Command Palette
Search for a command to run...
Ollama 및 Open WebUI를 사용하여 DeepSeek R1 배포
1. 튜토리얼 소개
DeepSeek-R1은 DeepSeek이 2025년에 출시한 언어 모델 시리즈의 첫 번째 버전으로, 효율적이고 가벼운 자연어 처리 작업에 중점을 두고 있습니다. 이 모델 계열은 지식 증류와 같은 고급 기술을 통해 최적화되어 컴퓨팅 리소스 요구 사항을 줄이는 동시에 높은 성능을 유지하는 것을 목표로 합니다. DeepSeek-R1은 실제 적용 시나리오에 초점을 맞춰 설계되었으며, 빠른 배포와 통합을 지원하고, 텍스트 생성, 대화 시스템, 번역, 요약 생성을 포함한 다양한 작업에 적합합니다.
기술적인 측면에서 DeepSeek-R1은 지식 증류 기술을 사용하여 대규모 모델에서 지식을 추출하여 유사한 성능을 내는 소규모 모델을 훈련합니다. 동시에 효율적인 분산 학습 및 최적화 알고리즘을 통해 학습 시간이 더욱 단축되고 모델 개발의 효율성이 향상됩니다. 이러한 기술적 하이라이트 덕분에 DeepSeek-R1은 실제 응용 분야에서 우수한 성능을 발휘합니다.
本教程预设 DeepSeek-R1-Distill-Qwen-1.5B 、 DeepSeek-R1-Distill-Qwen-7B 、 DeepSeek-R1-Distill-Qwen-8B 、 DeepSeek-R1-Distill-Qwen-32B 四种模型作为演示,算力资源采用「单卡 RTX4090」。
2. 작업 단계
- 컨테이너를 복제하고 시작한 후 API 주소를 클릭하여 웹 인터페이스로 들어갑니다("잘못된 게이트웨이"가 표시되면 모델이 초기화 중임을 의미합니다. 모델이 크기 때문에 약 5분 정도 기다린 후 다시 시도하세요).
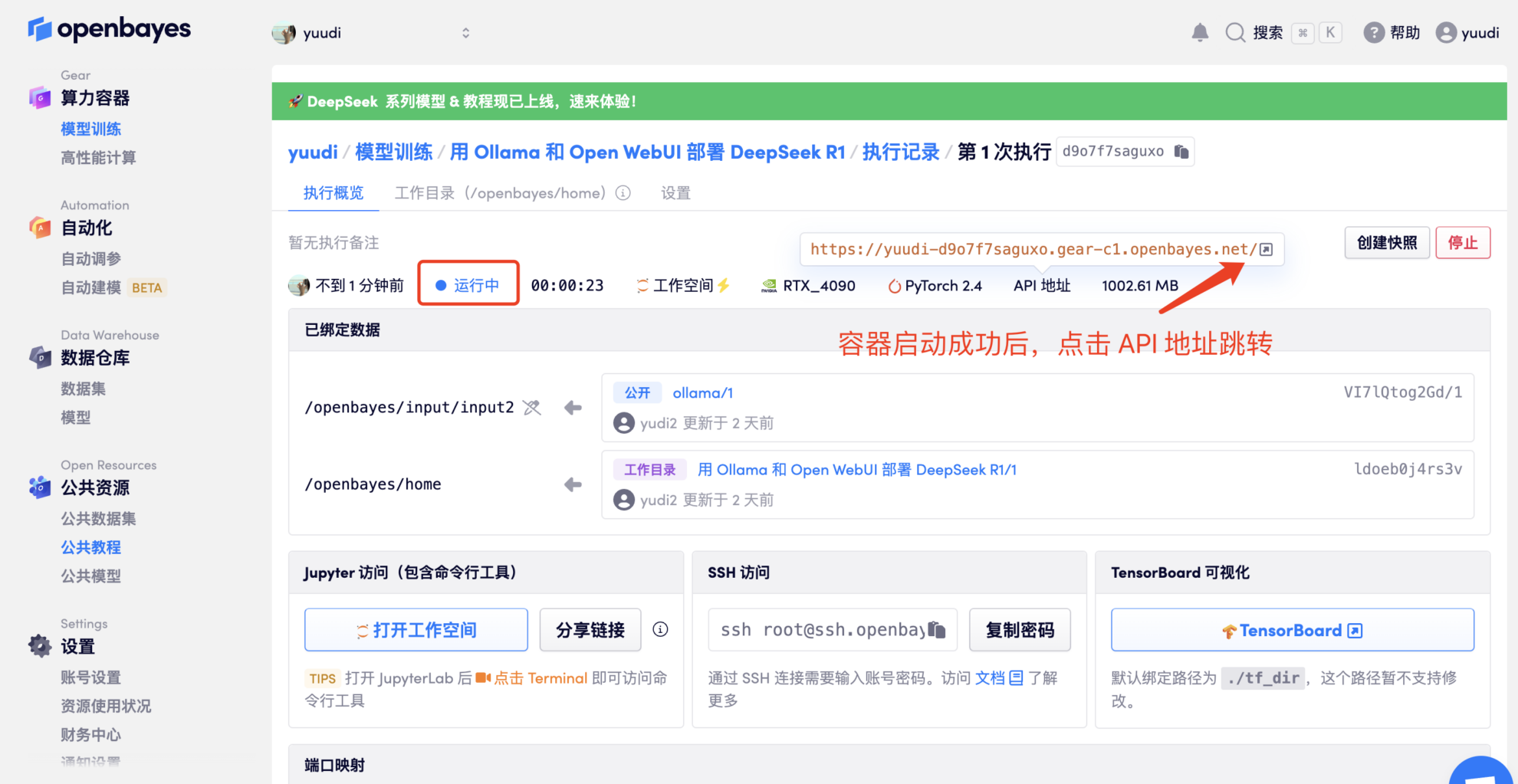
2. 웹페이지에 접속 후 모델과 대화를 시작할 수 있습니다.
알아채다:
- 이 튜토리얼은 "온라인 검색"을 지원합니다. 이 기능을 켜면 추론 속도가 느려지는데, 이는 정상적인 현상입니다.
- 인터페이스의 왼쪽 상단에서 모델을 전환할 수 있습니다.
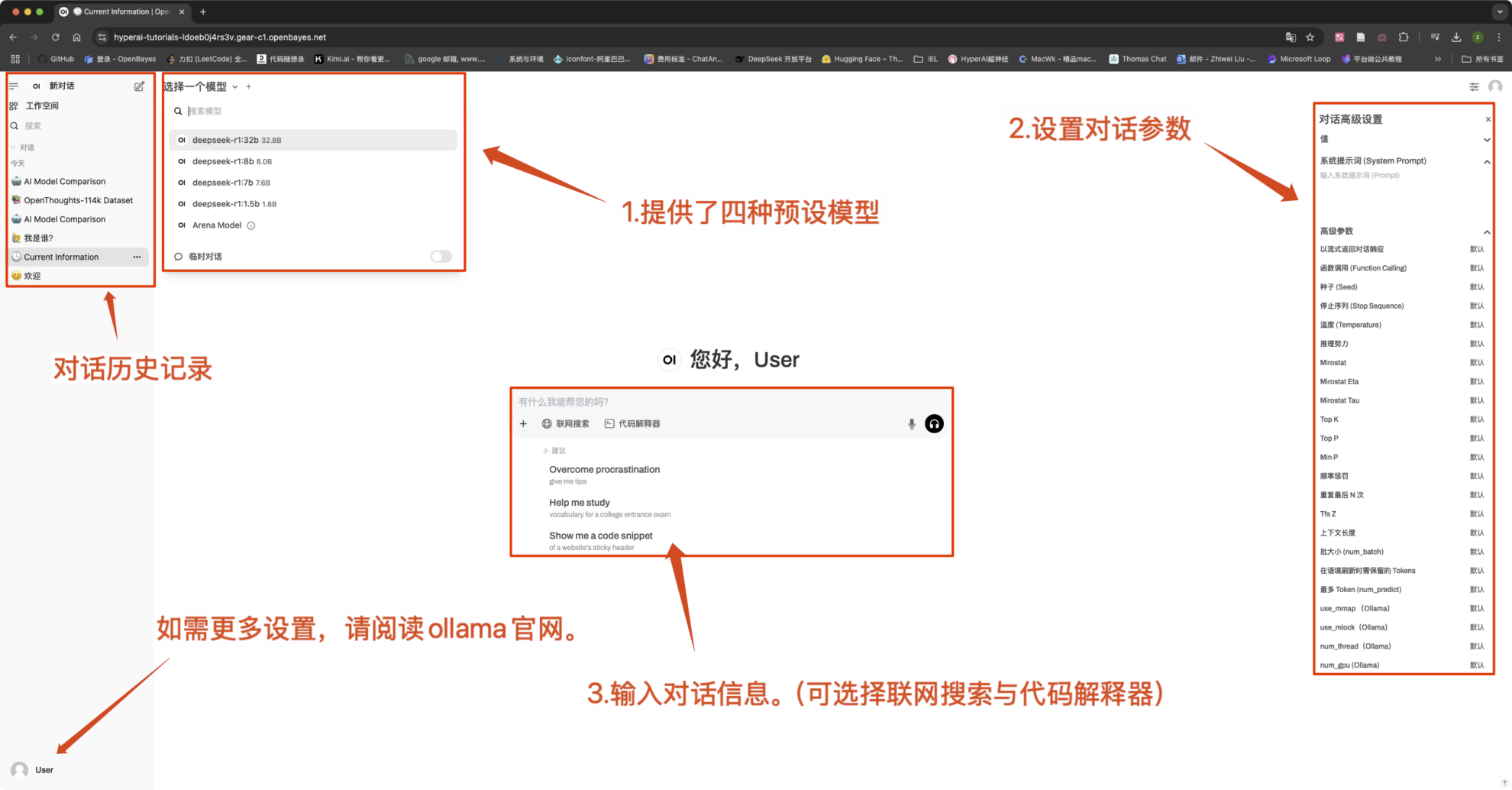
일반적인 대화 설정
1. 온도
- 일반적으로 다음 범위 내에서 출력의 무작위성을 제어합니다. 0.0-2.0 사이.
- 낮은 값(예: 0.1): 더 확실하고, 흔한 단어에 편향되어 있습니다.
- 높은 값(예: 1.5): 더 무작위적이고 잠재적으로 더 창의적이지만 불규칙한 콘텐츠입니다.
2. Top-k 샘플링
- 오직에서 가장 높은 확률을 갖는 k 확률이 낮은 단어를 제외하고 단어 단위로 샘플링합니다.
- k는 작습니다(예: 10): 확실성은 더 크고 무작위성은 더 적습니다.
- k가 큽니다(예: 50): 다양성이 더 커지고 혁신도 더 커집니다.
3. Top-p 샘플링(핵 샘플링, Top-p 샘플링)
- 선택하다누적 확률이 p에 도달하는 단어 집합, k 값은 고정되어 있지 않습니다.
- 낮은 값(예: 0.3): 확실성은 더 크고 무작위성은 더 적습니다.
- 높은 값(예: 0.9): 다양성이 높아지고 유창성이 향상되었습니다.
4. 반복 페널티
- 일반적으로 텍스트 반복을 제어합니다. 1.0-2.0 사이.
- 높은 값(예: 1.5): 반복을 줄이고 가독성을 향상시킵니다.
- 낮은 값(예: 1.0): 페널티는 없지만, 모델이 단어와 문장을 반복할 수 있습니다.
5. 최대 토큰(최대 생성 길이)
- 제한 모델생성된 최대 토큰 수, 지나치게 긴 출력을 피하세요.
- 일반적인 범위:50-4096(특정 모델에 따라 다름).
교류 및 토론
🖌️ 고품질 프로젝트를 발견하시면, 백그라운드에 메시지를 남겨 추천해주세요! 또한, 튜토리얼 교환 그룹도 만들었습니다. 친구들의 QR코드 스캔과 [SD 튜토리얼] 댓글을 통해 그룹에 가입하여 다양한 기술 이슈에 대해 논의하고 신청 결과를 공유해 주시기 바랍니다.↓
