Command Palette
Search for a command to run...
MonkeyOCR: 구조-인식-관계 삼중 패러다임 기반 문서 분석
1. 튜토리얼 소개

MonkeyOCR은 화중과학기술대학교와 Kingsoft Office가 2025년 6월 5일 오픈소스로 공개한 문서 파싱 모델입니다. 이 모델은 비정형 문서 콘텐츠를 정형 정보로 효율적으로 변환하는 기능을 지원합니다. 정밀한 레이아웃 분석, 콘텐츠 인식, 논리적 정렬을 기반으로 문서 파싱의 정확도와 효율성이 크게 향상됩니다. 기존 방식과 비교했을 때, MonkeyOCR은 복잡한 문서(예: 수식 및 표가 포함된 문서) 처리에 뛰어난 성능을 보이며, 수식 및 표 파싱에서는 각각 평균 5.1%, 15.0%, 8.6%의 성능을 향상시킵니다. 또한, 여러 페이지 문서 처리에서도 초당 0.84페이지의 처리 속도를 기록하여 다른 유사 도구보다 훨씬 뛰어납니다. MonkeyOCR은 학술 논문, 교과서, 신문 등 다양한 문서 유형을 지원하며, 다국어 지원에 적합하여 문서 디지털화 및 자동화 처리를 강력하게 지원합니다. 관련 논문 결과는 "MonkeyOCR: 구조-인식-관계 삼중 패러다임을 사용한 문서 구문 분석".
주요 특징:
- 문서 구문 분석 및 구조화: 다양한 형식(예: PDF, 이미지 등)의 문서에 있는 비정형 콘텐츠(텍스트, 표, 수식, 이미지 등)를 구조화된 기계 판독 정보로 변환합니다.
- 다국어 지원: 중국어, 영어 등 여러 언어를 지원합니다.
- 복잡한 문서를 효율적으로 처리합니다. 복잡한 문서(수식, 표, 여러 열로 구성된 레이아웃 등이 포함된 문서)를 처리할 때 우수한 성능을 발휘합니다.
- 빠른 다중 페이지 문서 처리: 초당 0.84페이지의 처리 속도로 다중 페이지 문서를 효율적으로 처리합니다. 이는 다른 도구(예: MinerU는 초당 0.65페이지, Qwen2.5-VL-7B는 초당 0.12페이지)보다 훨씬 뛰어납니다.
- 유연한 배포 및 확장: 다양한 규모의 요구 사항을 충족하기 위해 단일 NVIDIA 3090 GPU에 효율적인 배포를 지원합니다.
기술 원리:
- 구조-인식-관계(SRR) 트리플렛 패러다임: YOLO 기반 문서 레이아웃 검출기로, 문서 내 주요 요소(예: 텍스트 블록, 표, 수식, 이미지 등)의 위치와 범주를 식별합니다. 검출된 각 영역에 대해 콘텐츠 인식을 수행하고, 높은 정확도를 보장하기 위해 대규모 다형성 모델(LMM)을 사용하여 종단 간 인식을 수행합니다. 블록 단위 읽기 순서 예측 메커니즘을 기반으로, 검출된 요소 간의 논리적 관계를 파악하여 문서의 의미 구조를 재구성합니다.
- MonkeyDoc 데이터셋: MonkeyDoc은 현재까지 가장 포괄적인 문서 파싱 데이터셋으로, 390만 개의 인스턴스를 포함하고 있으며 중국어와 영어로 된 10개 이상의 문서 유형을 포괄합니다. 이 데이터셋은 신중한 수동 주석, 프로그래밍 방식 합성, 그리고 모델 기반 자동 주석을 통합하는 다단계 파이프라인을 기반으로 구축되었습니다. MonkeyOCR 모델을 학습하고 평가하는 데 사용되어 다양하고 복잡한 문서 시나리오에서 강력한 일반화 기능을 보장합니다.
- 모델 최적화 및 배포: AdamW 옵티마이저와 코사인 학습률 스케줄링을 대규모 데이터셋과 함께 사용하여 모델 정확도와 효율성 간의 균형을 유지합니다. LMDeplov 도구를 기반으로 하는 MonkeyOCR은 단일 NVIDIA 3090 GPU에서 효율적으로 실행되어 빠른 추론과 대규모 배포를 지원합니다.
이 튜토리얼에서 사용된 컴퓨팅 리소스는 RTX 4090 카드 1개입니다.
2. 효과 표시
수식 문서 예

테이블 문서 예시

신문 예시

재무 보고서 예시


3. 작업 단계
1. 컨테이너를 시작하세요
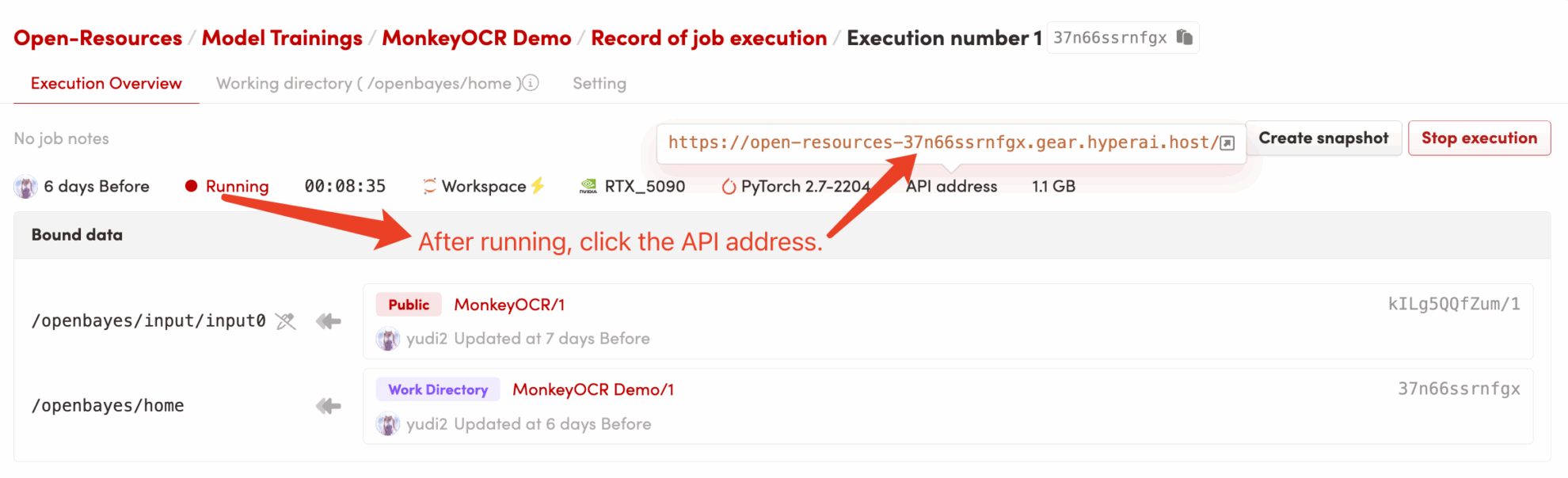
2. 사용 단계
"잘못된 게이트웨이"가 표시되면 모델이 초기화 중임을 의미합니다. 모델이 크기 때문에 약 2~3분 정도 기다리신 후 페이지를 새로고침해 주시기 바랍니다.

인용 정보
이 프로젝트에 대한 인용 정보는 다음과 같습니다.
@misc{li2025monkeyocrdocumentparsingstructurerecognitionrelation,
title={MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm},
author={Zhang Li and Yuliang Liu and Qiang Liu and Zhiyin Ma and Ziyang Zhang and Shuo Zhang and Zidun Guo and Jiarui Zhang and Xinyu Wang and Xiang Bai},
year={2025},
eprint={2506.05218},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.05218},
}