Command Palette
Search for a command to run...
vLLM을 사용하여 QwQ-32B 배포

1. 튜토리얼 소개
QwQ는 Qwen 급수의 추론 모델입니다. 기존의 명령어 튜닝 모델과 비교했을 때, QwQ는 사고 및 추론 능력을 갖추고 있으며, 특히 어려운 문제를 다루는 다운스트림 작업에서 상당한 성능 향상을 이룰 수 있습니다. QwQ-32B는 DeepSeek-R1, o1-mini 등 최첨단 추론 모델과 경쟁할 만한 성능을 달성할 수 있는 중형 추론 모델입니다.
이 튜토리얼에서는 데모로 QwQ-32B를 사용하며, 컴퓨팅 리소스는 A6000*2입니다.
2. 작업 단계
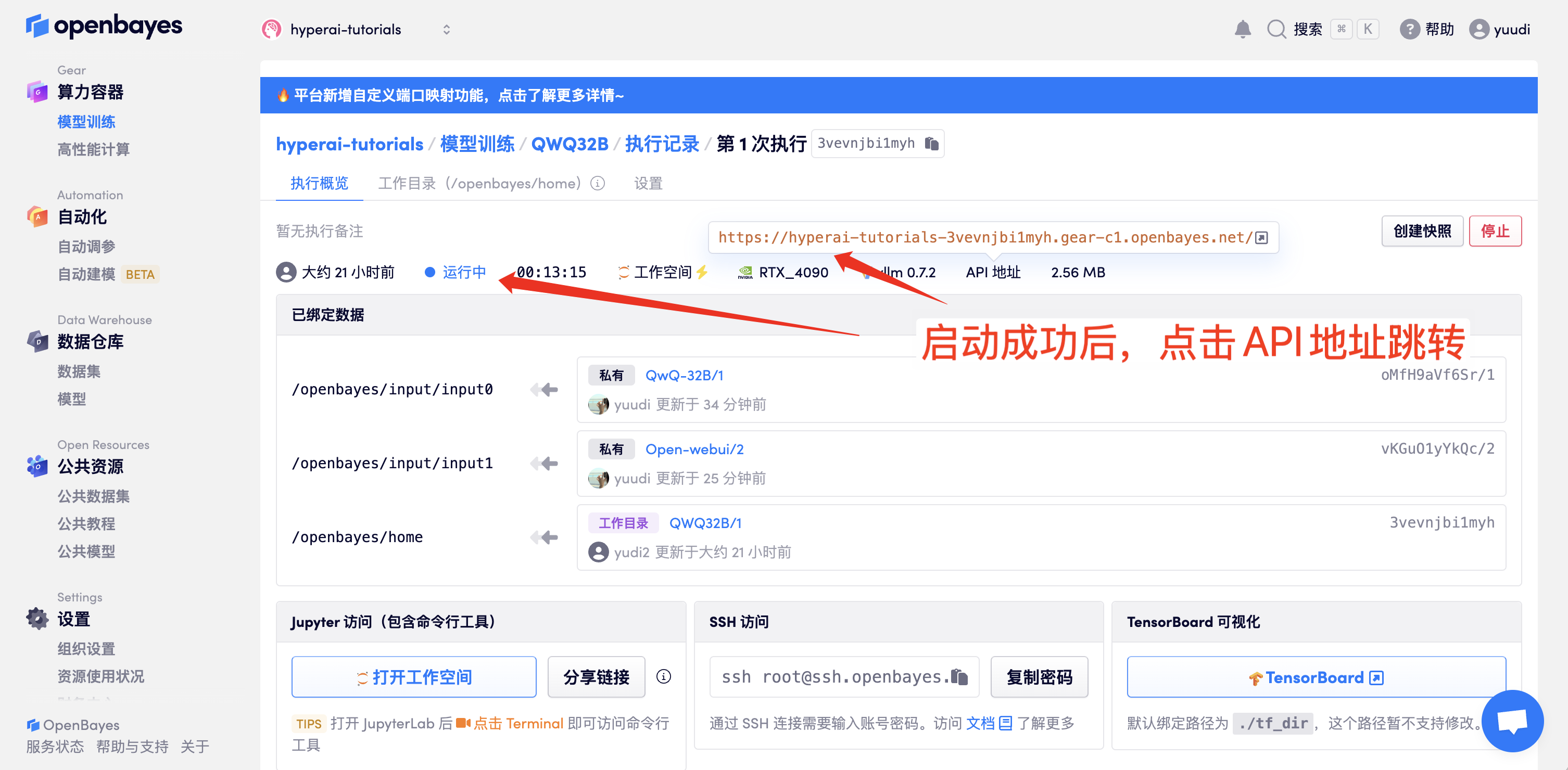
1. 컨테이너를 시작한 후 API 주소를 클릭하여 웹 인터페이스에 접속합니다. ("모델"이 표시되지 않으면 모델이 초기화 중임을 의미합니다. 모델이 용량이 크므로 1~2분 정도 기다린 후 페이지를 새로고침해 주세요.)
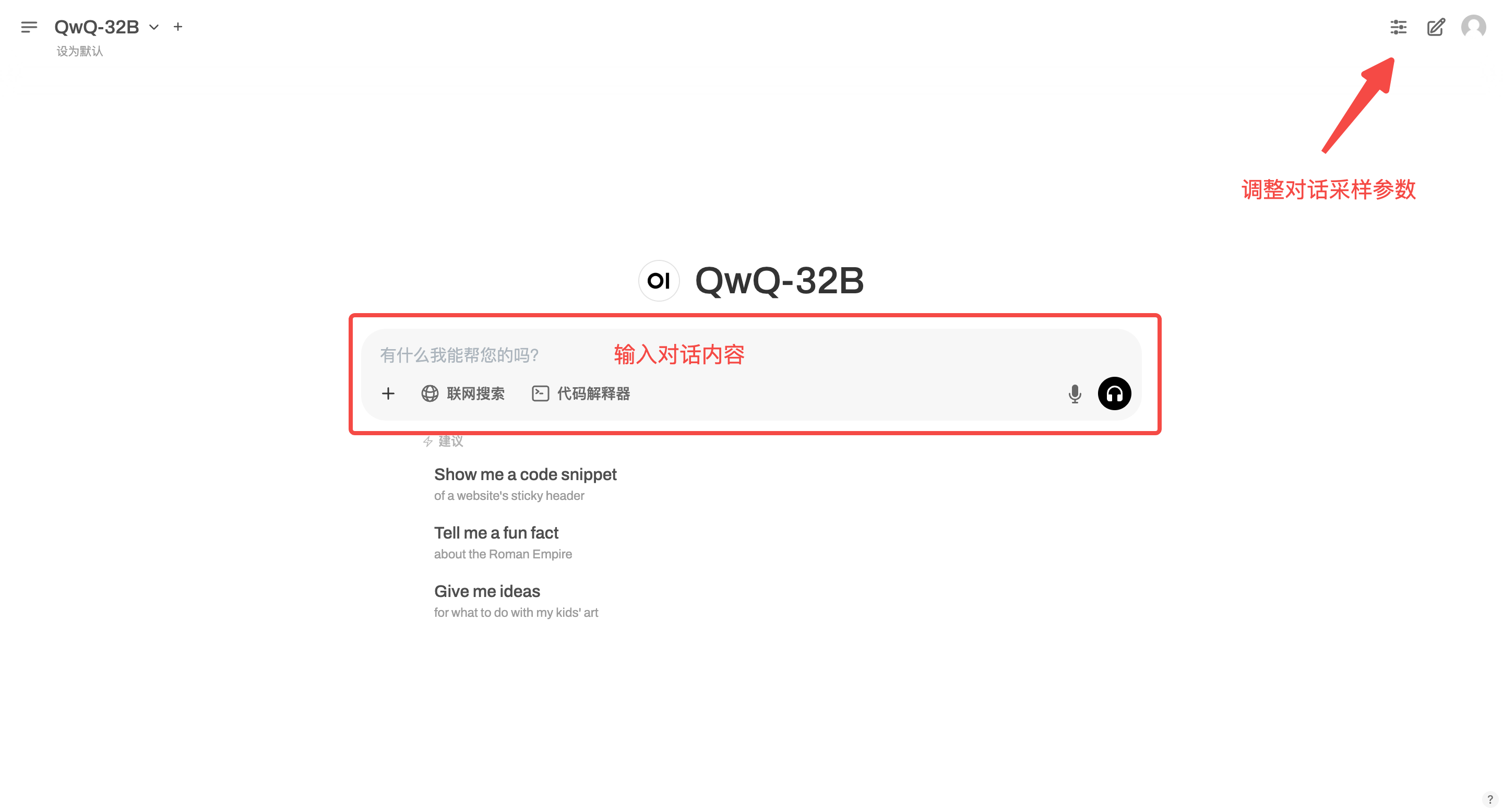
2. 웹페이지에 접속 후 모델과 대화를 시작할 수 있습니다.
이 튜토리얼은 "온라인 검색"을 지원합니다. 이 기능을 켜면 추론 속도가 느려지는데, 이는 정상적인 현상입니다.
교류 및 토론
🖌️ 고품질 프로젝트를 발견하시면, 백그라운드에 메시지를 남겨 추천해주세요! 또한, 튜토리얼 교환 그룹도 만들었습니다. 친구들의 QR코드 스캔과 [SD 튜토리얼] 댓글을 통해 그룹에 가입하여 다양한 기술 이슈에 대해 논의하고 신청 결과를 공유해 주시기 바랍니다.↓ 