Command Palette
Search for a command to run...
Qwen2.5-Omni는 읽기, 듣기, 말하기, 쓰기의 모든 모드를 열어줍니다.
1. 튜토리얼 소개
Qwen2.5-Omni는 Alibaba Tongyi Qianwen 팀이 2025년 3월 27일에 출시한 최신 엔드투엔드 멀티모달 플래그십 모델입니다. 포괄적인 멀티모달 인식을 위해 설계되었으며 텍스트, 이미지, 오디오, 비디오 등 다양한 입력을 원활하게 처리하는 동시에 스트리밍 텍스트 생성과 자연스러운 음성 합성 출력을 지원합니다.
주요 특징
- 모든 면에서 혁신적인 아키텍처: 텍스트/이미지/오디오/비디오에 대한 크로스 모달 이해를 지원하도록 설계된 엔드 투 엔드 멀티모달 모델인 새로운 Thinker-Talker 아키텍처를 채택하여 스트리밍 방식으로 텍스트와 자연스러운 음성 응답을 생성합니다. 연구팀은 시간 축 정렬을 통해 비디오 및 오디오 입력의 정밀한 동기화를 달성하는 TMRoPE(Time-aligned Multimodal RoPE)라는 새로운 위치 코딩 기술을 제안했습니다.
- 실시간 오디오 및 비디오 상호작용: 이 아키텍처는 완전한 실시간 상호작용을 지원하도록 설계되었으며, 청크 입력과 즉각적인 출력을 지원합니다.
- 자연스럽고 유창한 음성 생성: 음성 생성의 자연스러움과 안정성 측면에서 기존의 스트리밍 및 비스트리밍 대안을 많이 능가합니다.
- 옴니모달 성능 이점: 비슷한 크기의 단봉형 모델과 비교했을 때 뛰어난 성능을 보여줍니다. Qwen2.5-Omni는 오디오 성능 면에서 비슷한 크기의 Qwen2-Audio보다 성능이 뛰어나며 Qwen2.5-VL-7B와 동등합니다.
- 탁월한 엔드투엔드 음성 명령 수행 기능: Qwen2.5-Omni는 종단간 음성 명령 수행에서 텍스트 입력 처리와 비슷한 결과를 보여주며, MMLU 일반 지식 이해 및 GSM8K 수학적 추론과 같은 벤치마크에서 탁월한 성과를 보입니다.
이 튜토리얼에서는 데모로 Qwen2.5-Omni를 사용하며, 컴퓨팅 리소스는 A6000입니다.
지원되는 기능:
- 온라인 다중 모드 대화
- 오프라인 멀티모달 대화
2. 작업 단계
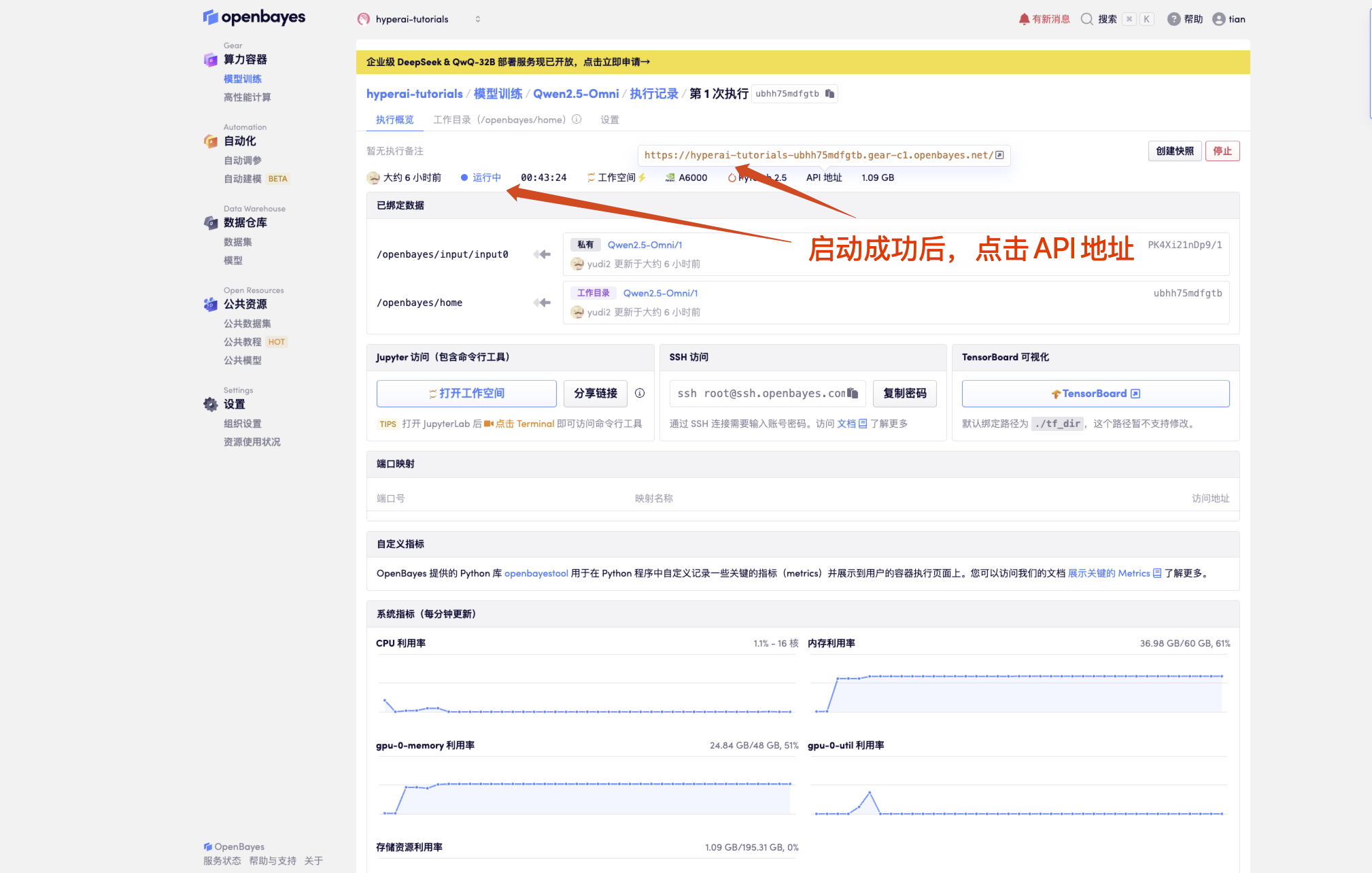
1. 컨테이너 시작 후 API 주소를 클릭하여 웹 인터페이스로 진입합니다.
"모델"이 표시되지 않으면 모델이 초기화되고 있음을 의미합니다. 모델이 크기 때문에 1~2분 정도 기다리신 후 페이지를 새로고침해 주세요.
2. 웹페이지에 접속 후 모델과 대화를 시작할 수 있습니다.
입력 상자가 주황색이면 모델이 응답하고 있다는 의미입니다.
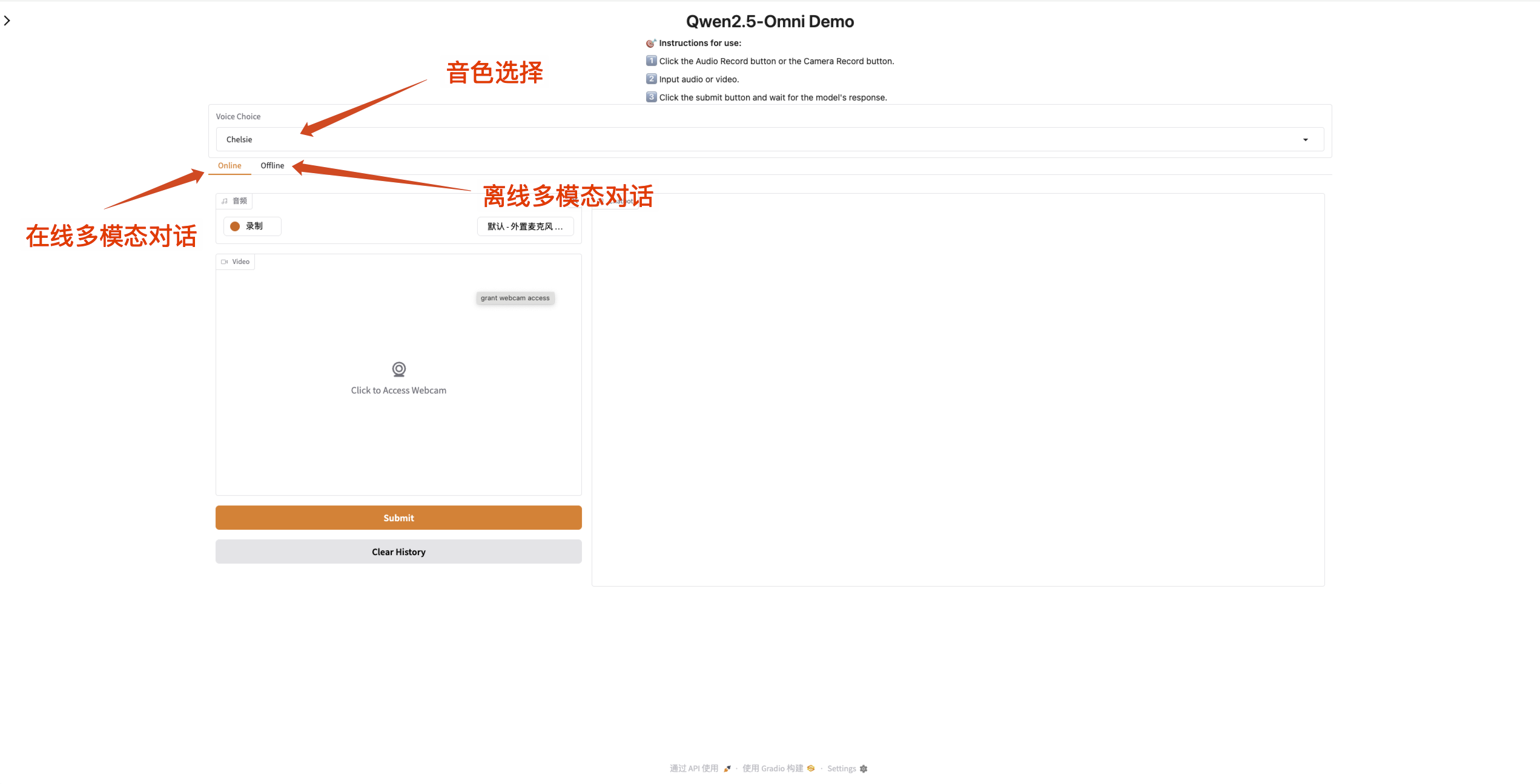
Qwen2.5-Omni는 출력 오디오의 사운드 변경을 지원합니다. "Qwen/Qwen2.5-Omni-7B" 체크포인트는 다음 두 가지 사운드 유형을 지원합니다.
| 톤 유형 | 성별 | 설명하다 |
|---|---|---|
| 첼시 | 여성 | 달콤하고, 부드럽고, 밝고, 부드럽습니다 |
| 이선 | 남성 | 햇살, 활력, 가벼움, 친화력 |
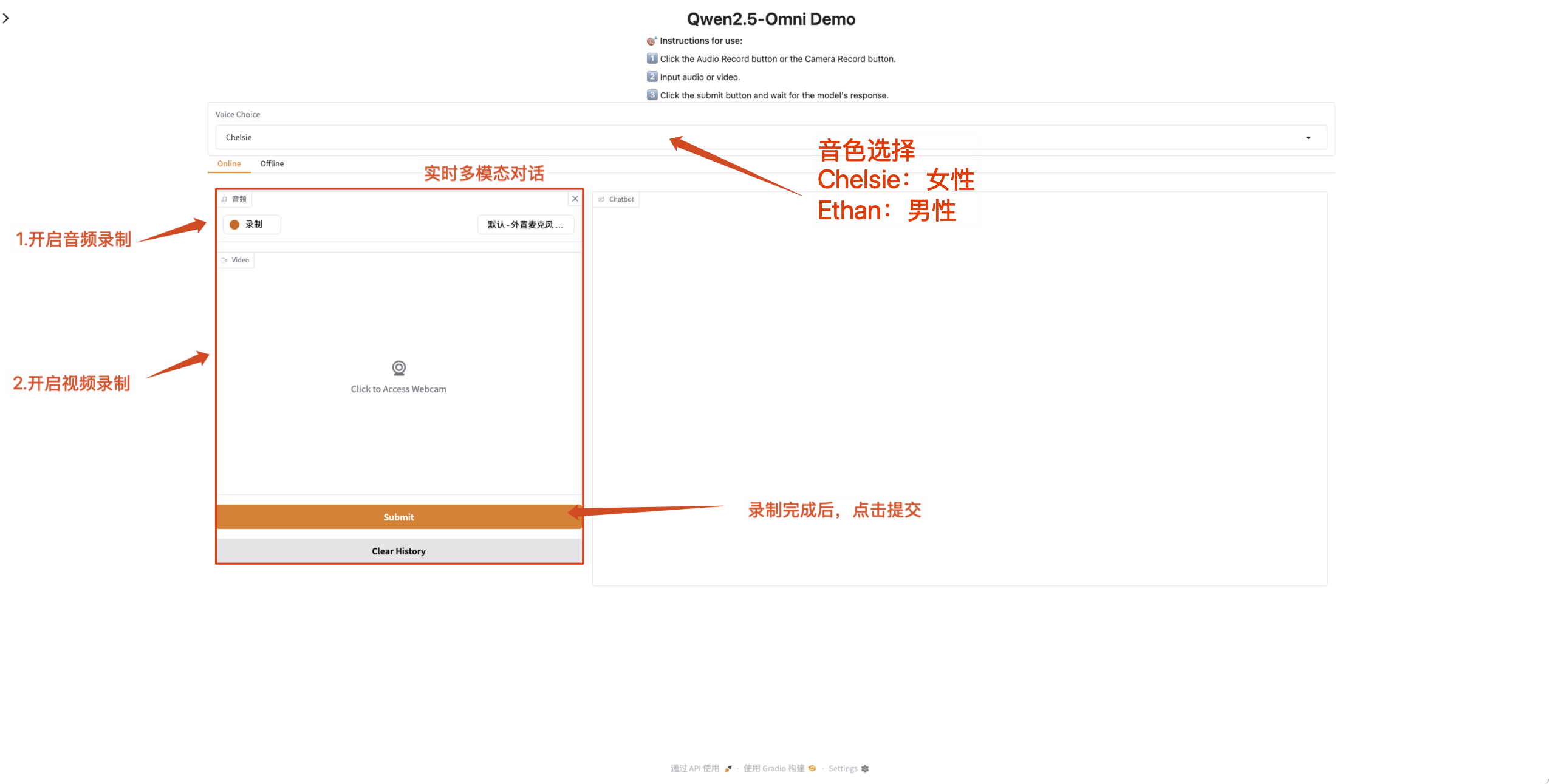
- 온라인 다중 모드 대화
녹화가 완료된 후 Qwen2.5-Omni와 실시간으로 대화할 수 있도록 웹 페이지에서 마이크와 카메라 권한을 활성화하세요.
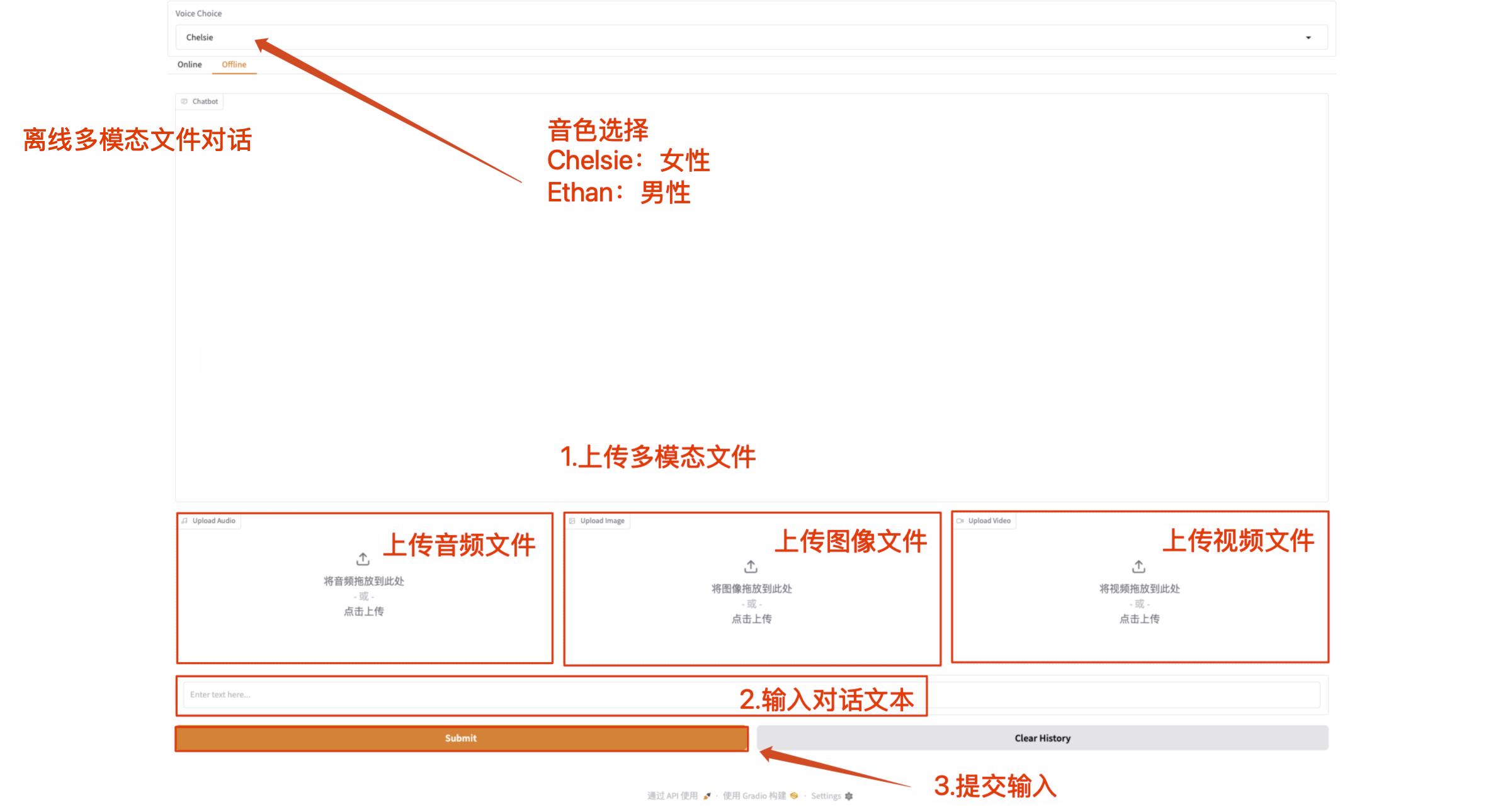
- 오프라인 멀티모달 대화
멀티모달 파일을 직접 업로드하고 텍스트 콘텐츠로 Qwen2.5-Omni와 통신하세요.
참고: 비디오 파일에는 사운드가 있어야 합니다. 소리가 나지 않으면 오류 메시지가 표시됩니다.
교류 및 토론
🖌️ 고품질 프로젝트를 발견하시면, 백그라운드에 메시지를 남겨 추천해주세요! 또한, 튜토리얼 교환 그룹도 만들었습니다. 친구들의 QR코드 스캔과 [SD 튜토리얼] 댓글을 통해 그룹에 가입하여 다양한 기술 이슈에 대해 논의하고 신청 결과를 공유해 주시기 바랍니다.↓ 