Command Palette
Search for a command to run...
PlayDiffusion: 오픈 소스 오디오 로컬 편집 모델
1. 튜토리얼 소개

주요 특징:
- 부분 오디오 편집: 전체 오디오 세그먼트를 다시 생성하지 않고 오디오의 일부를 교체, 수정 또는 삭제하여 음성을 자연스럽고 매끄럽게 유지합니다.
- 효율적인 TTS: 전체 오디오를 마스킹할 때 효율적인 TTS 모델로서 추론 속도가 기존 TTS보다 50배 빠르고, 음성의 자연스러움과 일관성이 더 뛰어납니다.
- 말의 연속성 유지: 편집할 때 맥락을 보존하여 말의 연속성과 화자의 음색의 일관성을 확보합니다.
- 동적 음성 수정: 실시간 상호작용과 같은 시나리오에 적합하도록 새 텍스트에 따라 음성 발음, 톤, 리듬을 자동으로 조정합니다.
기술 원리:
- 오디오 인코딩: 입력 오디오 시퀀스를 개별 토큰 시퀀스로 인코딩합니다. 각 토큰은 오디오 단위를 나타냅니다. 실제 음성 및 텍스트 음성 변환 모델로 생성된 오디오에 적용 가능합니다.
- 마스크 처리: 오디오의 일부를 수정해야 하는 경우 해당 부분을 마스크로 표시하면 이후 처리가 용이해집니다.
- 확산 모델 노이즈 제거: 텍스트를 업데이트하는 확산 모델을 기반으로 마스크된 영역의 노이즈를 제거합니다. 확산 모델은 단계별 노이즈 제거를 기반으로 고품질 오디오 토큰 시퀀스를 생성합니다. 모든 토큰은 비자기회귀 방식을 사용하여 동시에 생성되며, 고정된 노이즈 제거 단계에 따라 미세 조정됩니다.
- 오디오 파형으로 디코딩: 생성된 토큰 시퀀스는 BigVGAN 디코더 모델을 기반으로 음성 파형으로 다시 변환되어 최종 출력 음성이 자연스럽고 일관성이 있는지 확인합니다.
이 튜토리얼은 단일 RTX A6000 컴퓨팅 리소스를 사용하며, Inpaint, TTS(텍스트 음성 변환), 음성 변환의 세 가지 테스트 예시를 제공합니다. 이 튜토리얼은 영어만 지원합니다.
2. 효과 표시
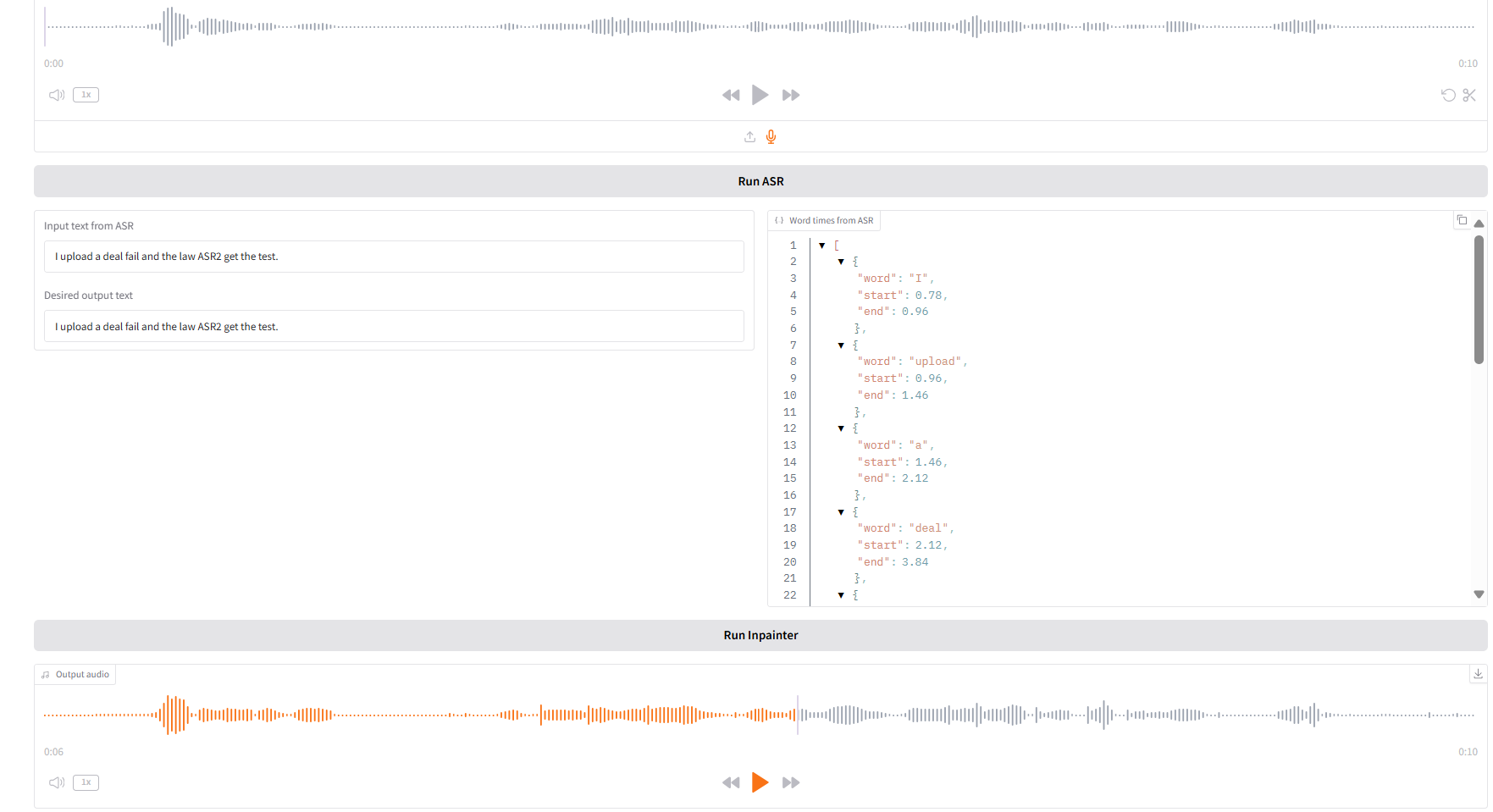
1. 인페인트
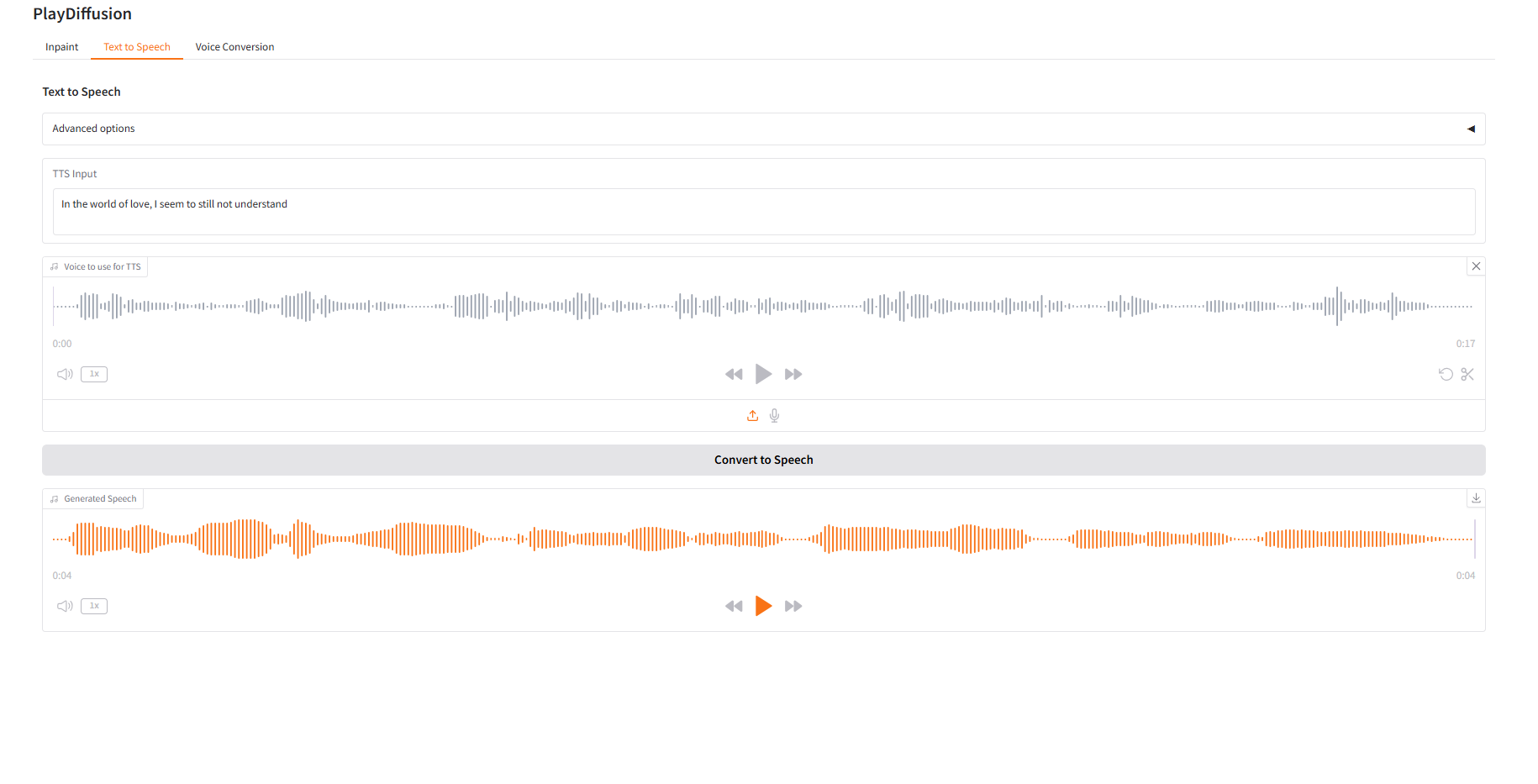
2. 텍스트 음성 변환
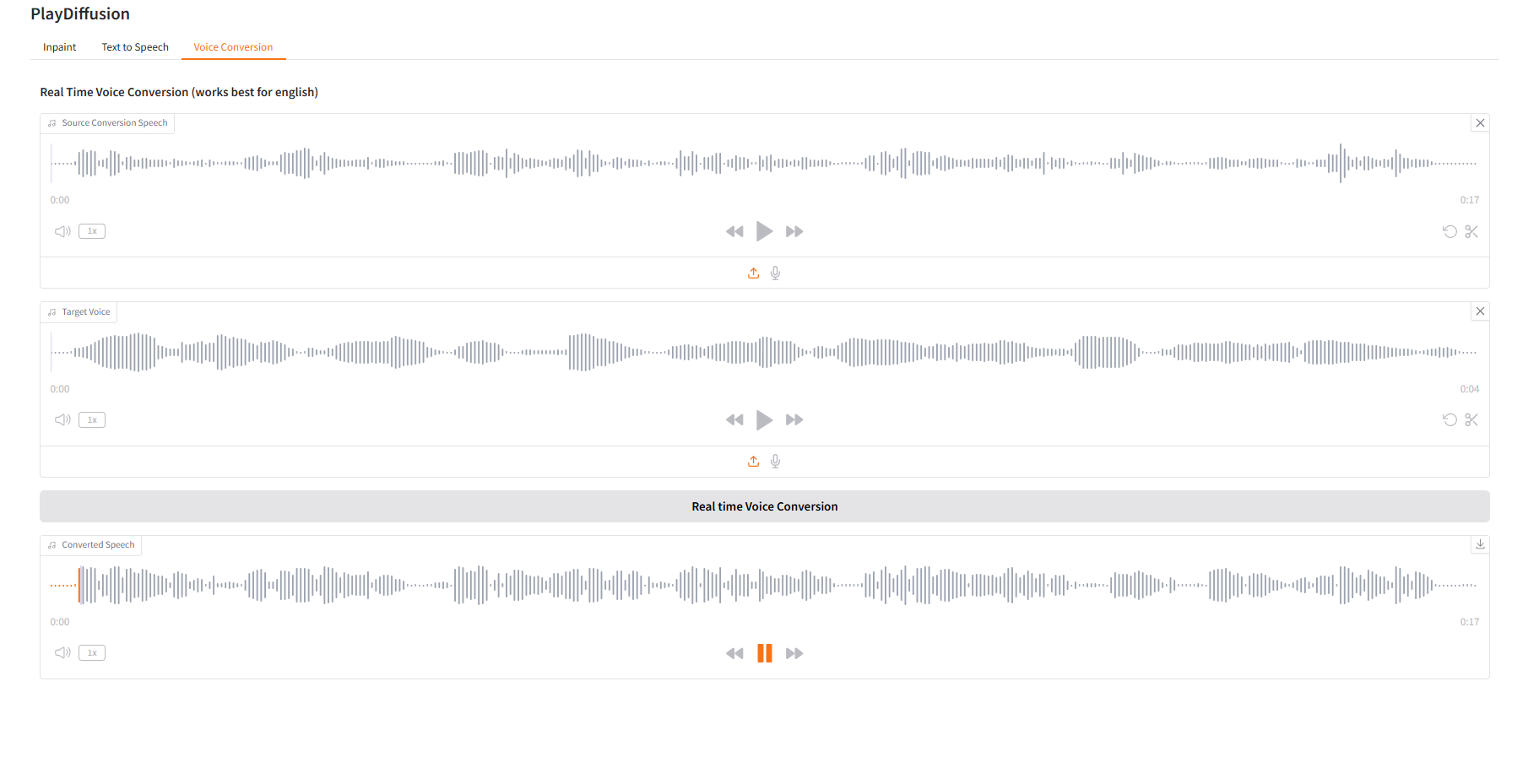
3. 음성 변환
3. 작업 단계
1. 컨테이너를 시작하세요
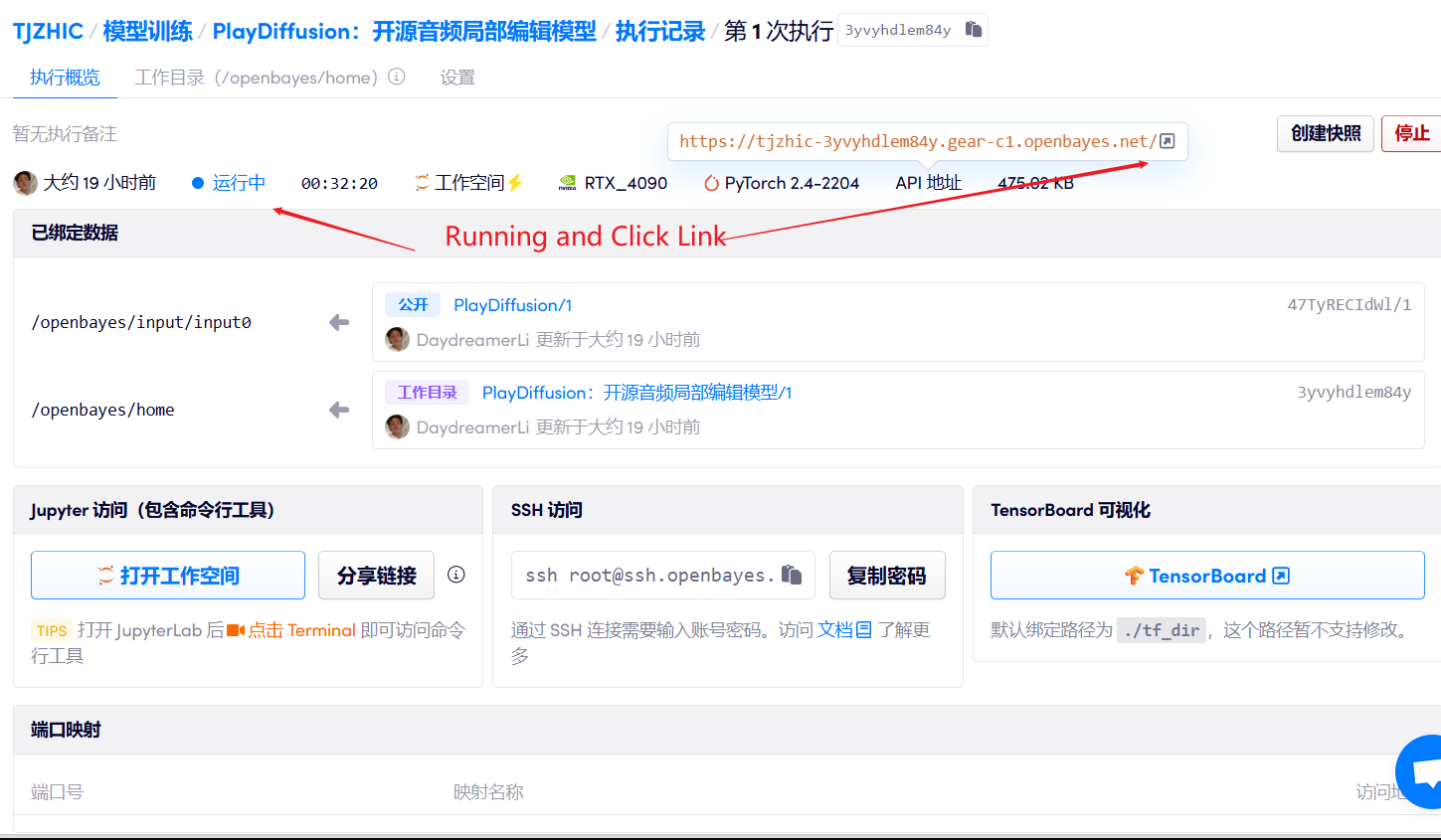
2. 사용 단계
"잘못된 게이트웨이"가 표시되면 모델이 초기화 중임을 의미합니다. 모델이 크기 때문에 약 2~3분 정도 기다리신 후 페이지를 새로고침해 주시기 바랍니다.
Safari 브라우저를 사용하는 경우 오디오가 직접 재생되지 않을 수 있으며, 재생하기 전에 다운로드해야 합니다.
1. 인페인트
이 모듈은 전체 오디오를 재생성하지 않고도 오디오를 부분적으로 교체, 수정 또는 삭제할 수 있어 음성을 자연스럽고 매끄럽게 유지할 수 있습니다.
- 원본 오디오를 업로드하고 "SAR 실행"을 클릭하여 실행한 다음 "원하는 출력 텍스트"에서 출력하려는 오디오 콘텐츠를 수정하고 편집합니다.
- 그런 다음 "Inpainter 실행"을 클릭하여 편집된 오디오를 생성합니다.
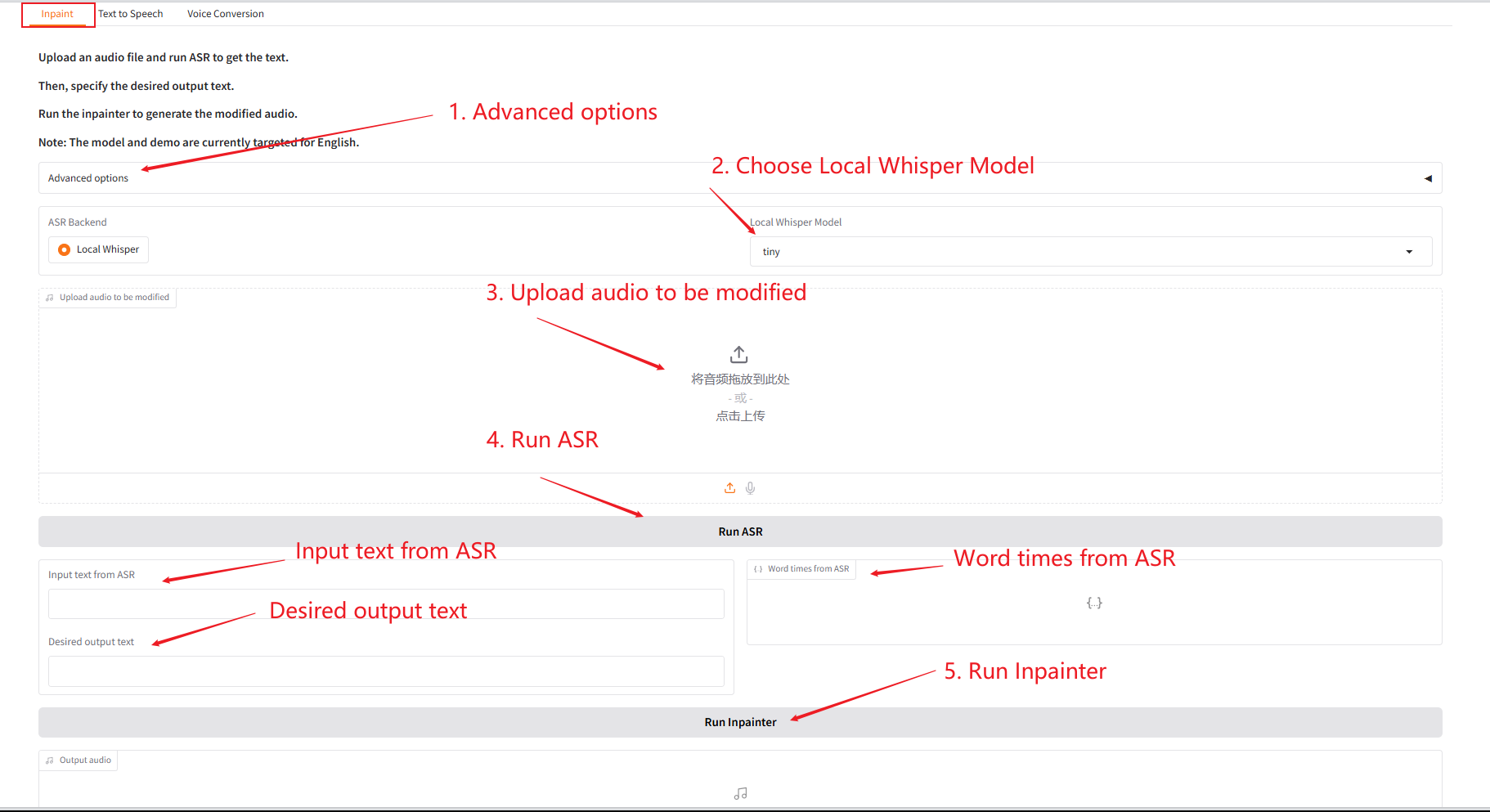
매개변수 설명:
- 샘플링 단계 수: 확산 모델 생성 과정에서 반복되는 횟수입니다. 단계가 많을수록 생성 품질은 높아지지만 시간이 더 오래 걸립니다.
- 코드북: 벡터 양자화 계층의 이산 기호 사전으로, 연속적인 특징을 이산 표현으로 매핑하는 데 사용됩니다.
- 초기 온도: 샘플링의 무작위성을 제어하는 매개변수입니다. 값이 높을수록 다양성이 커지고, 값이 낮을수록 결과가 더 확실해집니다.
- 초기 다양성: 너무 유사한 결과가 생성되는 것을 방지하기 위해 생성된 샘플의 변화 정도를 제어하는 매개변수입니다.
- 지침: 생성된 결과에 대한 조건부 정보(예: 텍스트)의 영향 정도를 조정합니다.
- 안내 재조정 계수: 조건부 안내와 무조건 생성의 균형을 맞추는 데 사용되는 가중치 비율입니다.
- 상위 k 로짓에서 샘플링: 생성 품질을 개선하기 위해 확률이 가장 높은 K개 후보에서만 선택합니다.
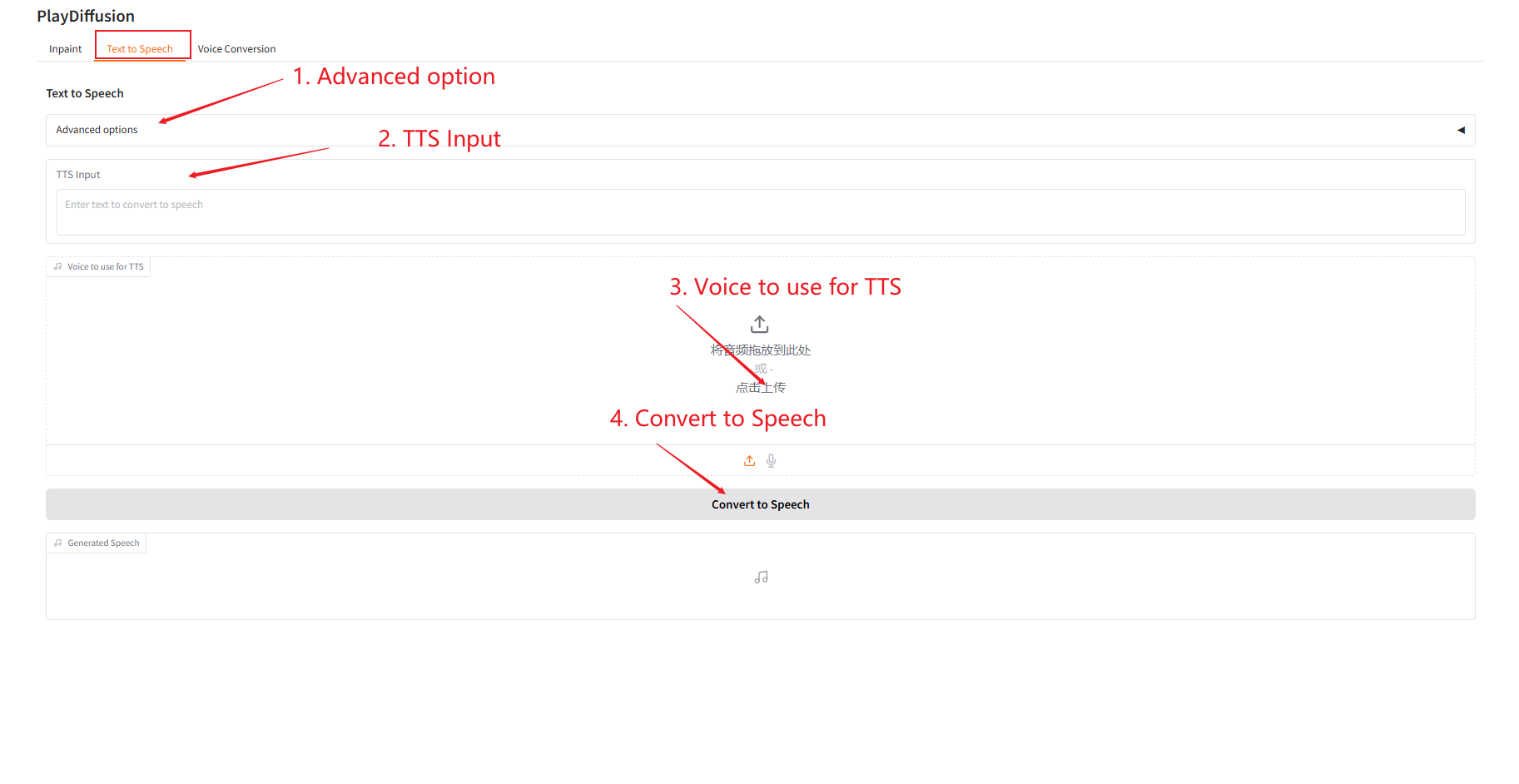
2. 텍스트 음성 변환
효율적인 TTS 모델로서, 기존 TTS보다 추론 속도가 50배 빠르고, 음성의 자연스러움과 일관성이 더 뛰어납니다.
- "TTS 입력"에 오디오를 생성하려는 텍스트 콘텐츠를 입력한 다음 대상 오디오를 업로드합니다.
- 그런 다음 "음성으로 변환"을 클릭하여 오디오를 생성합니다.
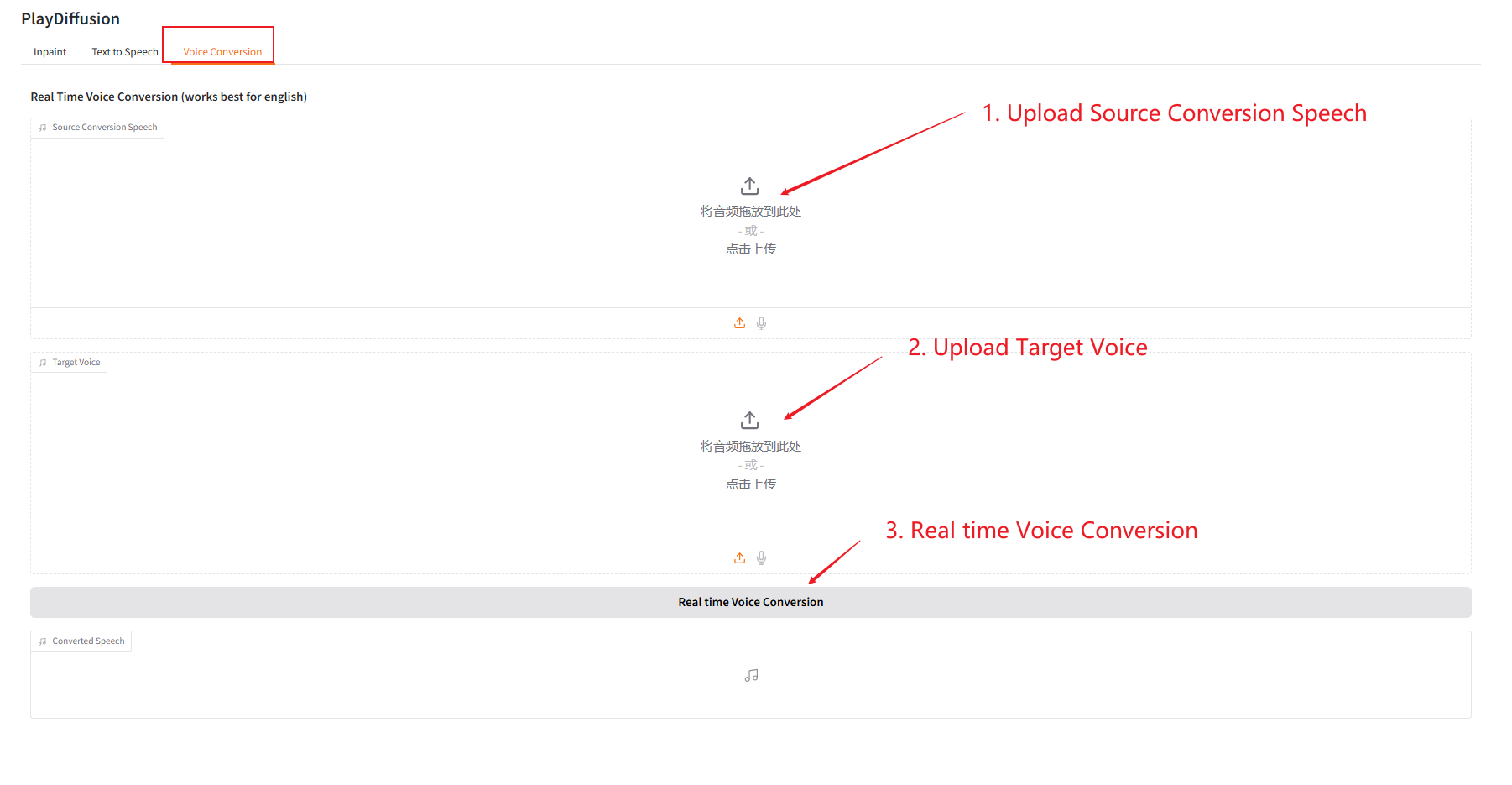
3. 음성 변환
음성 콘텐츠를 동적으로 조정하고, 원본 오디오 콘텐츠를 대상 음색에 직접 복제할 수 있습니다.
- 원본 오디오를 업로드한 다음, 대상 오디오를 업로드합니다.
- 그런 다음 "실시간 음성 변환"을 클릭하여 대상 톤의 원본 오디오 콘텐츠를 직접 생성합니다.
4. 토론
🖌️ 고품질 프로젝트를 발견하시면, 백그라운드에 메시지를 남겨 추천해주세요! 또한, 튜토리얼 교환 그룹도 만들었습니다. 친구들의 QR코드 스캔과 [SD 튜토리얼] 댓글을 통해 그룹에 가입하여 다양한 기술 이슈에 대해 논의하고 신청 결과를 공유해 주시기 바랍니다.↓
