Command Palette
Search for a command to run...
vLLM 시작하기 튜토리얼: 초보자를 위한 단계별 가이드
vLLM 중국어 문서에 접근하세요:https://vllm.hyper.ai/


목차
1. 튜토리얼 소개
vLLM(Virtual Large Language Model)은 대규모 언어 모델의 추론을 가속화하기 위해 특별히 설계된 프레임워크입니다. 뛰어난 추론 효율성과 자원 최적화 능력으로 인해 전 세계적으로 폭넓은 주목을 받고 있습니다. 2023년, 캘리포니아 대학교 버클리(UC 버클리) 연구팀은 주의 키와 값을 효과적으로 관리할 수 있는 획기적인 주의 알고리즘인 PagedAttention을 제안했습니다. 이를 바탕으로 연구진은 고처리량 분산 LLM 서비스 엔진인 vLLM을 구축하여 KV 캐시 메모리 낭비를 거의 없애고, 대규모 언어 모델 추론에서 발생하는 메모리 관리 병목 현상을 해결했습니다. Hugging Face Transformers와 비교했을 때 처리량이 24배 더 높으며, 이러한 성능 향상을 위해 모델 아키텍처를 변경할 필요가 없습니다. 관련 논문 결과는 다음과 같습니다.PagedAttention을 사용한 대규모 언어 모델 제공을 위한 효율적인 메모리 관리".
이 튜토리얼에서는 vLLM을 구성하고 실행하는 방법을 단계별로 보여주고, 설치부터 시작까지 완벽한 시작 가이드를 제공합니다.
이 튜토리얼에서는 다음을 사용합니다. Qwen3-0.6B 시연을 위해 다른 매개변수 수량을 포함하는 모델도 제공됩니다.
2. vLLM 설치
이 플랫폼은 완성되었습니다 vllm==0.8.5 설치. 플랫폼에서 운영하는 경우 이 단계를 건너뛰세요. 로컬로 배포하는 경우 아래 단계에 따라 설치하세요.
vLLM 설치는 매우 간단합니다.
pip install vllmvLLM은 CUDA 12.4로 컴파일되었으므로 컴퓨터에서 해당 버전의 CUDA가 실행되고 있는지 확인해야 합니다.
CUDA 버전을 확인하려면 다음을 실행하세요.
nvcc --versionCUDA 버전이 12.4가 아닌 경우 현재 CUDA 버전과 호환되는 vLLM 버전을 설치하거나(자세한 내용은 설치 지침 참조) CUDA 12.4를 설치할 수 있습니다.
3. 사용을 시작하세요
3.1 모델 준비
방법 1: 플랫폼 공개 모델 사용
첫째, 플랫폼의 공개 모델이 이미 존재하는지 확인할 수 있습니다. 모델이 공개 저장소에 업로드된 경우 바로 사용할 수 있습니다. 찾을 수 없는 경우 방법 2를 참고하여 다운로드하세요.
예를 들어, 플랫폼은 다음을 저장했습니다. Qwen3 시리즈 모델. 모델을 바인딩하는 단계는 다음과 같습니다(이 모델은 이 튜토리얼에서 이미 바인딩되어 있습니다).
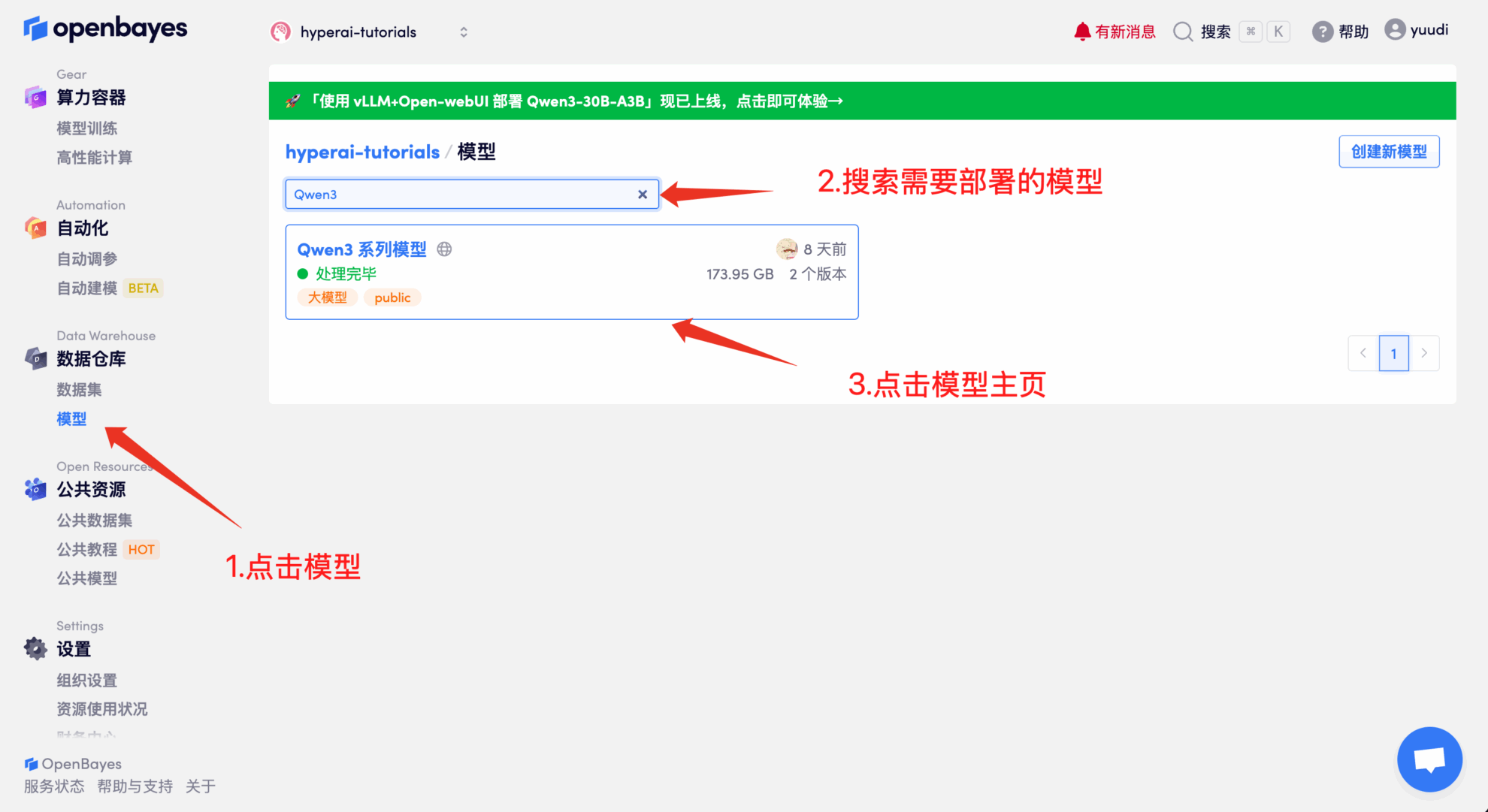
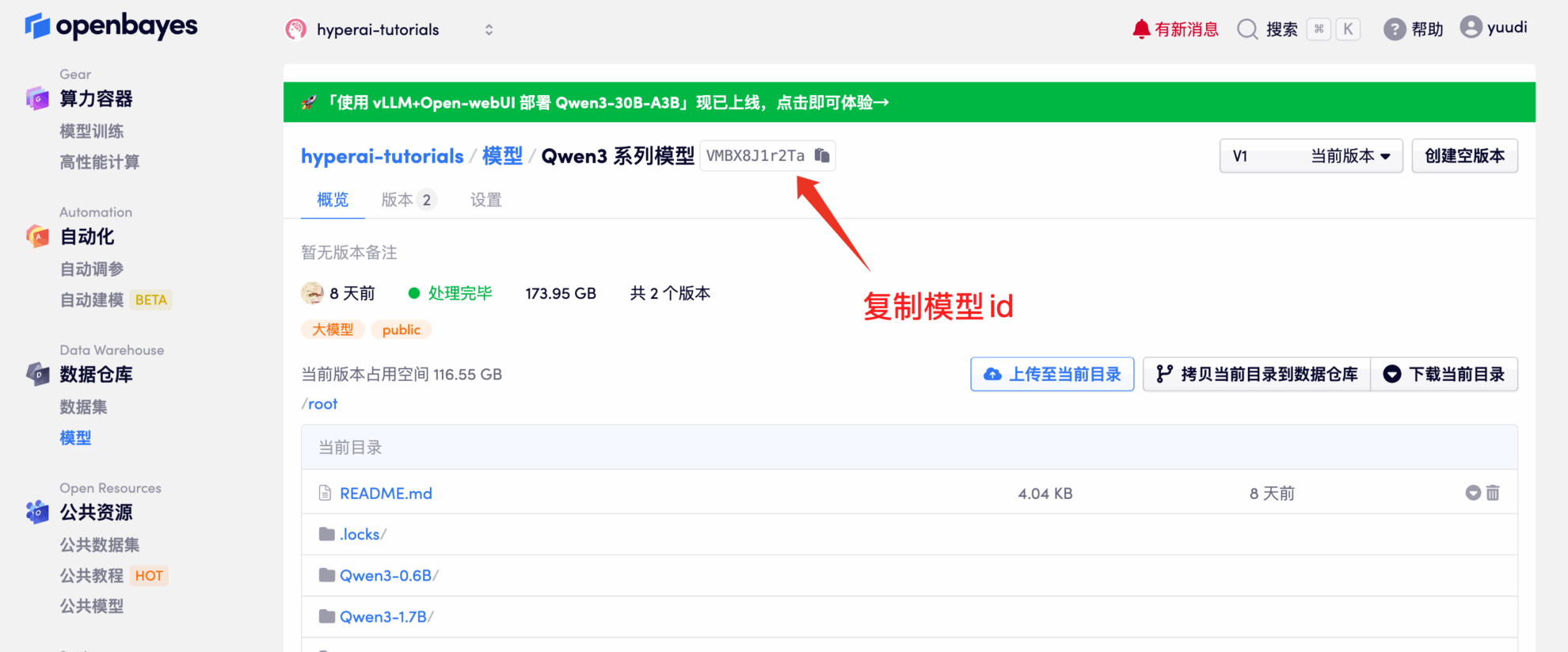
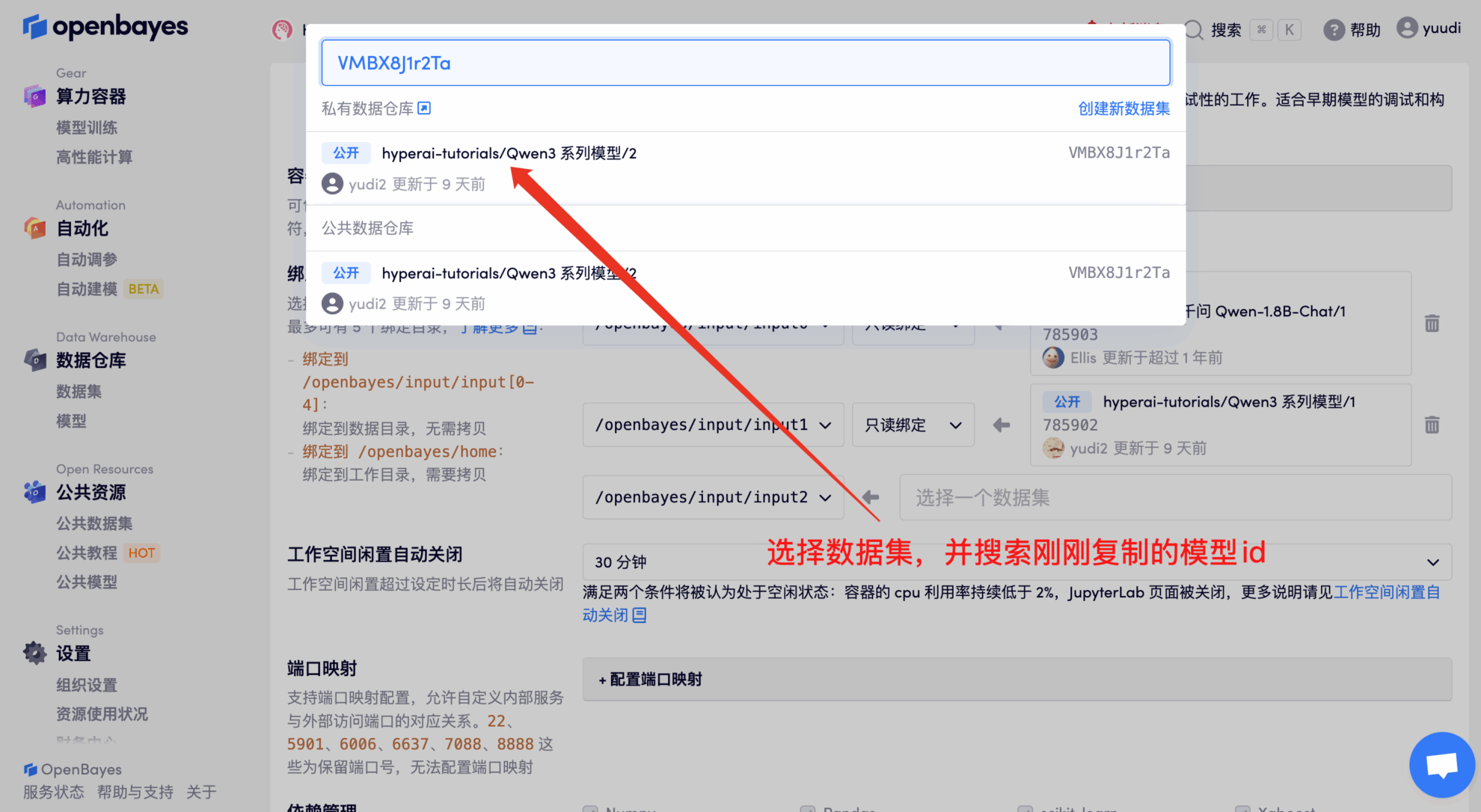
방법 2: HuggingFace에서 다운로드하거나 고객 서비스에 문의하여 플랫폼에 업로드하는 데 도움을 받으세요.
대부분의 대중적인 모델은 HuggingFace에서 찾아볼 수 있습니다. vLLM에서 지원하는 모델 목록은 공식 문서를 참조하세요. vllm 지원 모델 .
huggingface-cli를 사용하여 모델을 다운로드하려면 아래 단계를 따르세요.
huggingface-cli download --resume-download Qwen/Qwen3-0.6B --local-dir ./input03.2 오프라인 추론
오픈 소스 프로젝트인 vLLM은 Python API를 통해 LLM 추론을 수행할 수 있습니다. 다음은 간단한 예입니다. 코드를 다음과 같이 저장해 주세요. offline_infer.py 문서:
from vllm import LLM, SamplingParams
# 输入几个问题
prompts = [
"你好,你是谁?",
"法国的首都在哪里?",
]
# 设置初始化采样参数
sampling_params = SamplingParams(temperature=0.8, top_p=0.95, max_tokens=100)
# 加载模型,确保路径正确
llm = LLM(model="/input1/Qwen3-0.6B/", trust_remote_code=True, max_model_len=4096)
# 展示输出结果
outputs = llm.generate(prompts, sampling_params)
# 打印输出结果
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
그런 다음 스크립트를 실행합니다.
python offline_infer.py모델이 로드되면 다음과 같은 출력이 표시됩니다.

4. vLLM 서버를 시작합니다.
vLLM을 사용하여 온라인 서비스를 제공하려면 OpenAI API와 호환되는 서버를 시작할 수 있습니다. 성공적으로 출시한 후에는 GPT와 마찬가지로 배포된 모델을 사용할 수 있습니다.
4.1 주요 매개변수 설정
vLLM 서버를 시작할 때 일반적으로 사용되는 매개변수는 다음과 같습니다.
--model: HuggingFace 모델 이름 또는 사용할 경로(기본값:facebook/opt-125m).--host그리고--port: 서버 주소와 포트를 지정하세요.--dtype: 모델 가중치와 활성화의 정밀도 유형입니다. 가능한 값:auto,half,float16,bfloat16,float,float32. 기본값:auto.--tokenizer: HuggingFace 토크나이저 이름 또는 사용할 경로입니다. 지정하지 않으면 기본적으로 모델 이름이나 경로가 사용됩니다.--max-num-seqs: 반복당 최대 시퀀스 수.--max-model-len: 모델의 컨텍스트 길이. 기본값은 모델 구성에서 자동으로 얻어집니다.--tensor-parallel-size,-tp: 텐서의 병렬 복사본 수(GPU용). 기본값:1.--distributed-executor-backend=ray: 분산 서비스의 백엔드를 지정합니다. 가능한 값:ray,mp. 기본값:ray(GPU를 두 개 이상 사용하는 경우 자동으로 설정됩니다.ray).
4.2 명령줄 시작
OpenAI API 인터페이스와 호환되는 서버를 만듭니다. 다음 명령을 실행하여 서버를 시작합니다.
python3 -m vllm.entrypoints.openai.api_server --model /input1/Qwen3-0.6B/ --host 0.0.0.0 --port 8080 --dtype auto --max-num-seqs 32 --max-model-len 4096 --tensor-parallel-size 1 --trust-remote-code성공적으로 시작하면 다음과 비슷한 출력이 표시됩니다.

vLLM은 이제 OpenAI API 프로토콜을 구현하는 서버로 배포될 수 있으며 기본적으로 다음에서 사용할 수 있습니다. http://localhost:8080 서버를 시작합니다. 당신은 할 수 있습니다 --host 그리고 --port 매개변수가 다른 주소를 지정합니다.
5. 요청하기
이 튜토리얼에서 시작하는 API 주소는 다음과 같습니다. http://localhost:8080, 이 주소를 방문하시면 API를 이용하실 수 있습니다. localhost 플랫폼 자체를 말합니다.8080 API 서비스가 수신하는 포트 번호입니다.
작업 공간 오른쪽에서는 API 주소가 로컬 8080 서비스로 전달되고, 다음 그림과 같이 실제 호스트를 통해 요청이 이루어질 수 있습니다.

5.1 OpenAI 클라이언트 사용
4단계에서 vLLM 서비스를 시작한 후 OpenAI 클라이언트를 통해 API를 호출할 수 있습니다. 간단한 예를 들어보겠습니다.
# 注意:请先安装 openai
# pip install openai
from openai import OpenAI
# 设置 OpenAI API 密钥和 API 基础地址
openai_api_key = "EMPTY" # 请替换为您的 API 密钥
openai_api_base = "http://localhost:8080/v1" # 本地服务地址
client = OpenAI(api_key=openai_api_key, base_url=openai_api_base)
models = client.models.list()
model = models.data[0].id
prompt = "描述一下北京的秋天"
# Completion API 调用
completion
= client.completions.create(model=model, prompt=prompt)
res = completion.choices[0].text.strip()
print(f"Prompt: {prompt}\nResponse: {res}")다음 명령을 실행합니다:
python api_infer.py다음과 유사한 출력이 표시됩니다.

5.2 Curl 명령 요청 사용
다음 명령을 사용하여 요청을 직접 보낼 수도 있습니다. 플랫폼에 접속할 때 다음 명령을 입력하세요.
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/input1/Qwen3-0.6B/",
"prompt": "描述一下北京的秋天",
"max_tokens": 512
}'다음과 같은 응답을 받게 됩니다.

OpenBayes 플랫폼을 사용하는 경우 다음 명령을 입력하세요.
curl https://hyperai-tutorials-8tozg9y9ref9.gear-c1.openbayes.net/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/input1/Qwen3-0.6B/",
"prompt": "描述一下北京的秋天",
"max_tokens": 128
}'응답 결과는 다음과 같습니다.
