MegaTTS 3: 최첨단 제로샷 TTS 음성 품질을 구현하고 악센트 강도의 매우 유연한 제어를 지원하는 혁신적인 희소 정렬 가이드 "잠재 확산 변환기" 알고리즘을 탑재한 TTS 시스템입니다. 입력 음색을 복제하여 요구 사항에 따라 특정 오디오 콘텐츠를 생성하는 데 사용할 수 있습니다.
2. 작업 단계
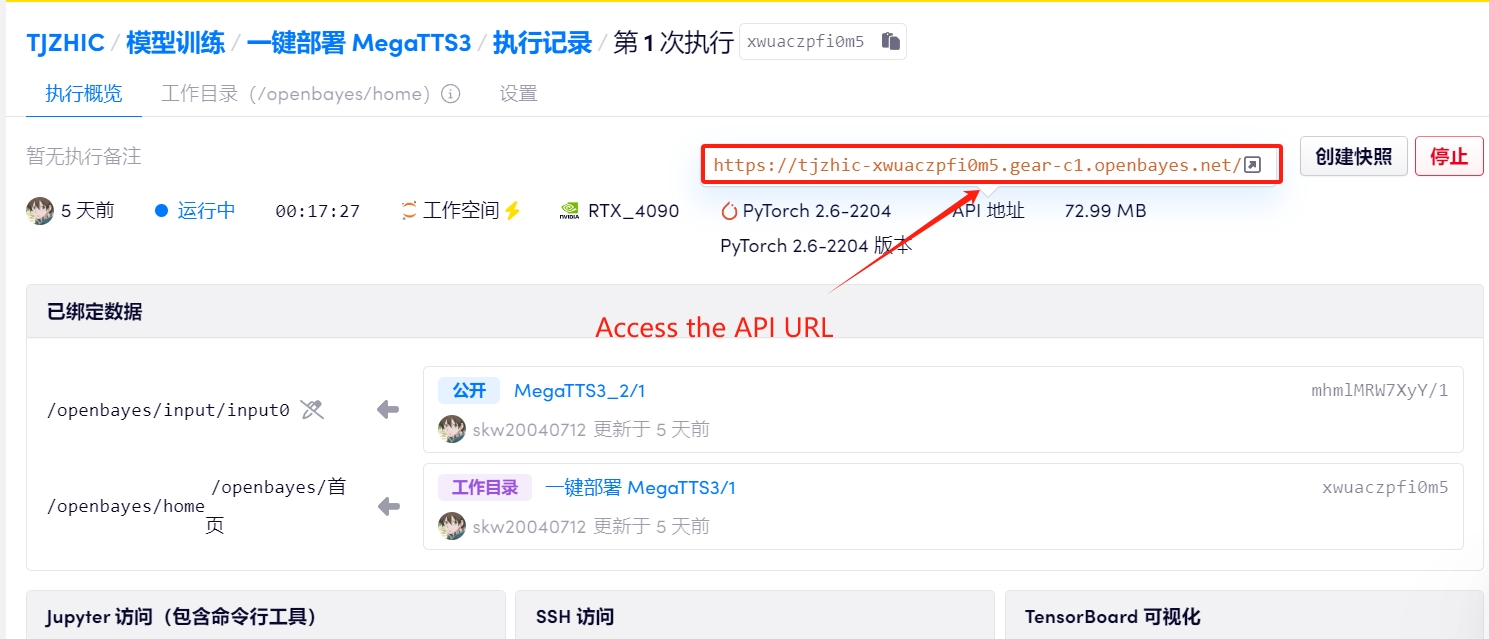
1. 컨테이너 시작 후 API 주소를 클릭하여 웹 인터페이스로 진입합니다.
"잘못된 게이트웨이"가 표시되면 모델이 초기화 중임을 의미합니다. 모델이 크기 때문에 1~2분 정도 기다리신 후 페이지를 새로고침해 주세요.
2. 웹페이지에 접속하시면 MegaTTS 3를 이용하실 수 있습니다.
사용 방법
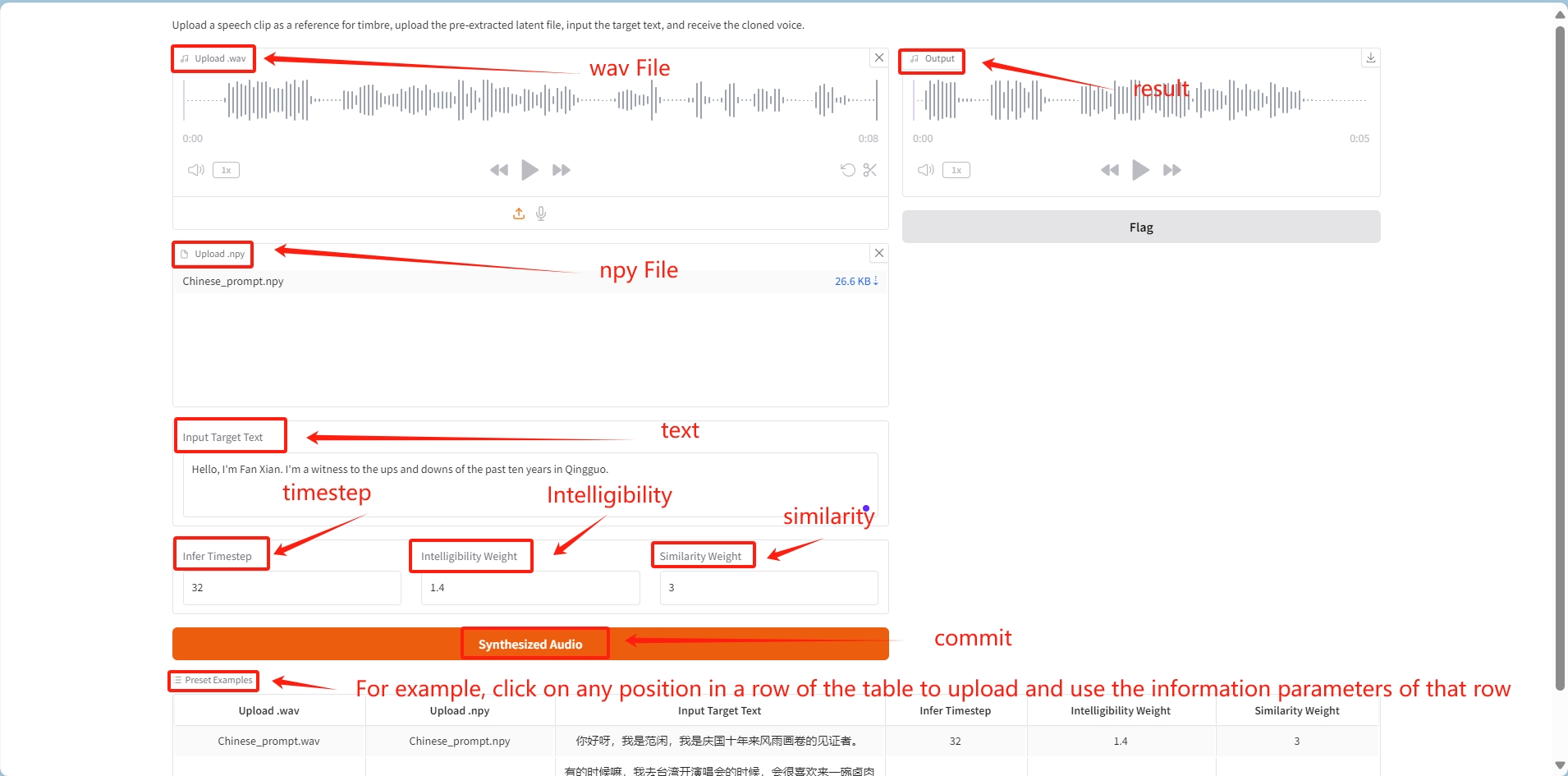
① wav 오디오 파일과 그에 따라 생성된 npy 파일을 따로 업로드합니다.
② input_text에 지정된 텍스트를 입력합니다.
③ 제출 후, 오디오 파일의 음색이 복제되어 input_text의 텍스트에 해당하는 오디오가 생성됩니다.
❗️매개변수 설명:
타임스텝 추론: 모델이 사운드를 생성하는 시간 단계에 영향을 미치며, 일반적으로 생성 프로세스에서 시간 단계 수를 제어합니다. 더 작은 타임스텝을 사용하면 모델이 사운드 특징을 세부적으로 조정할 수 있는 타임스텝이 더 많아지므로 사운드가 더 부드러워질 수 있습니다.
이해도 무게: 소리의 선명도와 이해도를 조절합니다. 가중치가 높을수록 사운드가 더 선명해지고 정보를 정확하게 전달해야 하는 장면에 적합하지만, 일부 자연스러움이 희생될 수 있습니다.
유사성 가중치: 생성된 사운드가 원래 사운드와 얼마나 유사한지를 제어합니다. 가중치가 높을수록 소리가 원래 소리에 가까워지므로 대상 음성을 충실하게 재현해야 하는 시나리오에 적합합니다.
🖌️ 고품질 프로젝트를 발견하시면, 백그라운드에 메시지를 남겨 추천해주세요! 또한, 튜토리얼 교환 그룹도 만들었습니다. 친구들의 QR코드 스캔과 [SD 튜토리얼] 댓글을 통해 그룹에 가입하여 다양한 기술 이슈에 대해 논의하고 신청 결과를 공유해 주시기 바랍니다.↓
인용 정보
Github 사용자에게 감사드립니다 키아스디크 이 튜토리얼 제작을 위한 프로젝트 참조 정보는 다음과 같습니다.
@article{jiang2025sparse,
title={Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis},
author={Jiang, Ziyue and Ren, Yi and Li, Ruiqi and Ji, Shengpeng and Ye, Zhenhui and Zhang, Chen and Jionghao, Bai and Yang, Xiaoda and Zuo, Jialong and Zhang, Yu and others},
journal={arXiv preprint arXiv:2502.18924},
year={2025}
}
@article{ji2024wavtokenizer,
title={Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling},
author={Ji, Shengpeng and Jiang, Ziyue and Wang, Wen and Chen, Yifu and Fang, Minghui and Zuo, Jialong and Yang, Qian and Cheng, Xize and Wang, Zehan and Li, Ruiqi and others},
journal={arXiv preprint arXiv:2408.16532},
year={2024}
}
AI로 AI 구축
아이디어에서 출시까지 — 무료 AI 공동 코딩, 즉시 사용 가능한 환경, 최적 가격 GPU로 AI 개발을 가속화하세요.