Command Palette
Search for a command to run...
Voxtral-Small-24B-2507 음성 이해 모델 데모
1. 튜토리얼 소개
Voxtral은 Mistral AI가 2025년 7월에 출시한 고급 오디오 모델입니다. 탁월한 음성 전사 및 심층 이해 기능을 기반으로 음성을 자연스러운 인간-컴퓨터 상호작용 방식으로 발전시킵니다. Voxtral은 각각 프로덕션 규모 및 로컬 배포에 적합한 24B 및 3B 버전으로 제공됩니다. Voxtral은 다국어, 장문 텍스트 컨텍스트, 내장 질의응답 및 요약 기능을 지원하며 백엔드 함수 호출을 직접 트리거할 수 있습니다. Voxtral의 성능은 여러 벤치마크에서 기존 오픈 소스 모델 및 독점 API를 능가하는 동시에, 비용이 저렴하고 다양한 시나리오에서 널리 사용되어 음성 상호작용의 대중화에 기여합니다.
주요 특징:
- 긴 텍스트 문맥 처리: 최대 30분 분량의 오디오 필사본과 40분 분량의 오디오 이해를 지원하며, 복잡한 장문 콘텐츠를 처리할 수 있습니다.
- 내장된 Q&A 및 요약 기능: 오디오 콘텐츠에 대한 질문을 직접 하거나 추가 ASR 및 언어 모델 없이도 구조화된 요약을 생성할 수 있습니다.
- 다국어 지원: 자동 언어 감지, 여러 공통 언어(예: 영어, 스페인어, 프랑스어, 포르투갈어, 힌디어, 독일어 등) 지원으로 글로벌 사용자의 요구를 충족합니다.
- 음성 트리거 기능 호출: 중간 구문 분석 단계 없이 사용자 음성 의도에 따라 백엔드 기능, 워크플로 또는 API 호출을 직접 트리거합니다.
- 텍스트 이해 기능: Mistral Small 3.1의 텍스트 이해 기능이 유지되어 텍스트 입력과 처리를 지원합니다.
- 최적화된 전사 성능: 대규모 애플리케이션에 적합하고 비용 효율적인 고도로 최적화된 전사 엔드포인트를 제공합니다.
이 튜토리얼의 컴퓨팅 리소스는 듀얼 카드 RTX A6000을 사용하며, 이 튜토리얼에 사용된 모델은 Voxtral-Small-24B-2507입니다. 테스트를 위해 오디오 전사(Audio Transcription)와 오디오 이해(Audio Understanding) 두 가지 기능이 제공됩니다.
2. 효과 표시
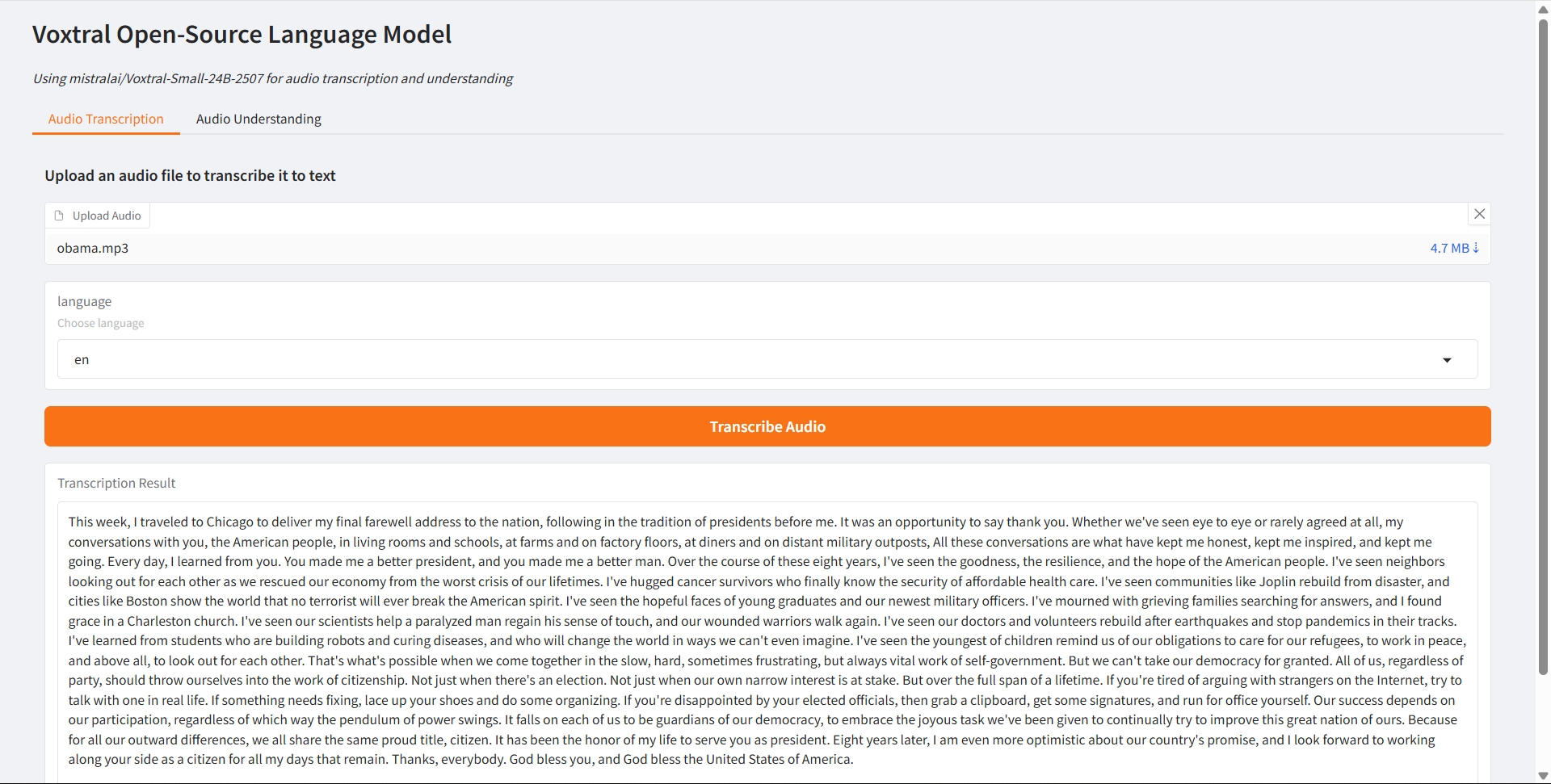
오디오 전사
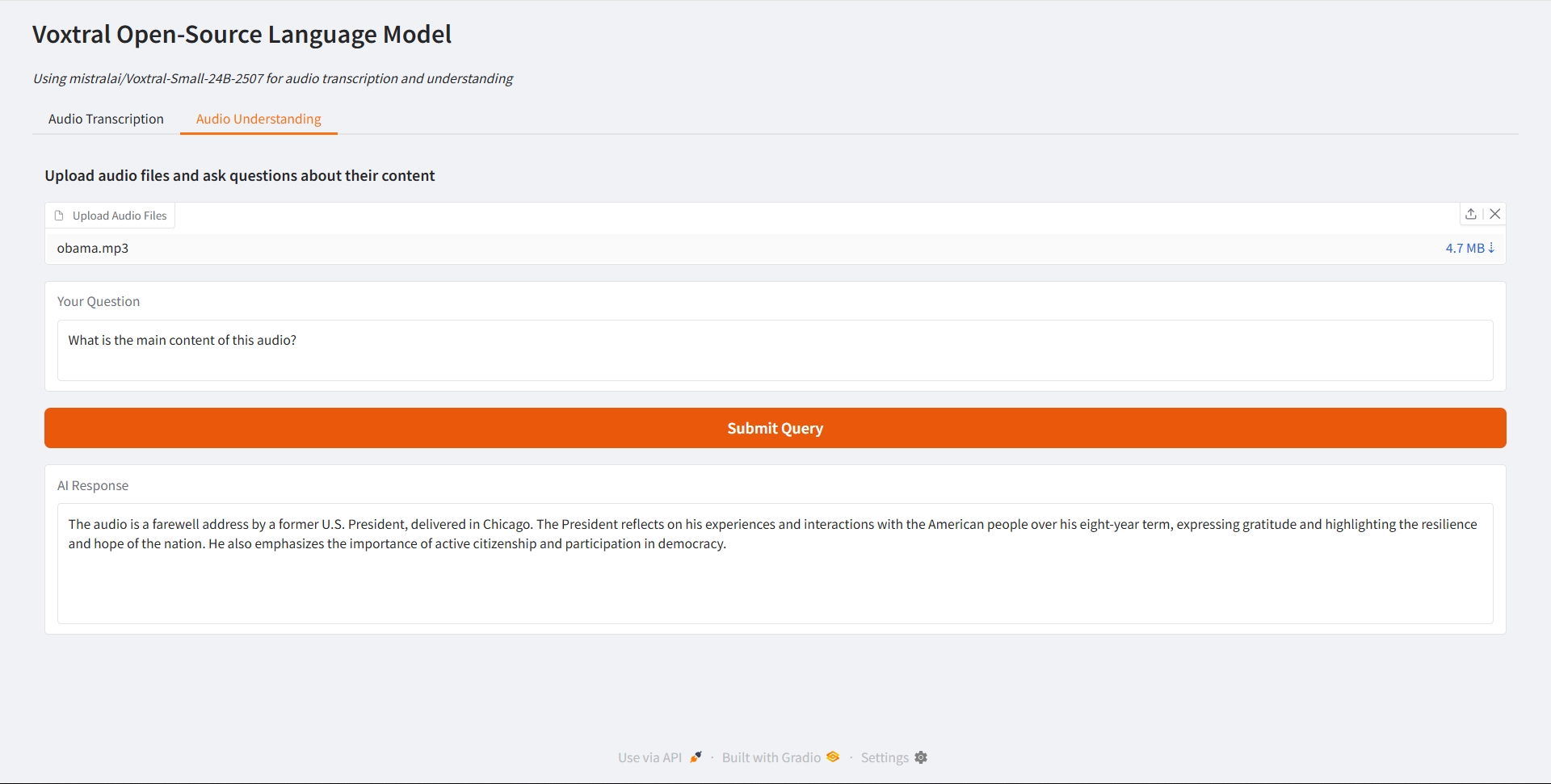
오디오 이해
3. 작업 단계
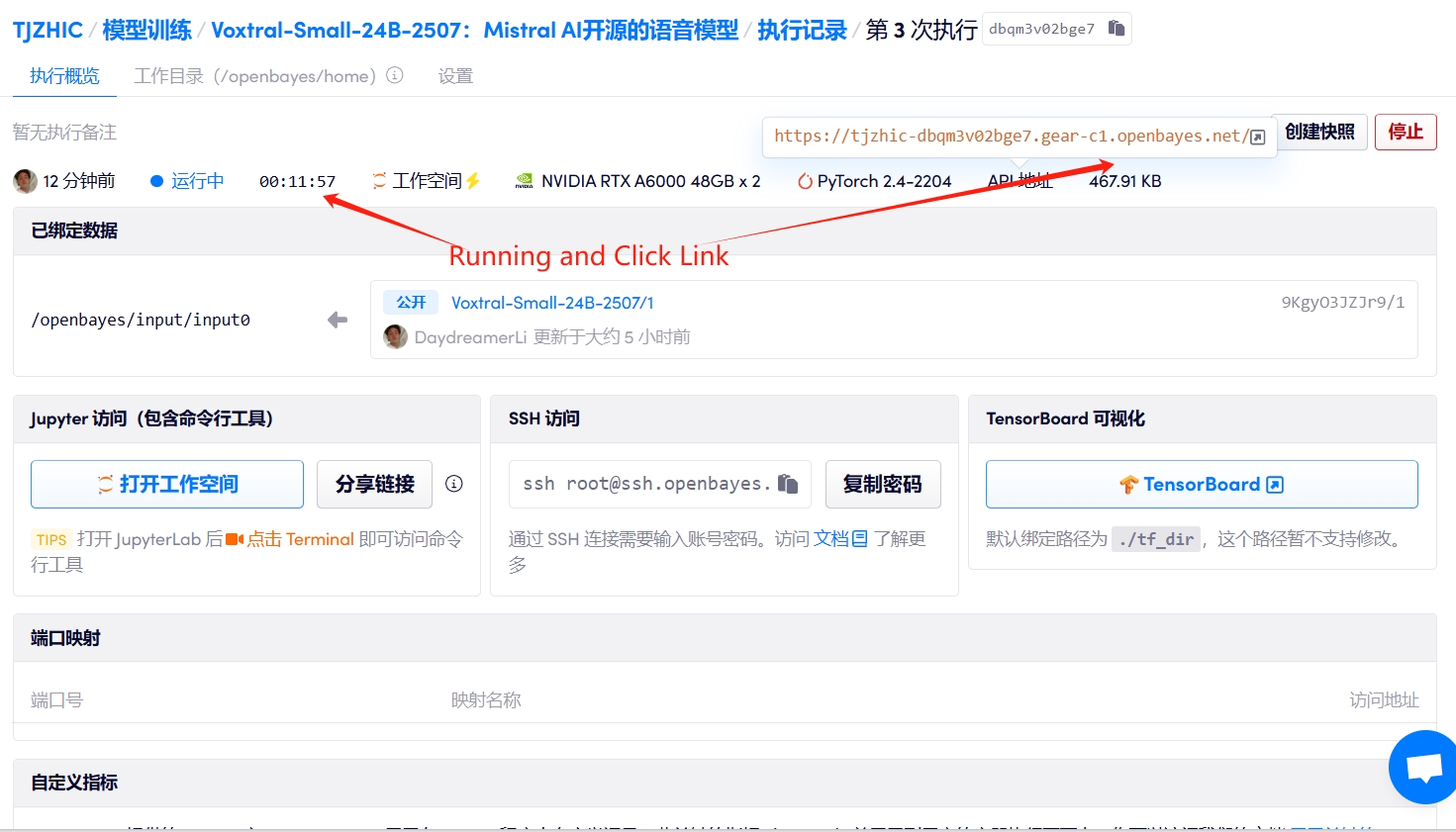
1. 컨테이너를 시작하세요
2. 사용 단계
"잘못된 게이트웨이"가 표시되면 모델이 초기화 중임을 의미합니다. 모델 용량이 크므로 5~10분 정도 기다린 후 페이지를 새로고침해 주세요.
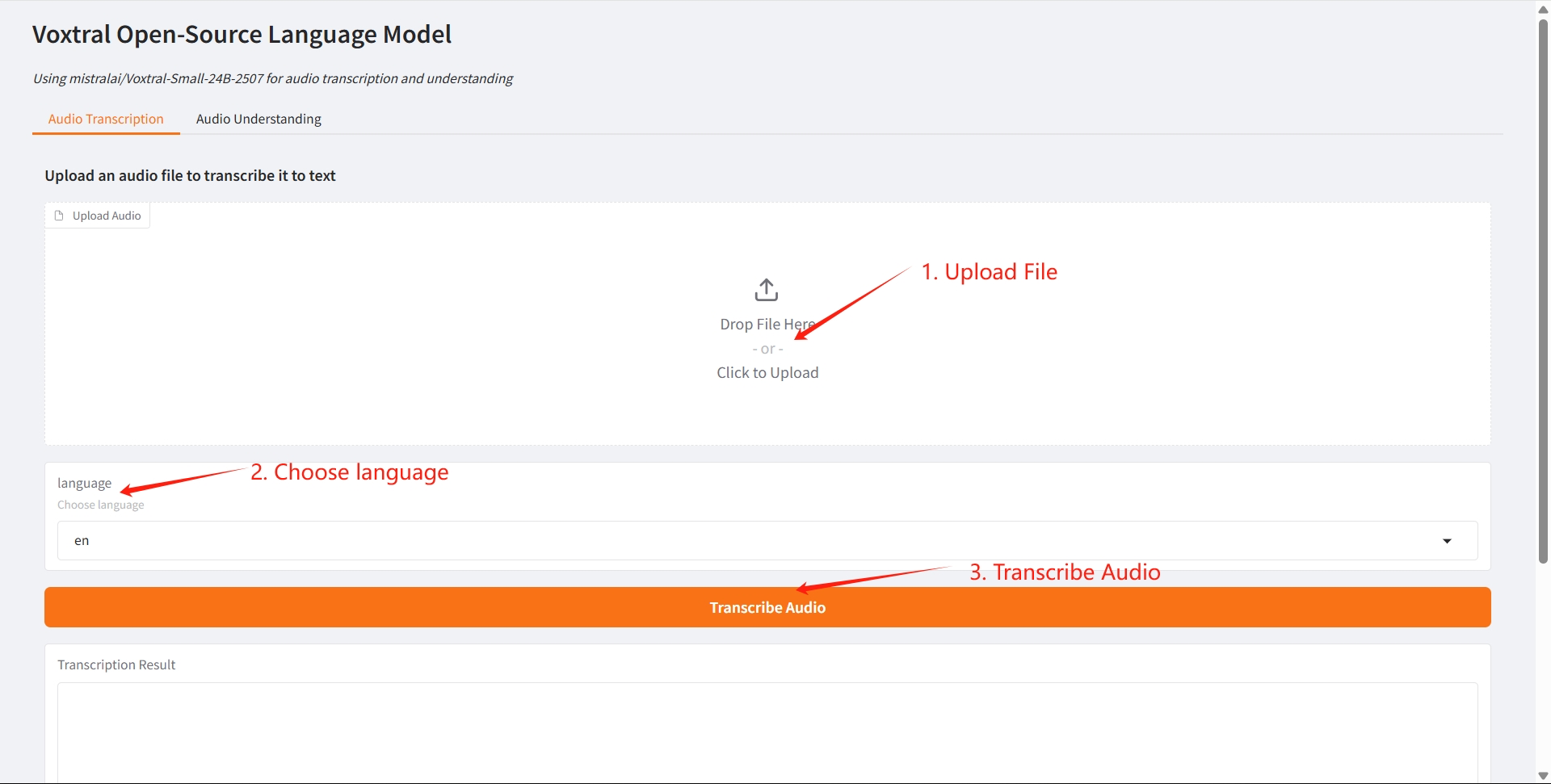
1. 오디오 전사
2. 오디오 이해
4. 토론
🖌️ 고품질 프로젝트를 발견하시면, 백그라운드에 메시지를 남겨 추천해주세요! 또한, 튜토리얼 교환 그룹도 만들었습니다. 친구들의 QR코드 스캔과 [SD 튜토리얼] 댓글을 통해 그룹에 가입하여 다양한 기술 이슈에 대해 논의하고 신청 결과를 공유해 주시기 바랍니다.↓
