Qwen3는 Qwen 시리즈의 최신 세대 대규모 언어 모델로, 포괄적인 밀집 모델과 전문가 혼합(MoE) 모델을 제공합니다. Qwen3는 풍부한 교육 경험을 바탕으로 추론, 지시 따르기, 에이전트 기능 및 다국어 지원 측면에서 획기적인 진전을 이루었습니다. Qwen3의 적용 시나리오는 매우 광범위합니다. 텍스트, 이미지, 오디오, 비디오 처리를 지원하며, 멀티모달 콘텐츠 제작과 크로스모달 작업의 요구 사항을 충족할 수 있습니다. 기업 수준 애플리케이션에서 Qwen3의 에이전트 기능과 다국어 지원을 통해 의료 진단, 법률 문서 분석, 고객 서비스 자동화와 같은 복잡한 작업을 처리할 수 있습니다. 또한 Qwen3-0.6B와 같은 소형 모델은 휴대전화와 같은 단말 장치에 배포하는 데 적합하여 적용 시나리오를 더욱 확장할 수 있습니다.
최신 버전 Qwen3에는 다음과 같은 기능이 있습니다.
전체 크기의 고밀도 및 혼합 전문가 모델: 0.6B, 1.7B, 4B, 8B, 14B, 32B 및 30B-A3B, 235B-A22B
복잡한 논리적 추론, 수학, 코딩을 위한 사고 모드와 효율적인 일반 대화를 위한 비사고 모드 간의 원활한 전환을 지원하여 다양한 시나리오에서 최적의 성능을 보장합니다.
추론 능력이 크게 향상되어 수학, 코드 생성, 상식적 논리 추론 분야에서 이전의 QwQ(사고 모드) 및 Qwen2.5 교육 모델(비사고 모드)을 능가합니다.
인간의 선호도에 탁월하게 부합하며, 창의적 글쓰기, 롤플레잉, 멀티턴 대화, 명령 수행에 탁월하여 보다 자연스럽고 매력적이며 몰입감 넘치는 대화 경험을 제공합니다.
지능형 에이전트 기능에 탁월하고, 사고 모드와 비사고 모드 모두에서 외부 도구를 정확하게 통합할 수 있으며, 복잡한 에이전트 기반 작업에서 오픈 소스 모델을 선도합니다.
100개 이상의 언어와 방언을 지원하고, 강력한 다국어 이해, 추론, 명령 수행 및 생성 기능을 갖추고 있습니다.
2. 작업 단계
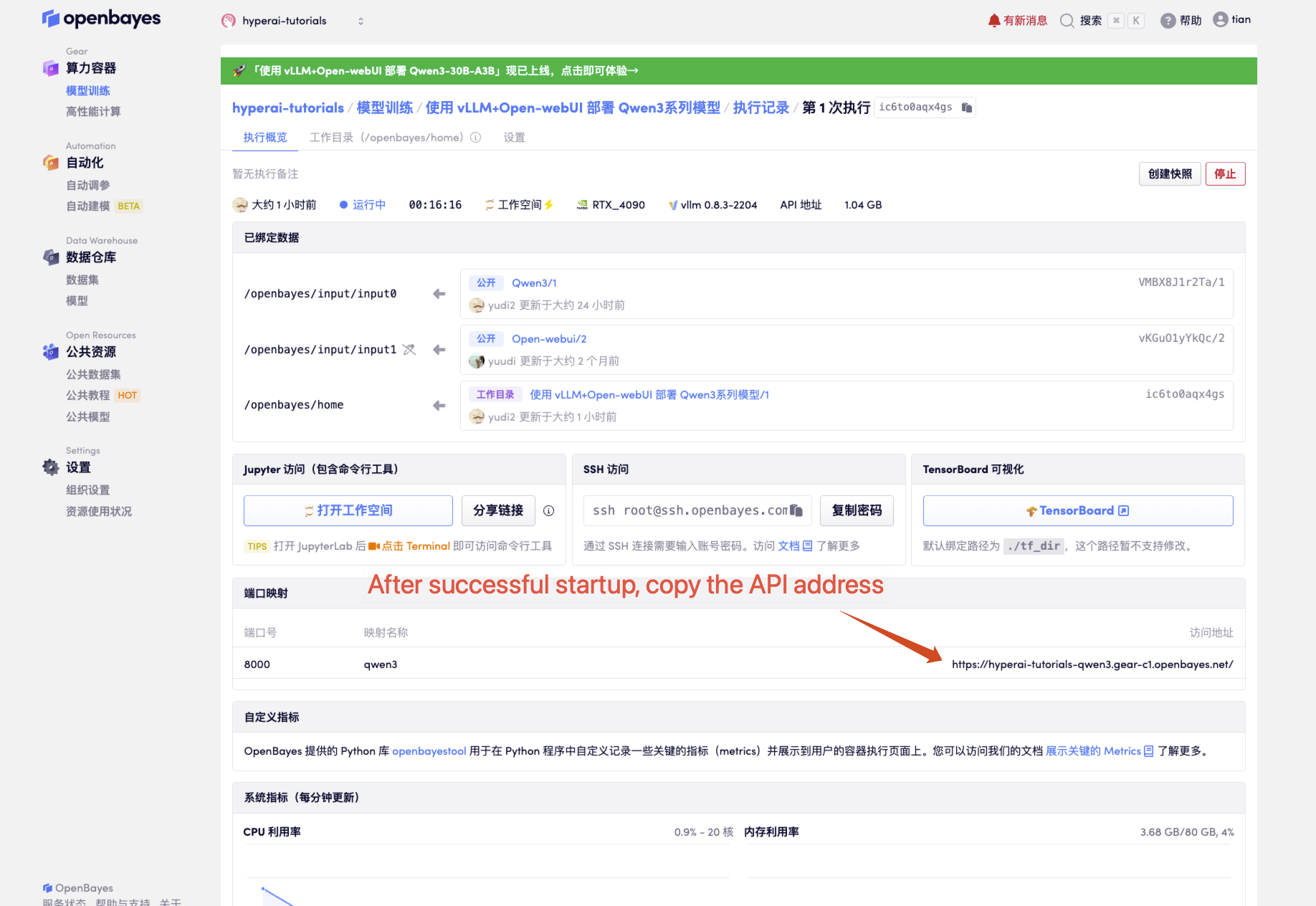
1. 컨테이너 시작 후 API 주소를 클릭하여 웹 인터페이스로 진입합니다.
"모델"이 표시되지 않으면 모델이 초기화되고 있음을 의미합니다. 모델이 크기 때문에 1~2분 정도 기다리신 후 페이지를 새로고침해 주세요.
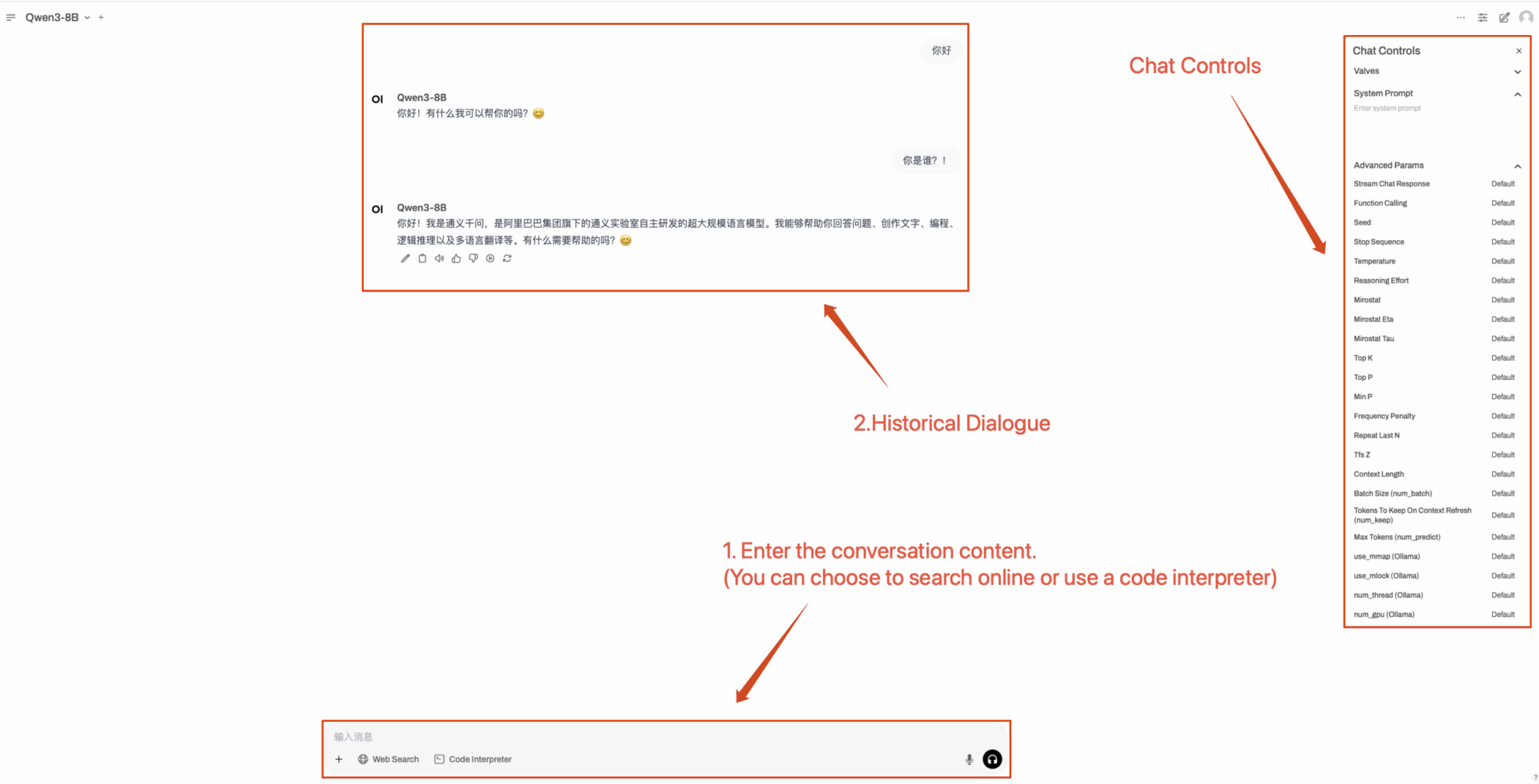
2. 웹페이지에 접속 후 모델과 대화를 시작할 수 있습니다.
사용 방법
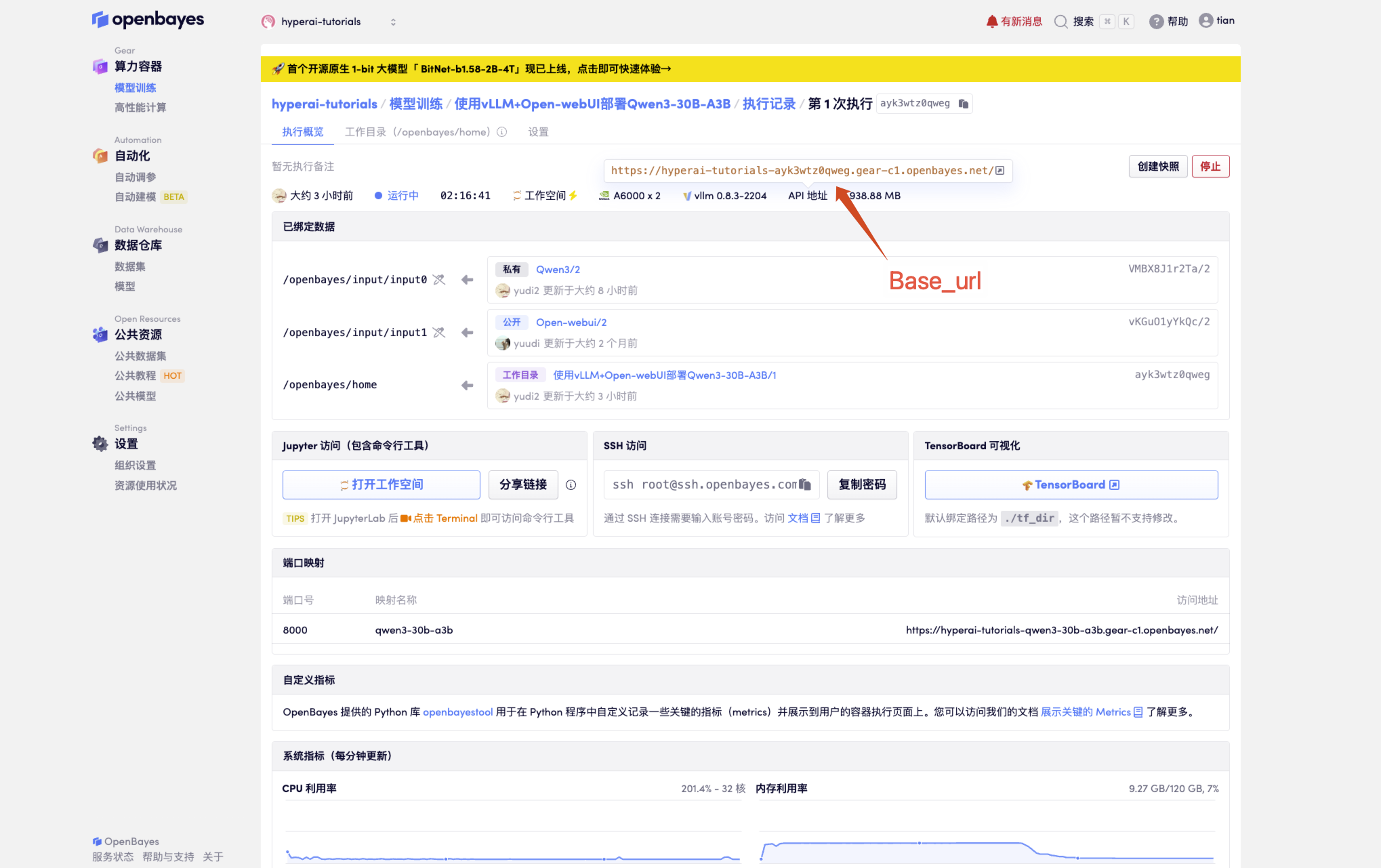
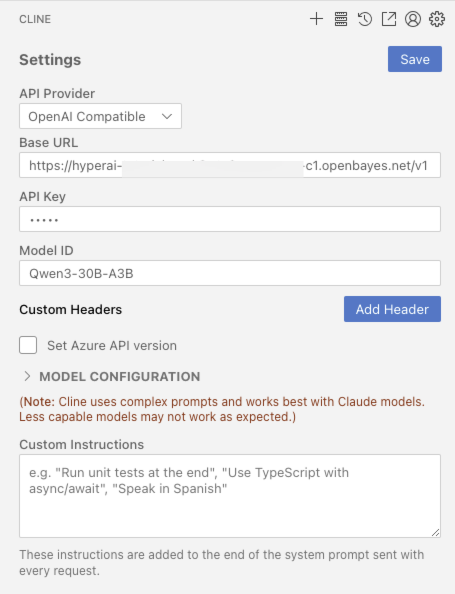
3. OpenAI API 호출 가이드
다음은 API 호출 방법에 대한 최적화된 설명으로, 구조를 더 명확하게 하고 실제적인 세부 정보를 추가했습니다.
/input0/Qwen3-4B → 대상 모델 경로로 교체합니다(예: Qwen3-1.7B).
--served-model-name → 해당 모델명으로 변경(예: Qwen3-1.7B).
완료되면 새로운 모델을 사용할 수 있습니다! 🚀
교류 및 토론
🖌️ 고품질 프로젝트를 발견하시면, 백그라운드에 메시지를 남겨 추천해주세요! 또한, 튜토리얼 교환 그룹도 만들었습니다. 친구들의 QR코드 스캔과 [SD 튜토리얼] 댓글을 통해 그룹에 가입하여 다양한 기술 이슈에 대해 논의하고 신청 결과를 공유해 주시기 바랍니다.↓
인용 정보
이 프로젝트에 대한 인용 정보는 다음과 같습니다.
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}
AI로 AI 구축
아이디어에서 출시까지 — 무료 AI 공동 코딩, 즉시 사용 가능한 환경, 최적 가격 GPU로 AI 개발을 가속화하세요.