Command Palette
Search for a command to run...
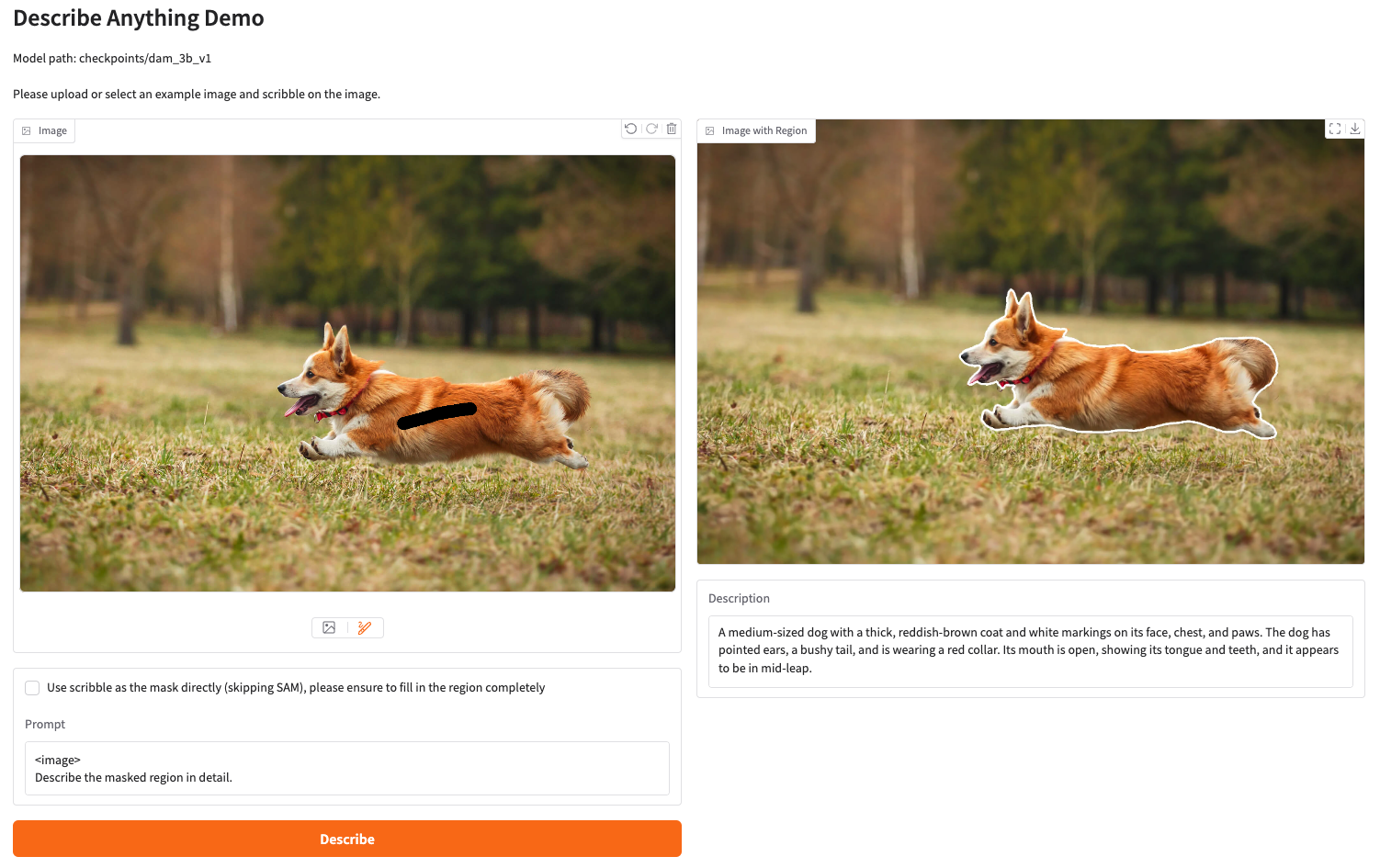
무엇이든 설명하는 모델 데모
프로젝트 개요

DAM(Drease Anything Model)은 NVIDIA, UC 버클리, UCSF 팀이 공동으로 개발하여 2025년에 출시된 혁신적인 이미지 및 비디오 설명 모델입니다. 이 모델은 사용자가 지정한 영역(점, 상자, 낙서, 마스크)을 기반으로 상세한 설명을 생성할 수 있습니다. 비디오 콘텐츠의 경우, 모든 프레임의 해당 영역에 주석을 달기만 하면 완전한 설명을 얻을 수 있습니다. 관련 논문 결과는 "무엇이든 설명하세요: 자세한 현지화된 이미지 및 비디오 캡션".
이 튜토리얼에서는 단일 RTX 4090 카드에 대한 리소스를 사용합니다.
프로젝트 예시
실행 단계
1. 컨테이너 시작 후 API 주소를 클릭하여 웹 인터페이스로 진입합니다.
"잘못된 게이트웨이"가 표시되면 모델이 초기화 중임을 의미합니다. 모델이 크기 때문에 1~2분 정도 기다리신 후 페이지를 새로고침해 주세요.
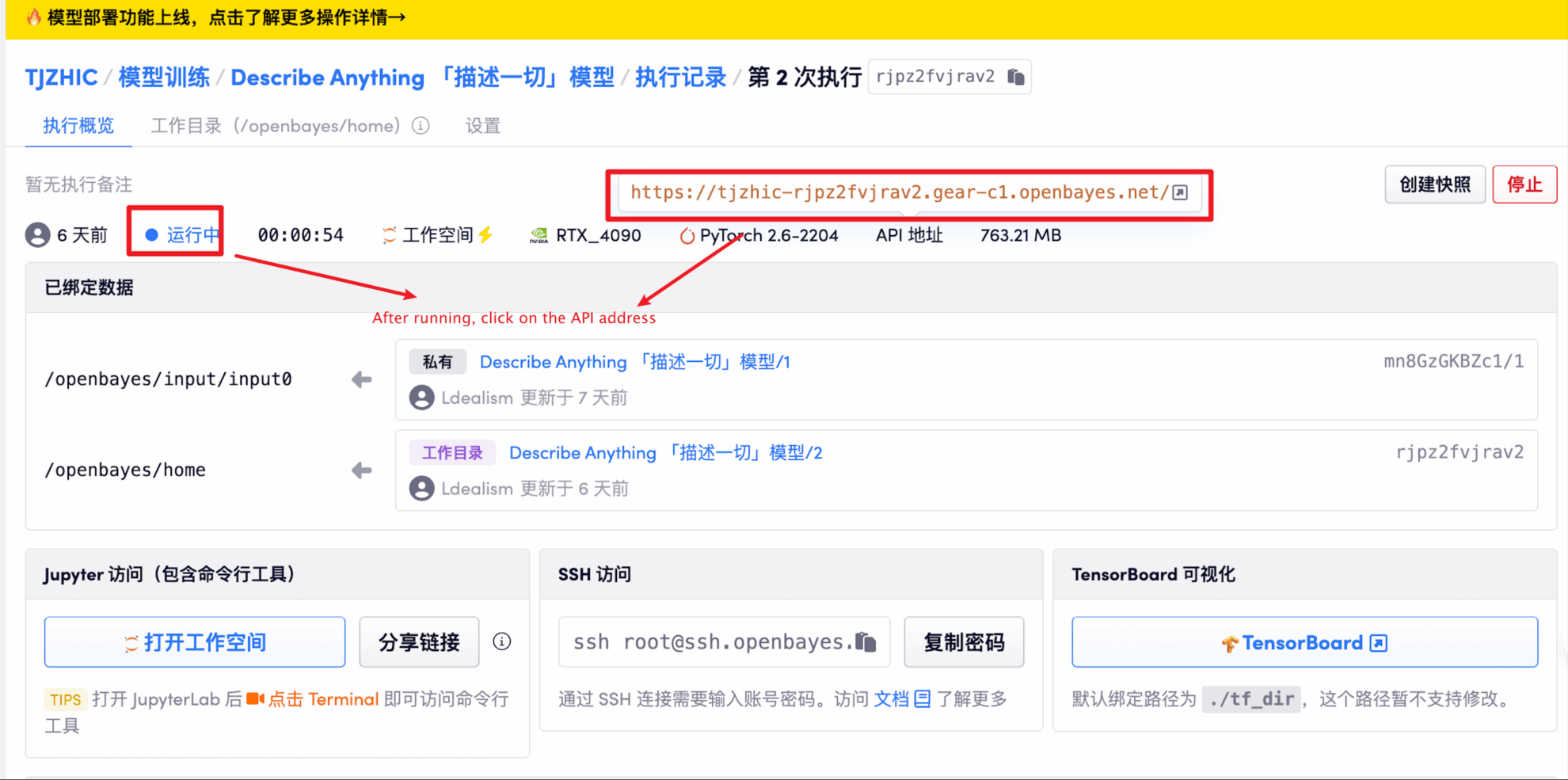
2. 웹 페이지에 접속하면 모델과 상호작용이 가능합니다.
이미지 크기는 5MB, 비디오 길이는 20초, 비디오 크기는 5MB를 초과할 수 없습니다. 5MB를 초과할 경우 모델 실행 속도가 느려지거나 오류가 발생할 수 있습니다. 설명 영역을 신중하게 선택해 주세요.
이 튜토리얼에서는 이미지 모드 모듈과 비디오 모드 모듈이라는 두 가지 모듈 테스트를 제공합니다.
각 모듈의 기능은 다음과 같습니다.
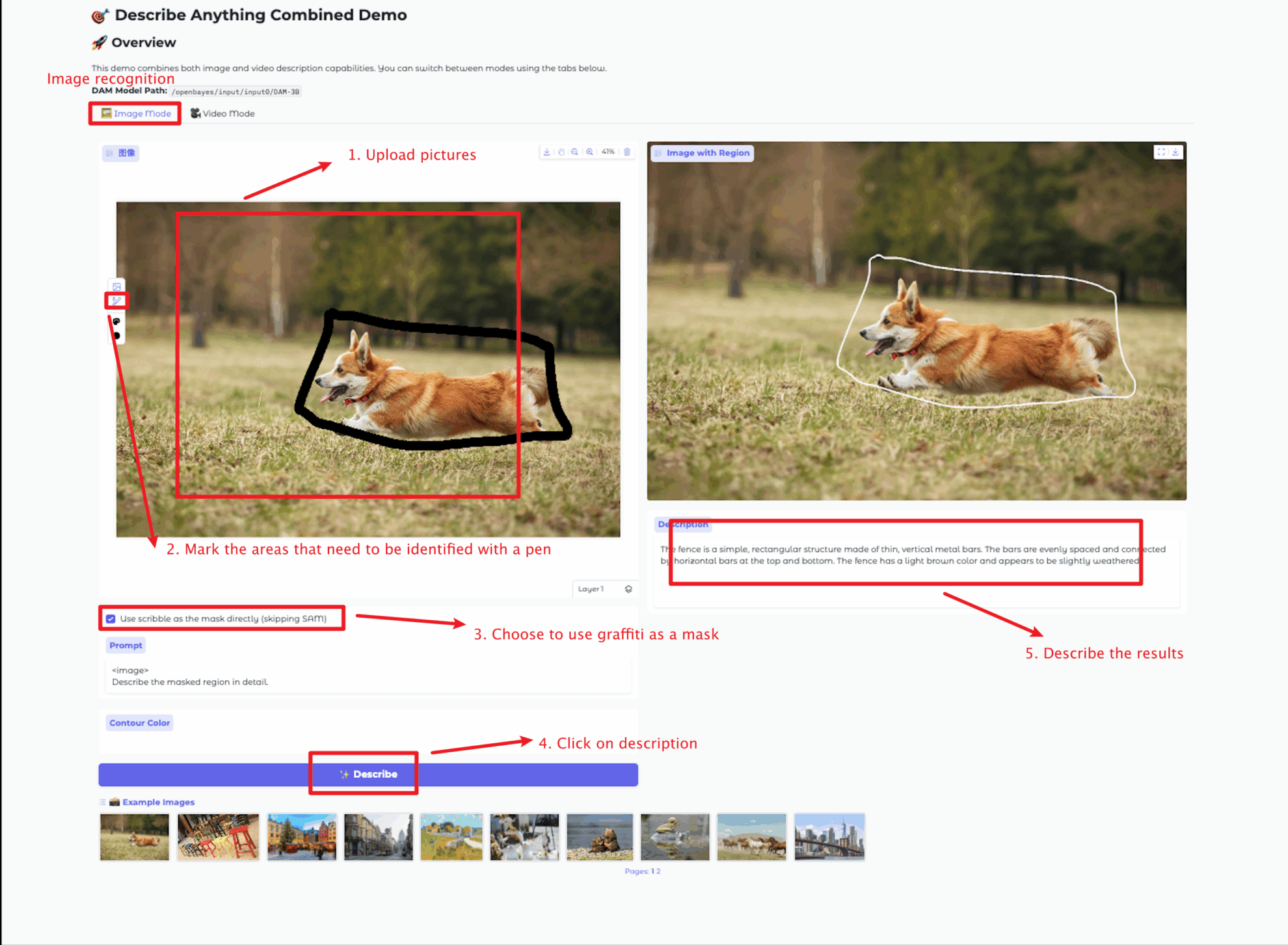
이미지 모드
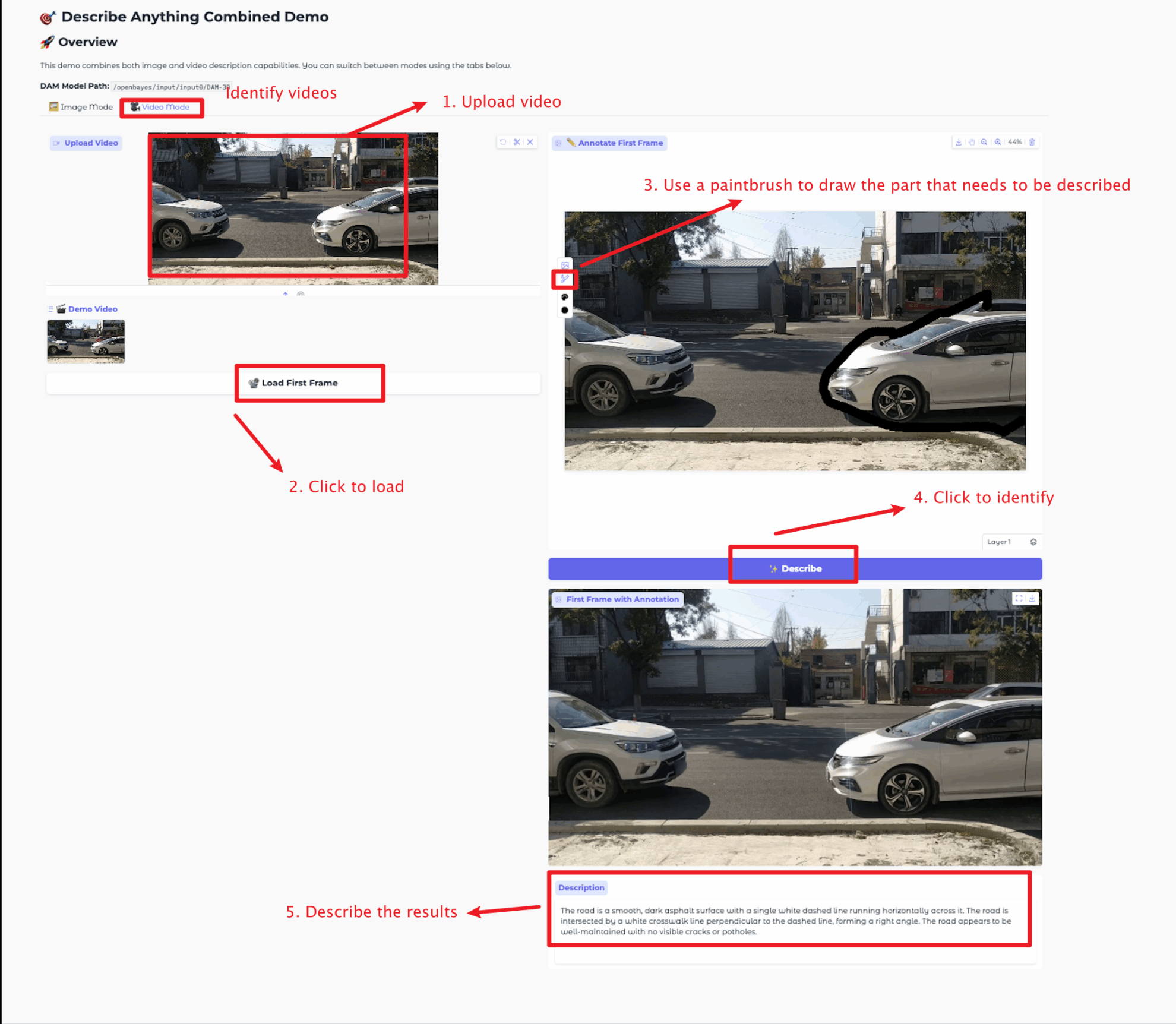
비디오 모드
교류 및 토론
🖌️ 고품질 프로젝트를 발견하시면, 백그라운드에 메시지를 남겨 추천해주세요! 또한, 튜토리얼 교환 그룹도 만들었습니다. 친구들의 QR코드 스캔과 [SD 튜토리얼] 댓글을 통해 그룹에 가입하여 다양한 기술 이슈에 대해 논의하고 신청 결과를 공유해 주시기 바랍니다.↓

인용 정보
Github 사용자에게 감사드립니다 장준창 이 튜토리얼을 배포하기 위한 프로젝트 참조 정보는 다음과 같습니다.
@article{lian2025describe,
title={Describe Anything: Detailed Localized Image and Video Captioning},
author={Long Lian and Yifan Ding and Yunhao Ge and Sifei Liu and Hanzi Mao and Boyi Li and Marco Pavone and Ming-Yu Liu and Trevor Darrell and Adam Yala and Yin Cui},
journal={arXiv preprint arXiv:2504.16072},
year={2025}
} GitHub Stars arXiv