이 튜토리얼에서는 리소스로 단일 카드 A6000을 사용합니다. 현재 AI 상호작용은 중국어와 영어만 지원합니다.
2. 프로젝트 예시
3. 작업 단계
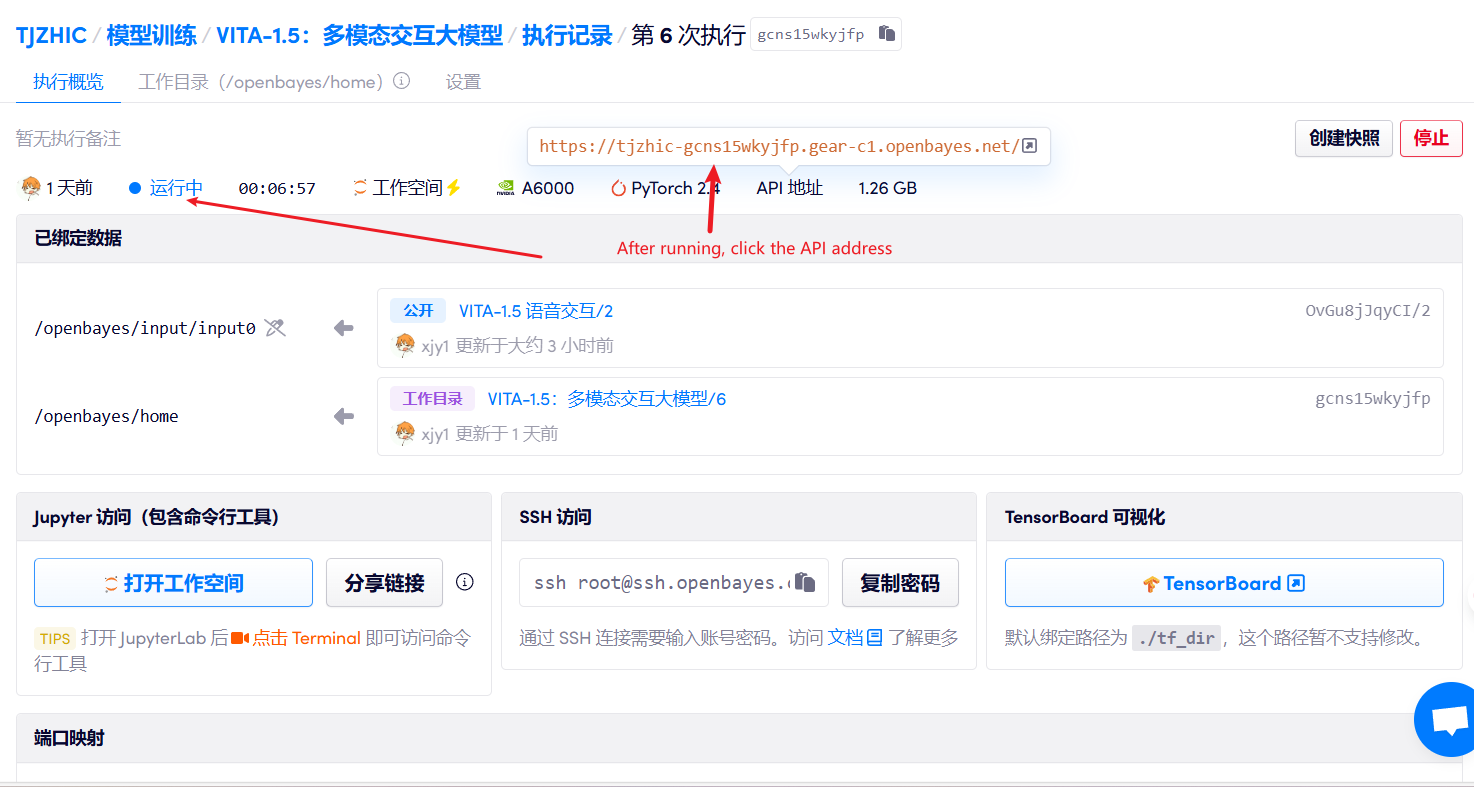
1. 컨테이너 시작 후 API 주소를 클릭하여 웹 인터페이스로 진입합니다.
"잘못된 게이트웨이"가 표시되면 모델이 초기화 중임을 의미합니다. 모델이 크기 때문에 1~2분 정도 기다리신 후 페이지를 새로고침해 주세요.
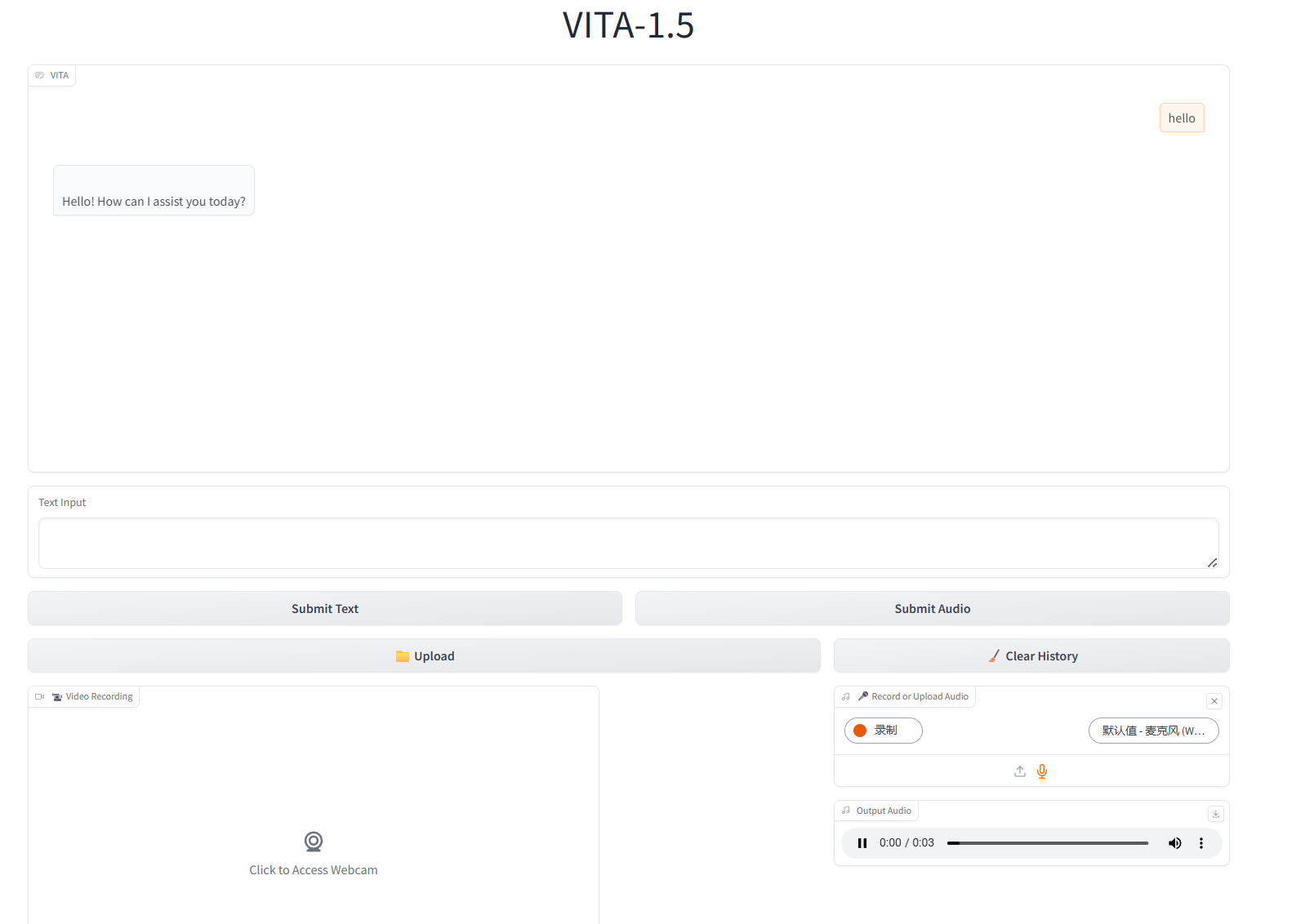
2. 웹페이지에 접속 후 모델과 대화를 시작할 수 있습니다.
Safari 브라우저를 사용하는 경우 오디오가 직접 재생되지 않을 수 있으며, 재생하기 전에 다운로드해야 합니다.
사용 방법
이 교과서에는 텍스트, 오디오, 비디오, 그림 등 다양한 AI 상호작용 방법이 나와 있습니다.
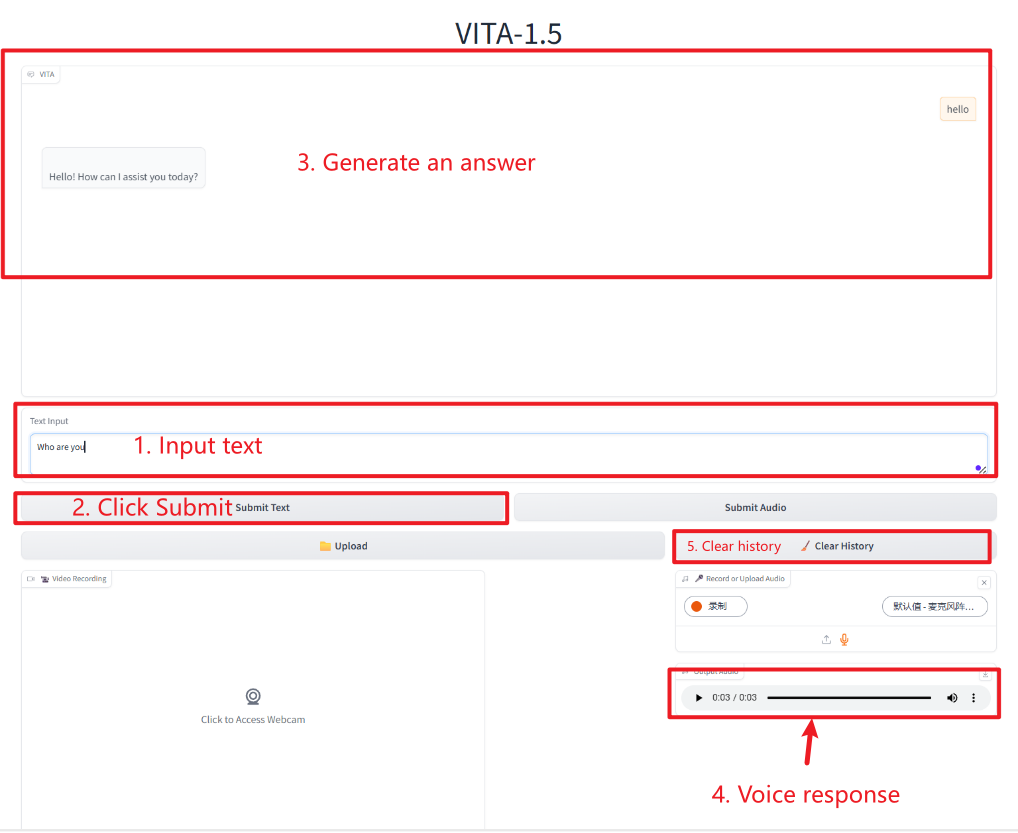
텍스트 상호작용
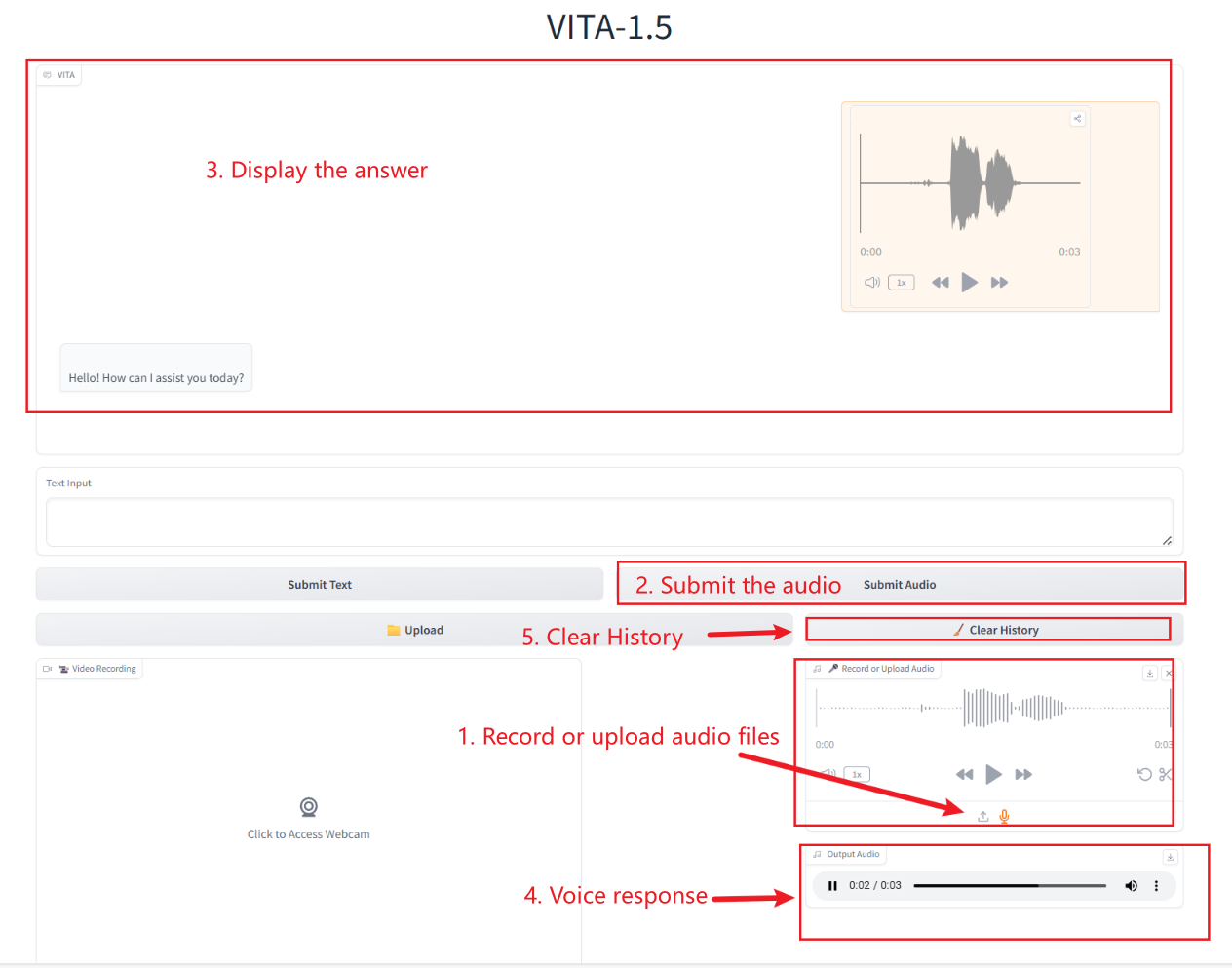
오디오 상호작용
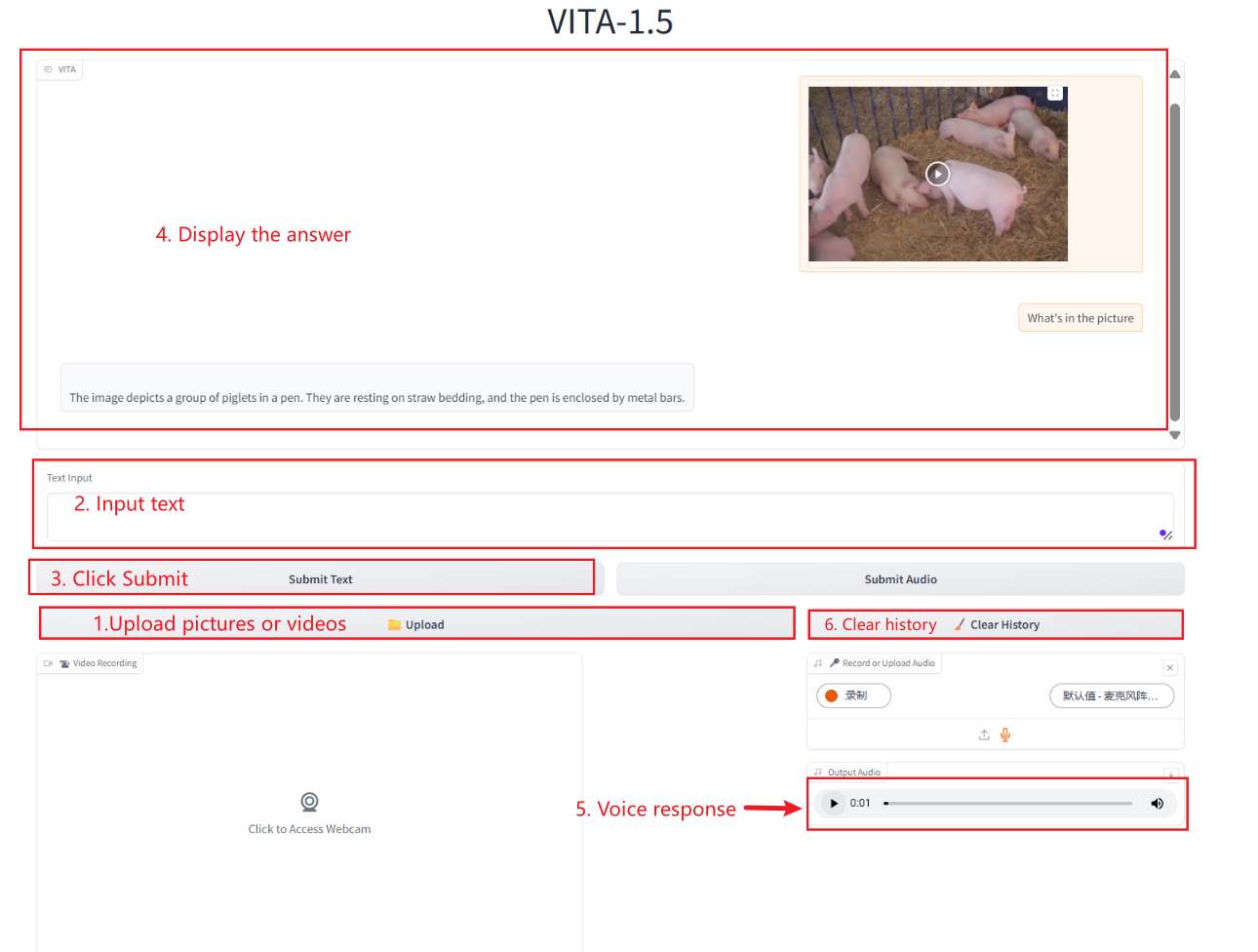
이미지/비디오 상호작용
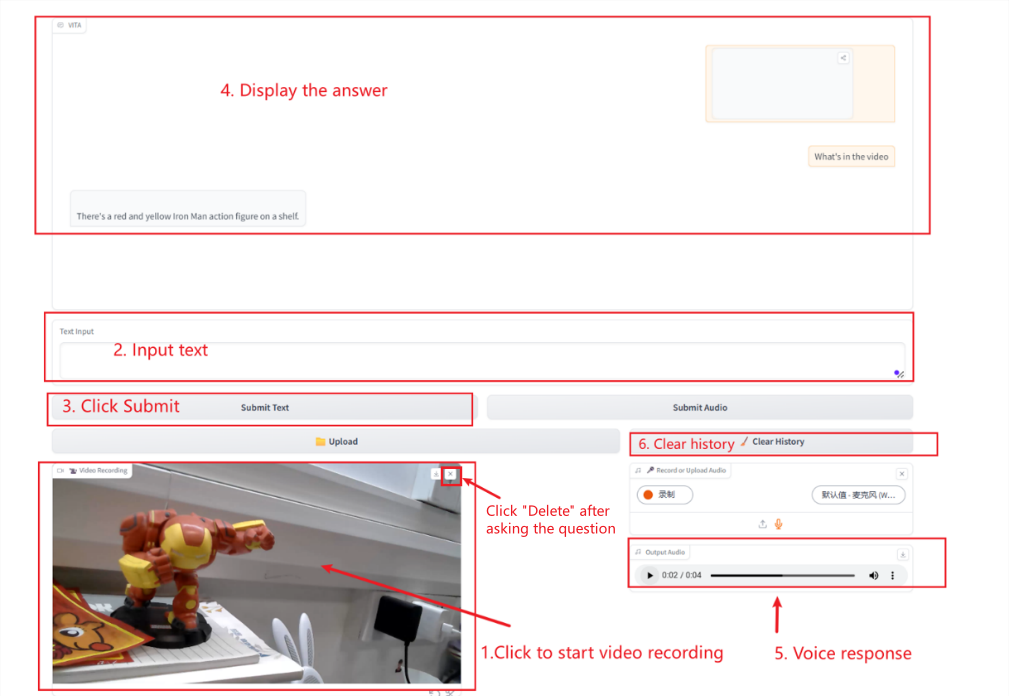
비디오 상호작용
메모:
카메라를 사용하여 영상을 녹화하는 경우, 질문이 완료되면 영상을 즉시 삭제해야 합니다.
4. 토론
🖌️ 고품질 프로젝트를 발견하시면, 백그라운드에 메시지를 남겨 추천해주세요! 또한, 튜토리얼 교환 그룹도 만들었습니다. 친구들의 QR코드 스캔과 [SD 튜토리얼] 댓글을 통해 그룹에 가입하여 다양한 기술 이슈에 대해 논의하고 신청 결과를 공유해 주시기 바랍니다.↓
인용 정보
이 프로젝트에 대한 인용 정보는 다음과 같습니다.
@article{fu2025vita,
title={VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction},
author={Fu, Chaoyou and Lin, Haojia and Wang, Xiong and Zhang, Yi-Fan and Shen, Yunhang and Liu, Xiaoyu and Li, Yangze and Long, Zuwei and Gao, Heting and Li, Ke and others},
journal={arXiv preprint arXiv:2501.01957},
year={2025}
}
@article{fu2024vita,
title={Vita: Towards open-source interactive omni multimodal llm},
author={Fu, Chaoyou and Lin, Haojia and Long, Zuwei and Shen, Yunhang and Zhao, Meng and Zhang, Yifan and Dong, Shaoqi and Wang, Xiong and Yin, Di and Ma, Long and others},
journal={arXiv preprint arXiv:2408.05211},
year={2024}
}
AI로 AI 구축
아이디어에서 출시까지 — 무료 AI 공동 코딩, 즉시 사용 가능한 환경, 최적 가격 GPU로 AI 개발을 가속화하세요.