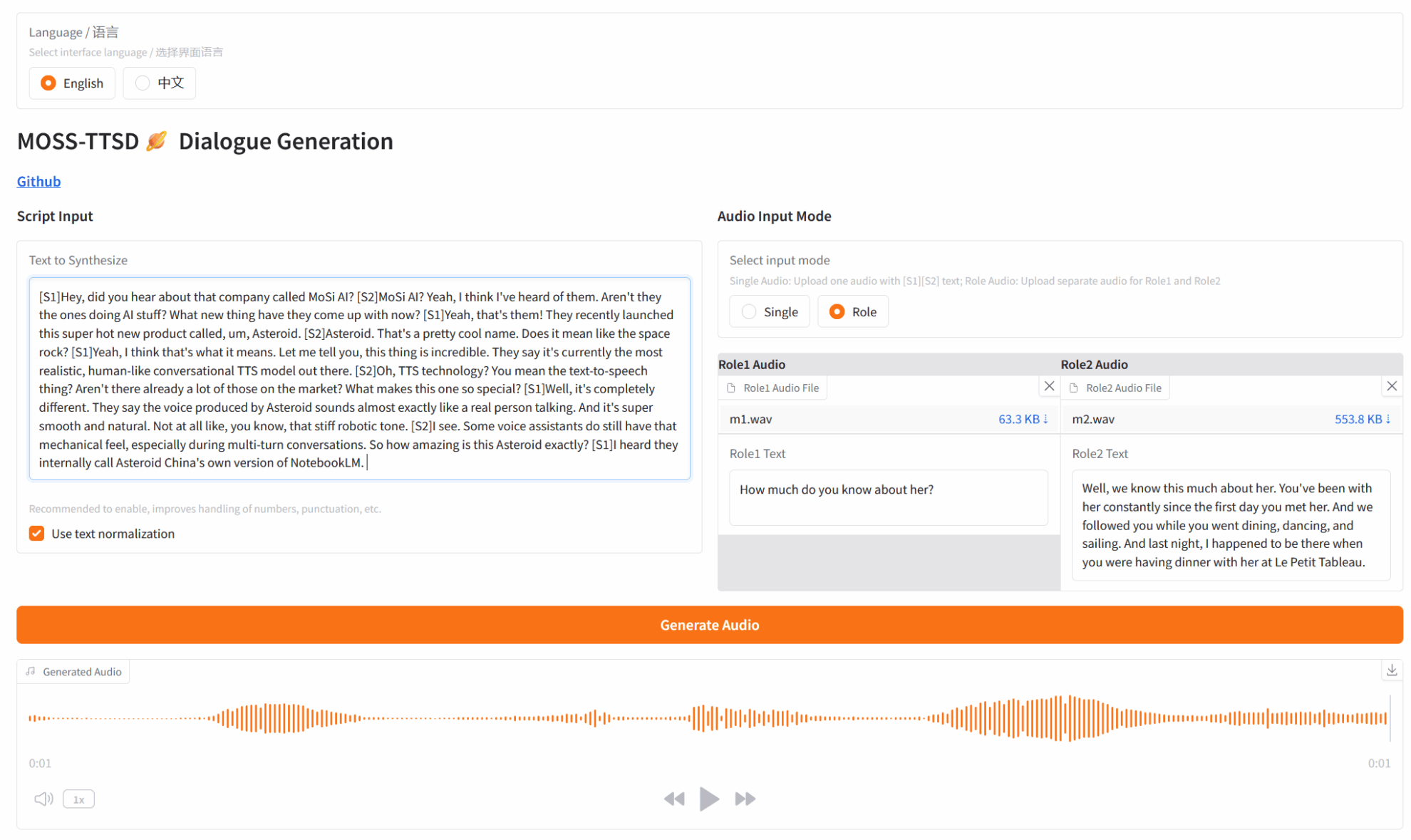
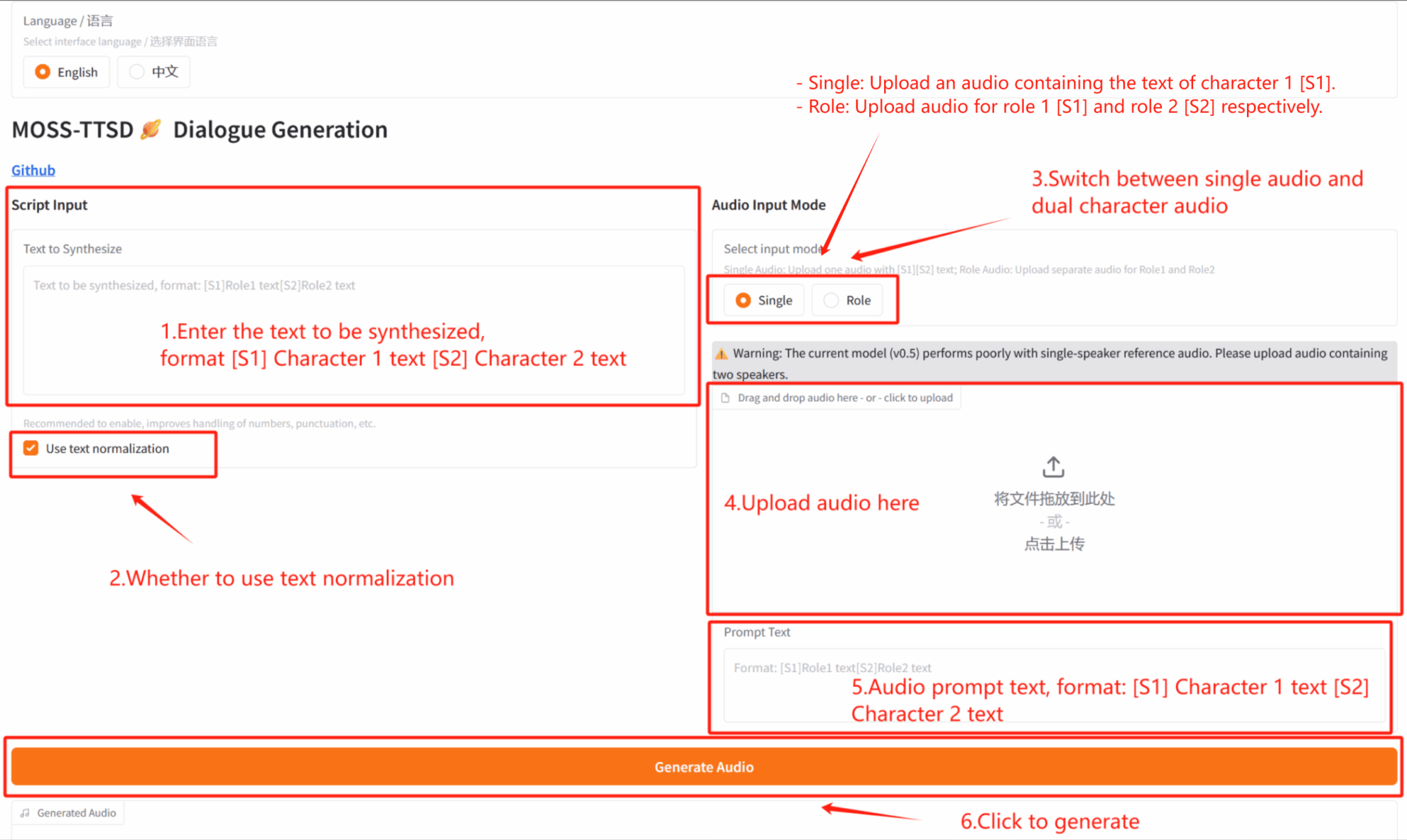
*이 튜토리얼에서는 "오디오 입력 모드"에서 싱글 플레이어 오디오 생성(싱글)과 2인용 대화 오디오 생성(역할) 중에서 선택할 수 있습니다.
인용 정보
이 프로젝트에 대한 인용 정보는 다음과 같습니다.
@article{moss2025ttsd,
title={Text to Spoken Dialogue Generation},
author={OpenMOSS Team},
year={2025}
}