Command Palette
Search for a command to run...
VideoLLaMA3-7B의 원클릭 배포
1. 튜토리얼 소개


이 튜토리얼은 단일 RTX 4090 컴퓨팅 리소스를 사용하고, VideoLLaMA3-7B-Image 모델을 배포하며, 비디오 이해 및 이미지 이해에 대한 두 가지 예시를 제공합니다. 또한, "단일 이미지 이해", "다중 이미지 이해", "시각적 참조 표현 및 위치 지정", "비디오 이해"에 대한 네 가지 노트북 스크립트 튜토리얼도 제공합니다.
VideoLLaMA3는 알리바바 DAMO 아카데미 자연어 처리 팀(DAMO-NLP-SG)이 2025년 2월 공개한 오픈소스 멀티모달 기본 모델로, 이미지 및 비디오 이해 작업에 중점을 두고 있습니다. 비전 중심 아키텍처 설계와 고품질 데이터 엔지니어링을 통해 비디오 이해의 정확도와 효율성이 크게 향상되었습니다. 경량 버전(2B)은 엔드-사이드 배포의 요구 사항을 고려했으며, 7B 모델은 연구 수준 애플리케이션에 최고의 성능을 제공합니다. 7B 모델은 일반 비디오 이해, 시간 추론, 장편 비디오 분석의 세 가지 주요 작업에서 SOTA(Short-Time Attitude Test)를 달성했습니다. 관련 논문 결과는 다음과 같습니다.VideoLLaMA 3: 이미지 및 비디오 이해를 위한 최전선 다중 모달 기반 모델".
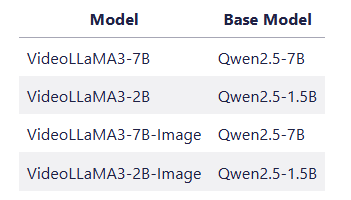
👉 이 프로젝트는 4가지 모델을 제공합니다:
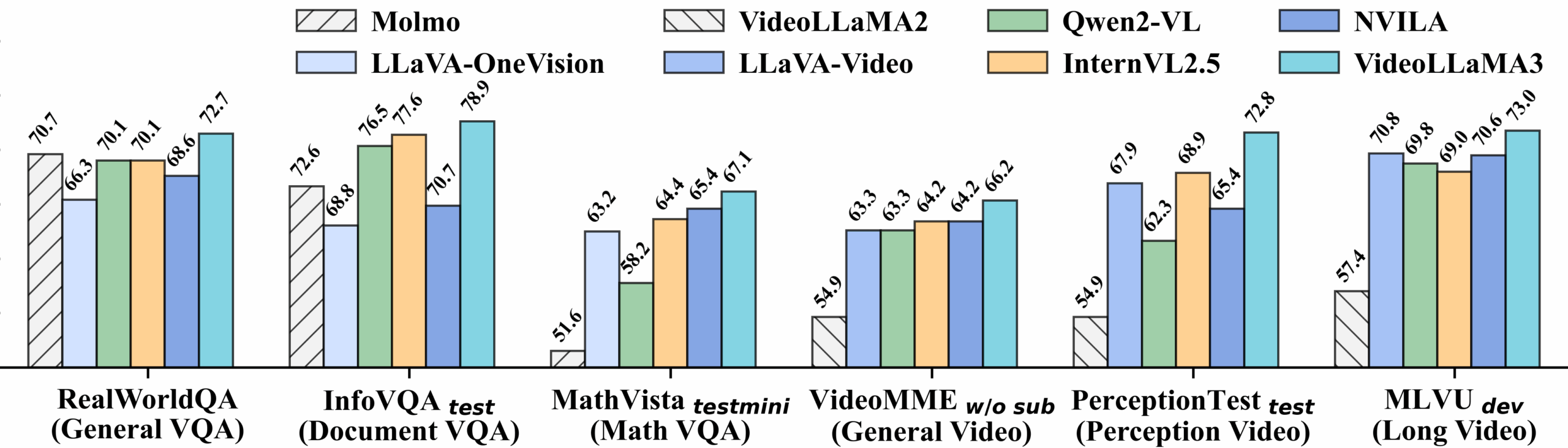
비디오 벤치마크 상세 성능:
이미지 벤치마크의 자세한 성능을 확인하세요.
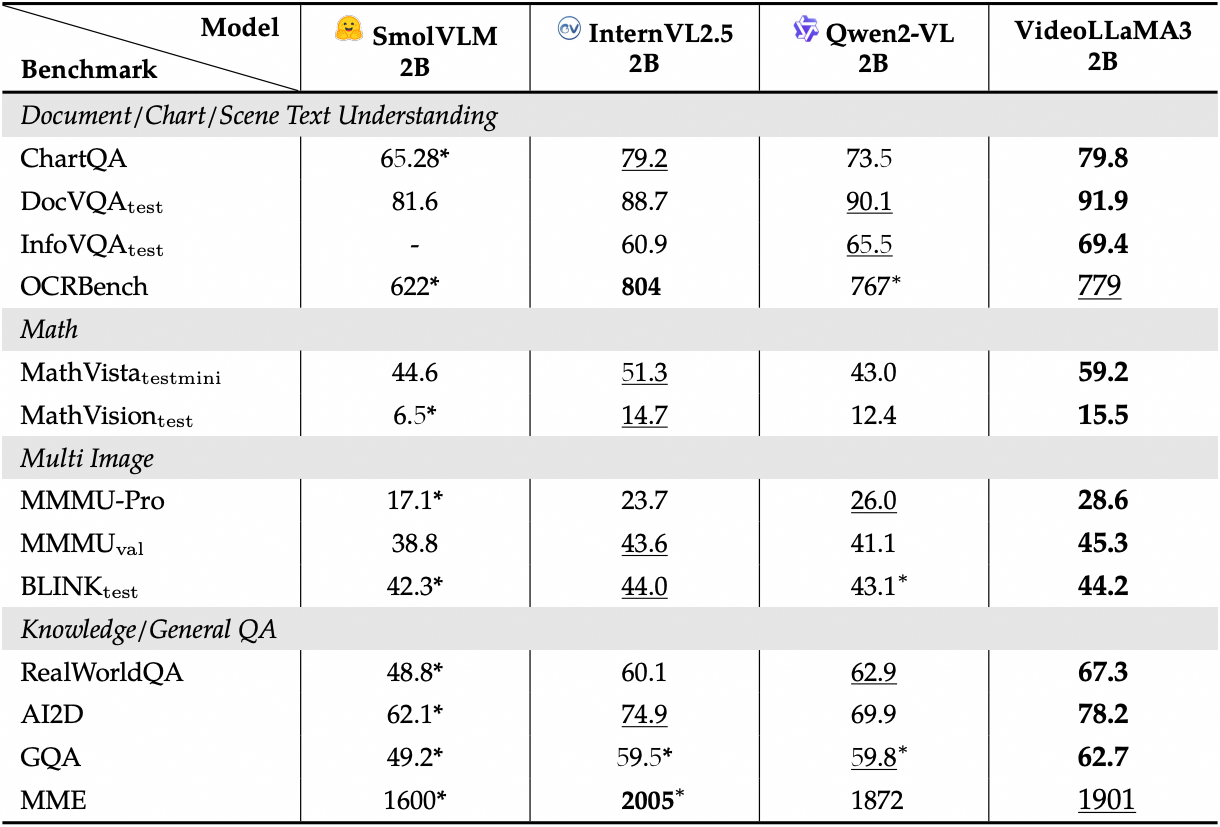
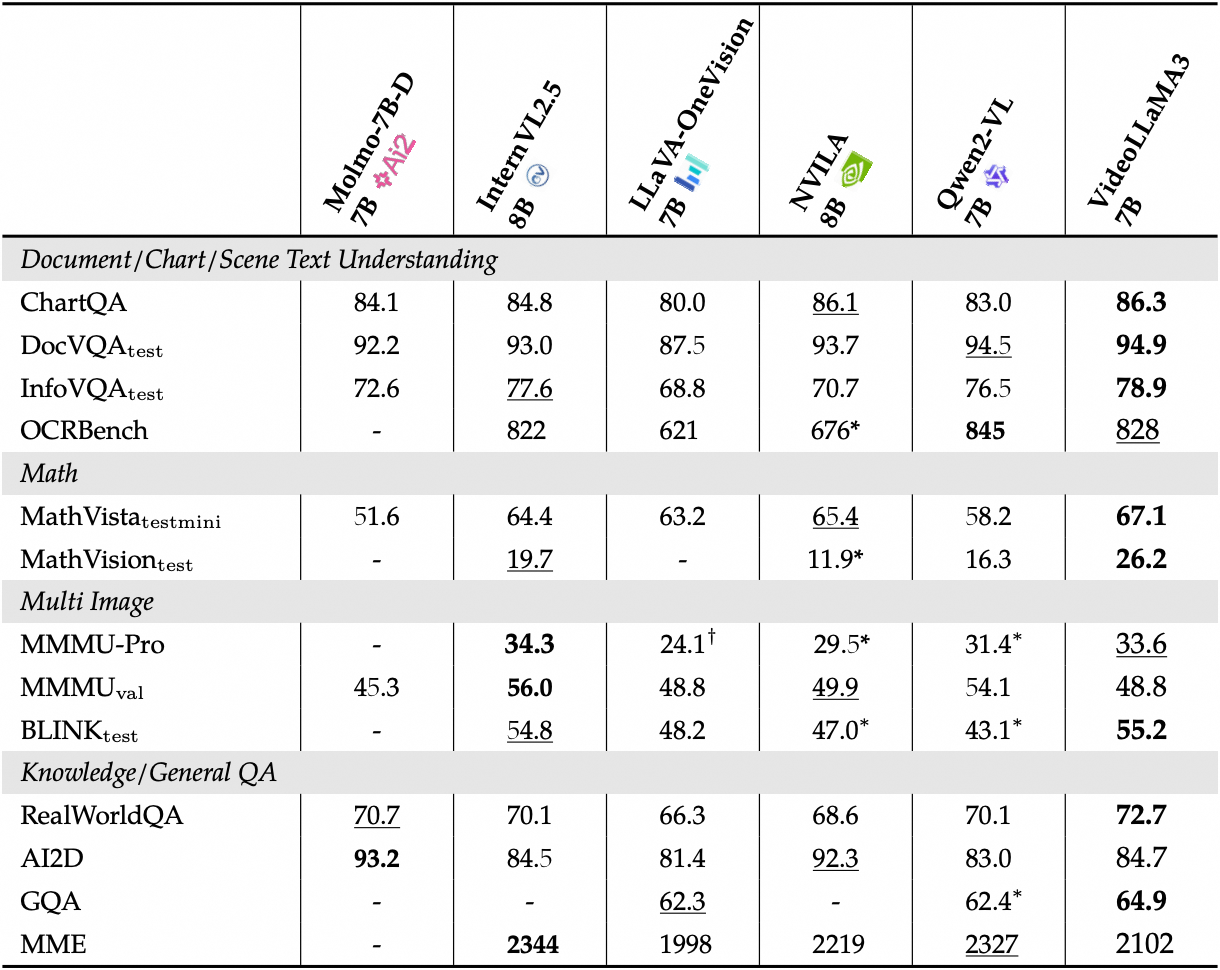
2. 작업 단계
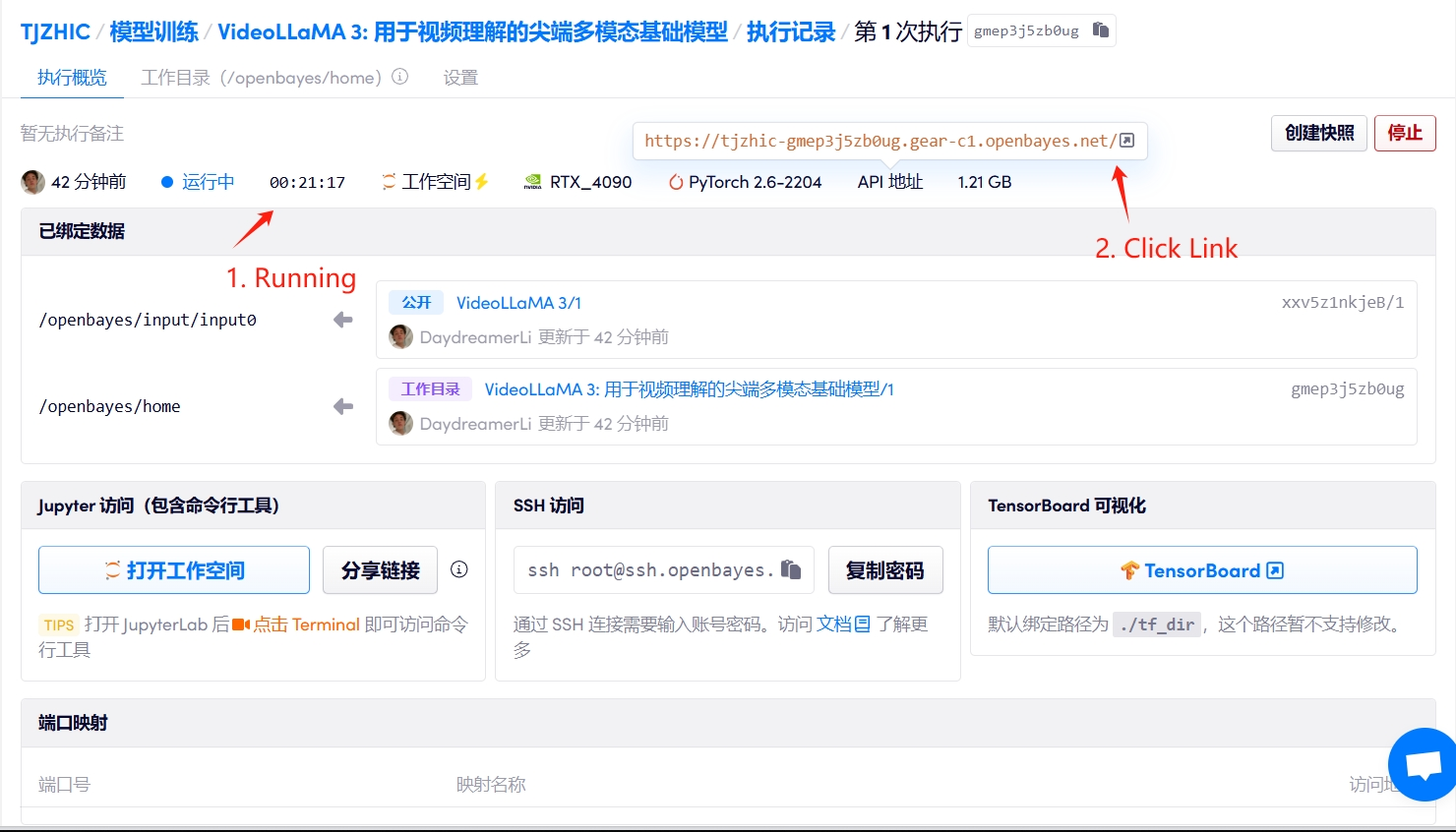
1. 컨테이너를 시작하세요
"잘못된 게이트웨이"가 표시되면 모델이 초기화 중임을 의미합니다. 모델이 크기 때문에 약 2~3분 정도 기다리신 후 페이지를 새로고침해 주시기 바랍니다.
2. 사용 단계
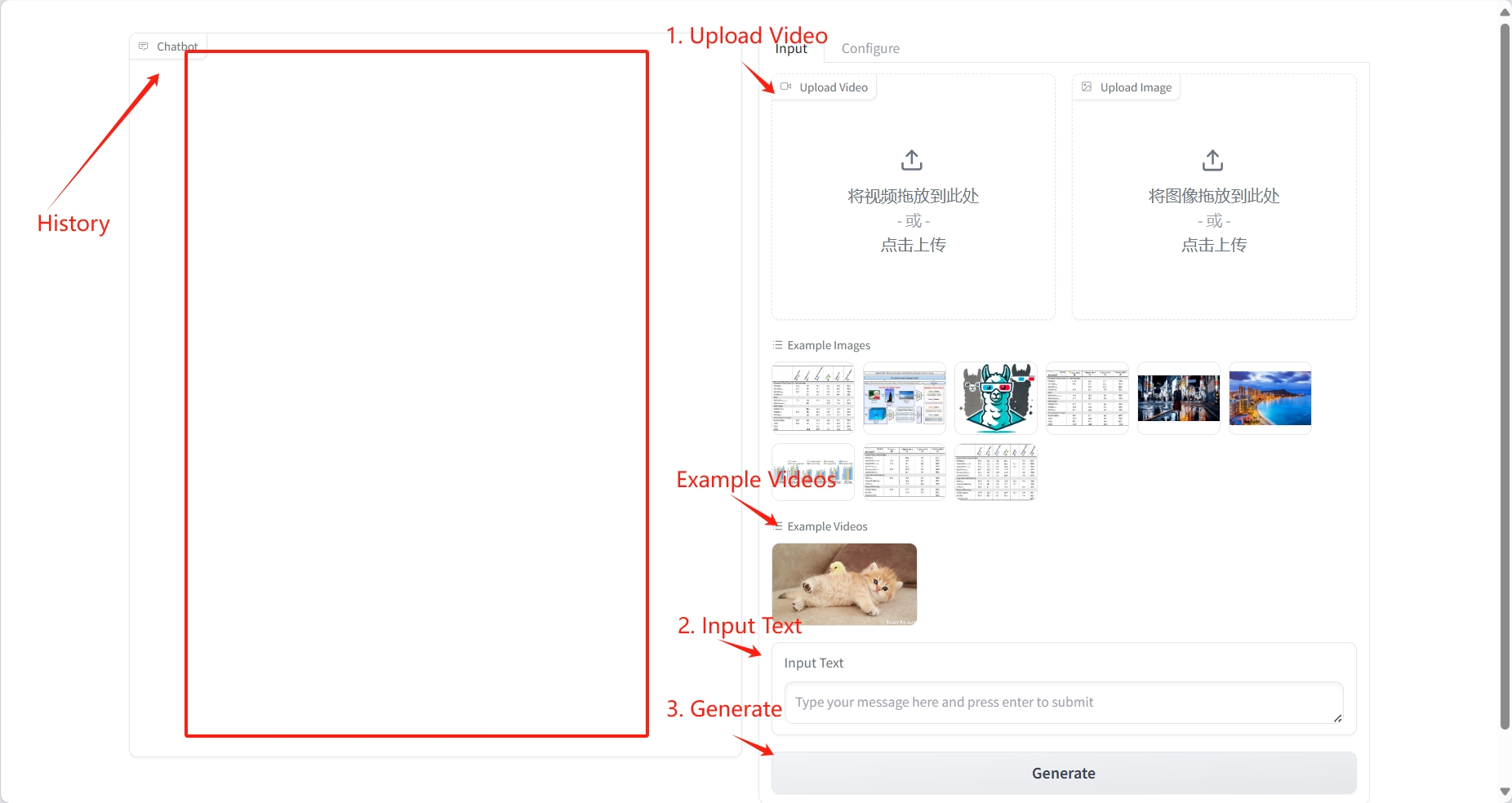
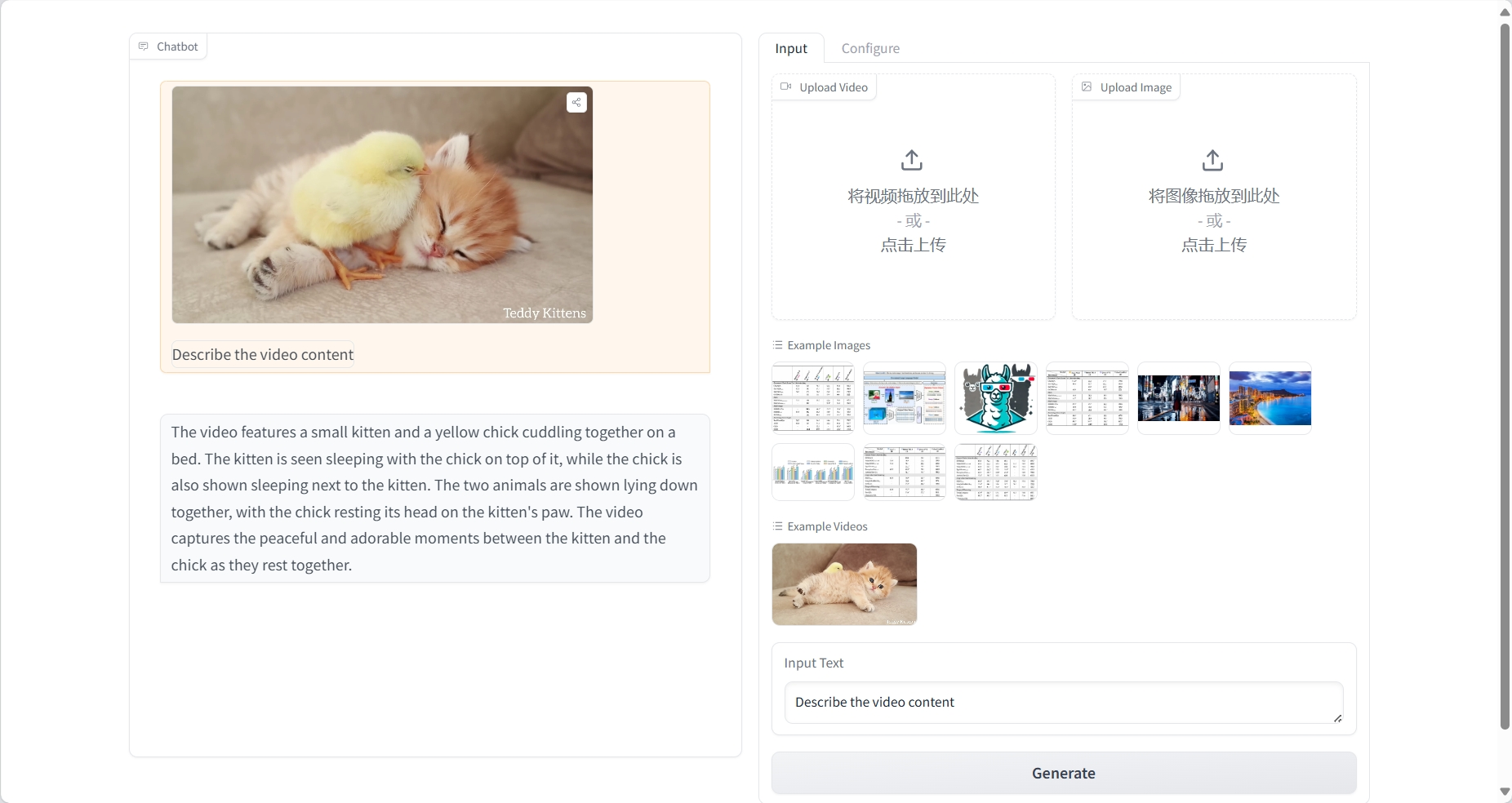
비디오 이해
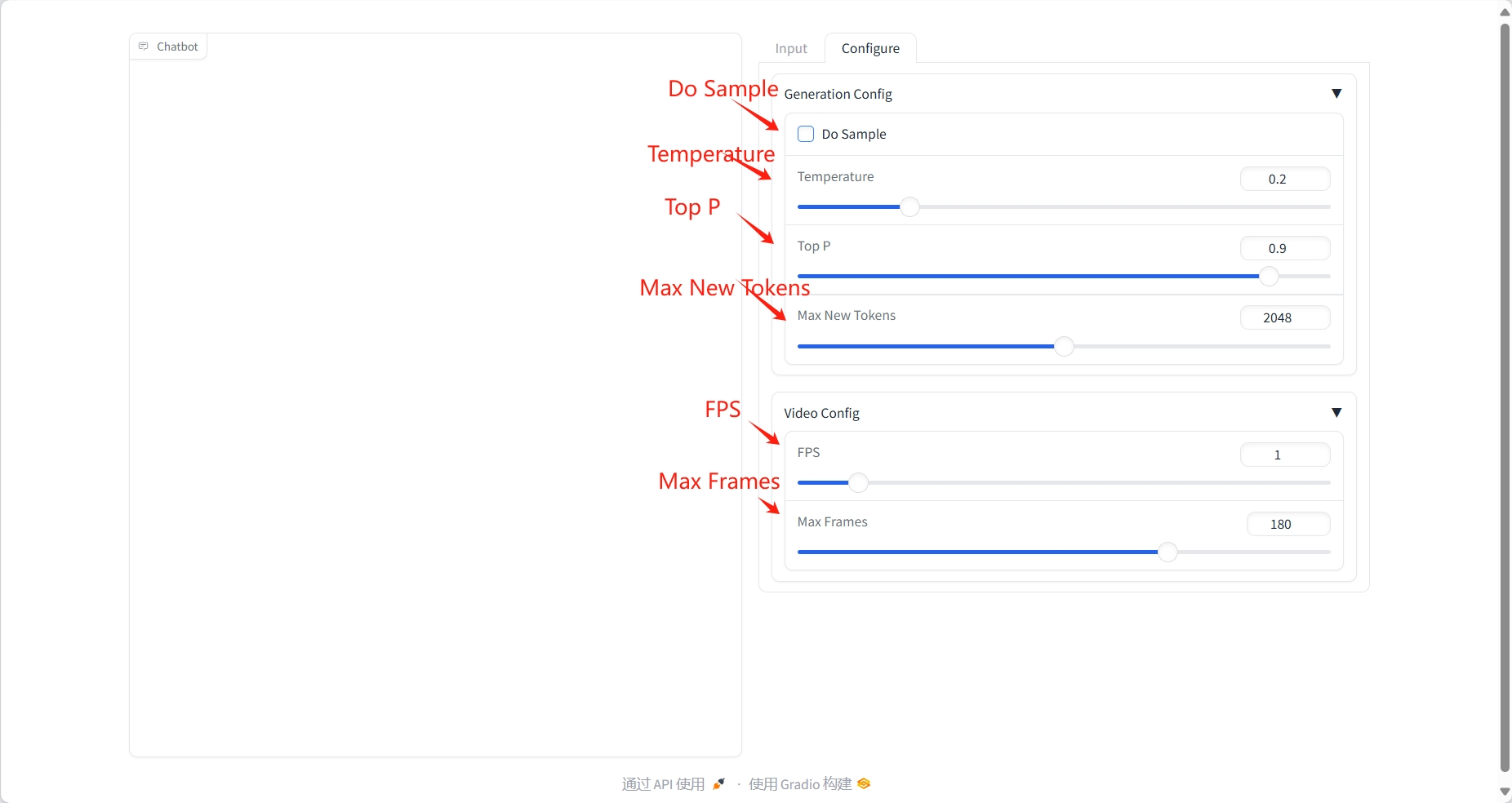
결과
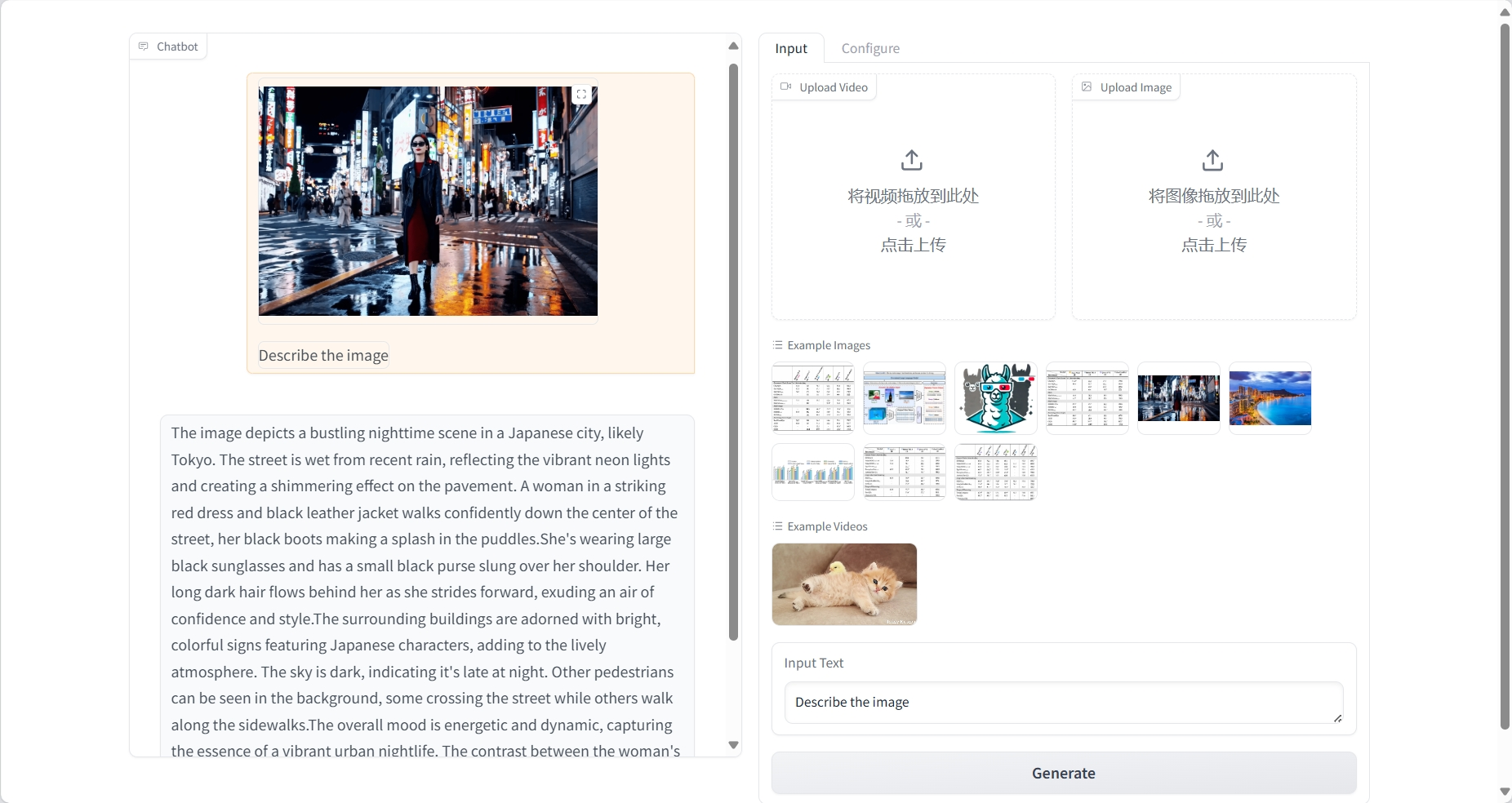
이미지 이해
결과
3. 토론
🖌️ 고품질 프로젝트를 발견하시면, 백그라운드에 메시지를 남겨 추천해주세요! 또한, 튜토리얼 교환 그룹도 만들었습니다. 친구들의 QR코드 스캔과 [SD 튜토리얼] 댓글을 통해 그룹에 가입하여 다양한 기술 이슈에 대해 논의하고 신청 결과를 공유해 주시기 바랍니다.↓

인용 정보
이 프로젝트에 대한 인용 정보는 다음과 같습니다.
@article{damonlpsg2025videollama3,
title={VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding},
author={Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, Peng Jin, Wenqi Zhang, Fan Wang, Lidong Bing, Deli Zhao},
journal={arXiv preprint arXiv:2501.13106},
year={2025},
url = {https://arxiv.org/abs/2501.13106}
}
@article{damonlpsg2024videollama2,
title={VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs},
author={Cheng, Zesen and Leng, Sicong and Zhang, Hang and Xin, Yifei and Li, Xin and Chen, Guanzheng and Zhu, Yongxin and Zhang, Wenqi and Luo, Ziyang and Zhao, Deli and Bing, Lidong},
journal={arXiv preprint arXiv:2406.07476},
year={2024},
url = {https://arxiv.org/abs/2406.07476}
}
@article{damonlpsg2023videollama,
title = {Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding},
author = {Zhang, Hang and Li, Xin and Bing, Lidong},
journal = {arXiv preprint arXiv:2306.02858},
year = {2023},
url = {https://arxiv.org/abs/2306.02858}
}