위스퍼-라지-V3-터보 음성 인식 및 번역 데모

1. 튜토리얼 소개
위스퍼는 범용 음성 인식 모델이다. 대규모의 다양한 오디오 데이터 세트에 대해 학습되었으며 다음을 수행할 수 있습니다.다국어 음성 인식, 음성 번역 등의 멀티태스킹.
- 다국어 음성 인식: 오디오에서 언어를 자동으로 식별하고 출력을 위해 원래 언어로 변환합니다.
- 언어 번역: 인식을 기반으로 언어를 중국어(기본값)로 번역하여 출력합니다.
OpenAI는 2024년 10월 1일에 개최된 DevDay 이벤트에서 품질 저하가 거의 없는 총 8억 900만 개의 매개변수를 갖춘 Whisper 대형 v3 터보 음성 전사 모델 출시를 발표했습니다.대형 v3보다 8배 빠름
Whisper large-v3-turbo 음성 전사 모델은 large-v3의 최적화된 버전으로, 32개의 레이어를 가진 large-v3와 달리 디코더 레이어가 4개만 있습니다. 모델 총계 8억 900만 개의 매개변수7억 6,900만 개의 매개변수를 가진 중형 모델보다 약간 크지만, 15억 5,000만 개의 매개변수를 가진 대형 모델보다 훨씬 작습니다.필요한 VRAM은 6GB이고, 대형 모델에는 10GB가 필요합니다.
2. 작업 단계
컨테이너를 시작한 후 API 주소를 클릭하여 웹 인터페이스로 들어갑니다.
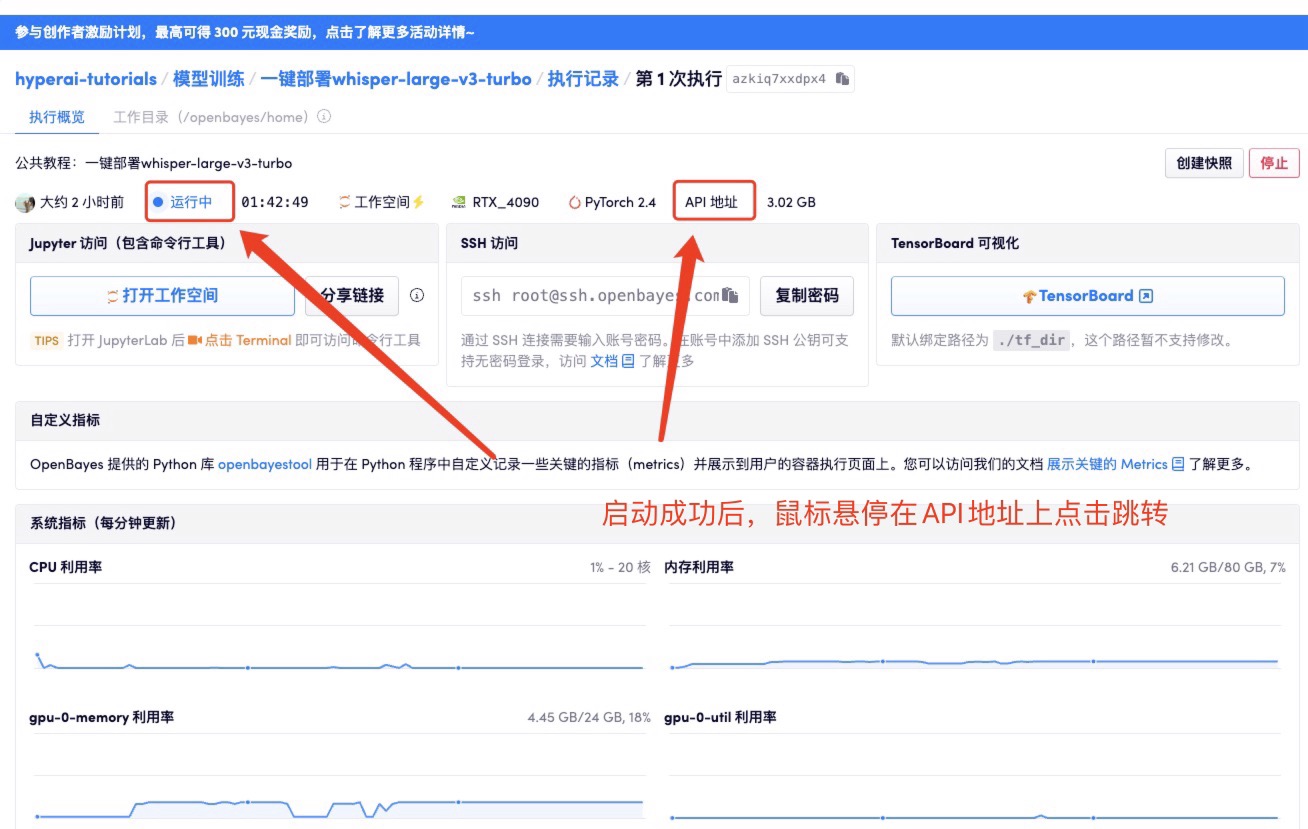
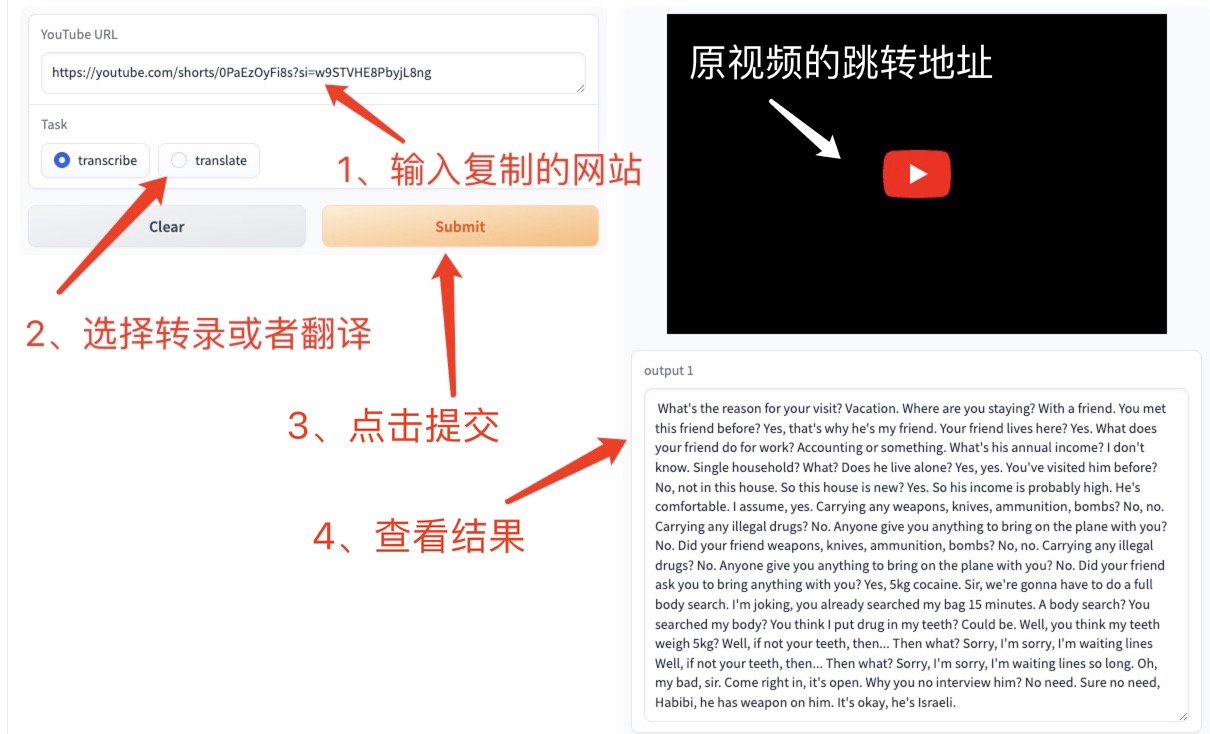
우리는 음성 인식(전사) 또는 번역(번역)을 위한 세 가지 기능을 제공합니다.
- 마이크 장치를 직접 사용하여 실시간 녹음
- 오디오 파일 오프라인 오디오 업로드
- YouTube 온라인 비디오
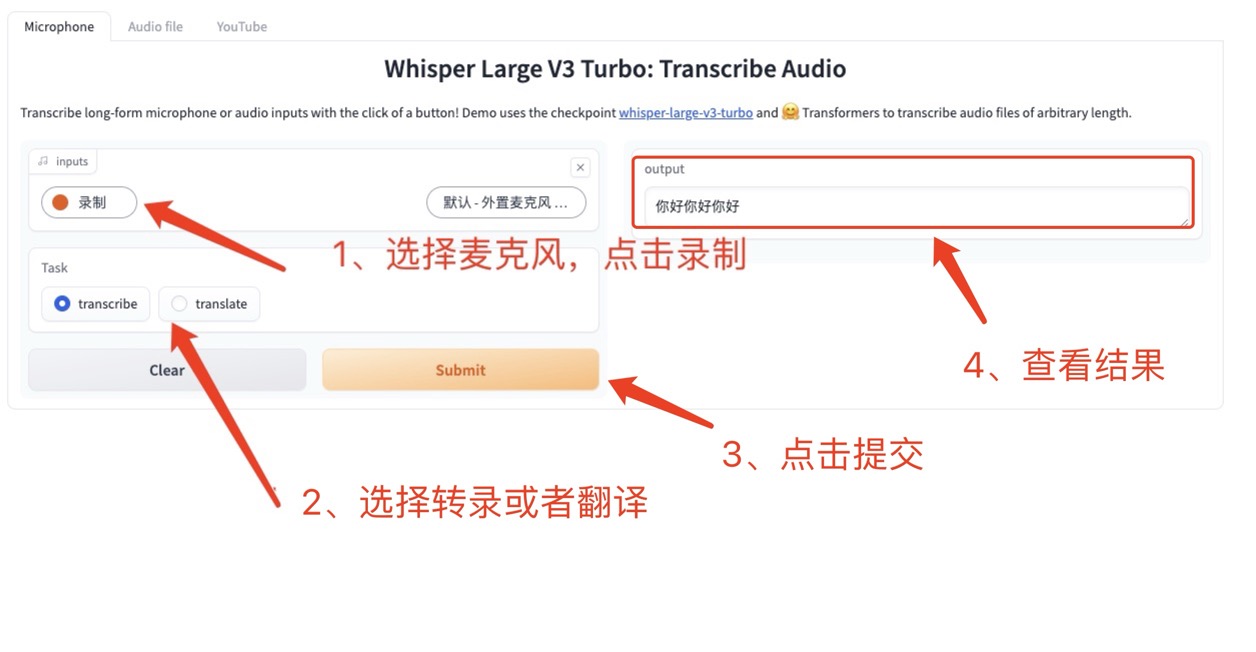
1. 마이크는 실시간 녹음을 위해 장치를 직접 사용합니다.
딸깍 하는 소리 마이크(기본값), 장치 마이크를 사용하여 오디오를 녹음합니다. 녹음 후 오디오가 플랫폼에 업로드되고, 필사본이나 번역본을 선택한 후 제출을 클릭하면 지정된 텍스트가 생성됩니다. (모델 성능상의 이유로 번역이 부정확할 수 있습니다)
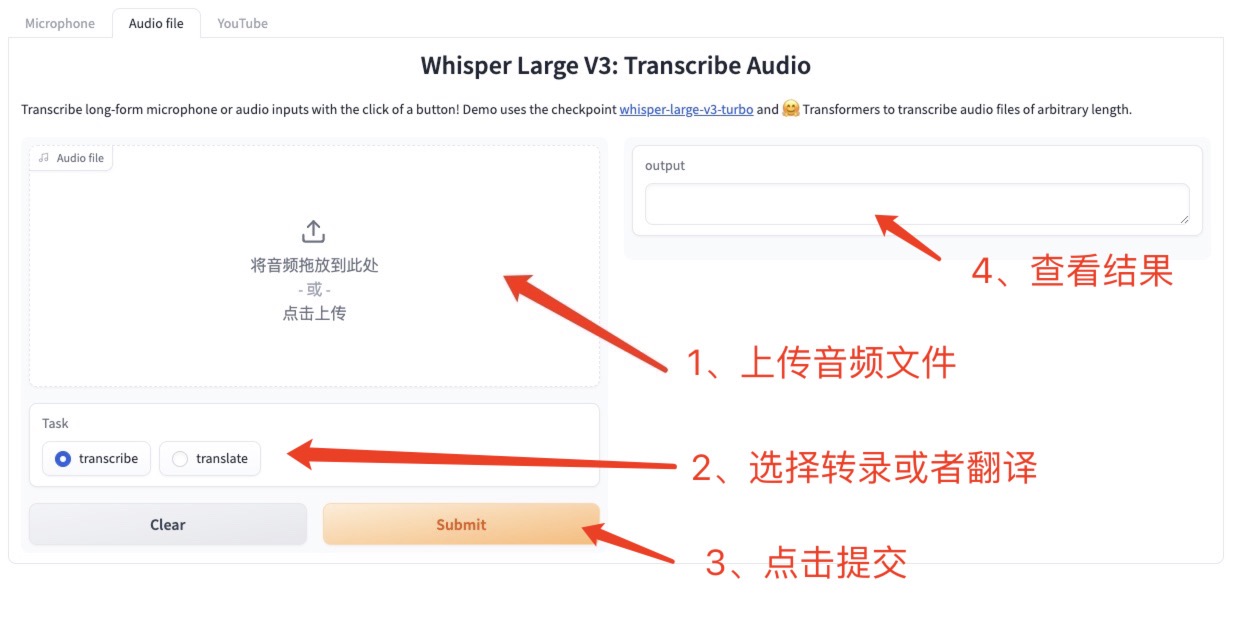
2. 오디오 파일 업로드 오프라인 오디오
딸깍 하는 소리 오디오 파일, 실행할 오디오를 인터페이스에 업로드하거나 끌어다 놓고, 필사본이나 번역본을 선택한 다음, 제출을 클릭하면 지정된 텍스트가 생성됩니다.
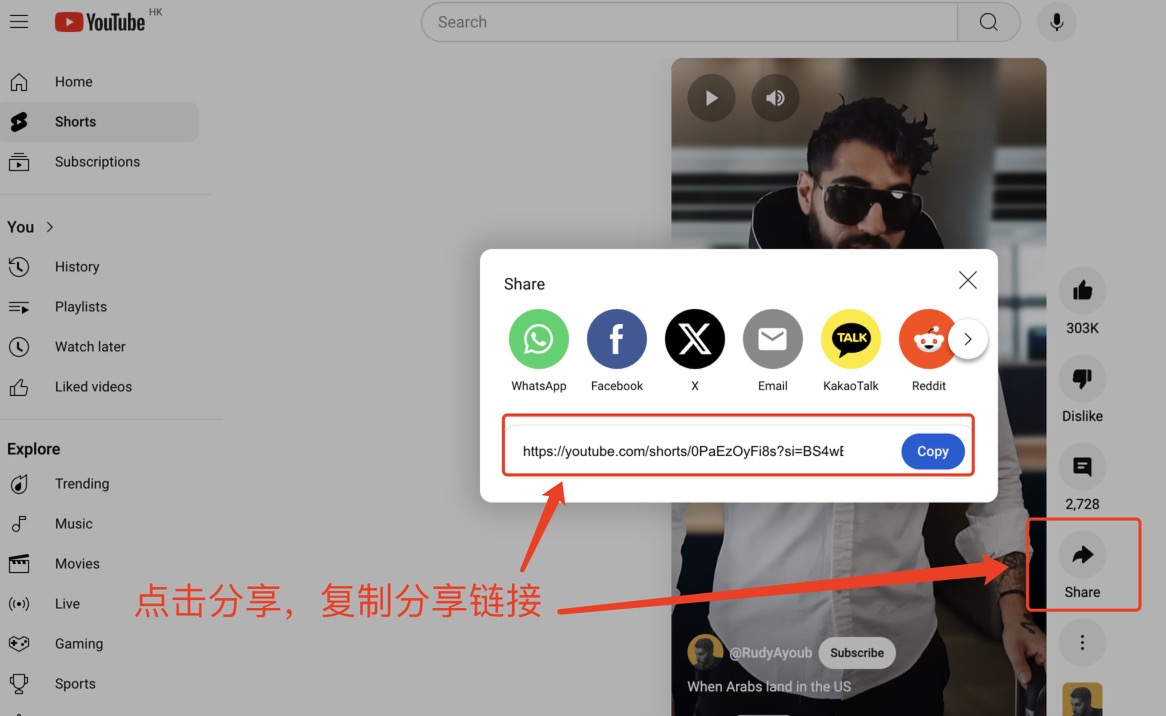
3. 유튜브 온라인 영상 (네트워크 문제로 인해 인식이 안될 수 있으며 여러번 시도해야 할 수 있습니다. 데모는 참고용입니다.)
YouTube 웹페이지를 탐색하여 원하는 동영상을 찾으세요. 오른쪽의 공유를 클릭하면 URL이 나타납니다. 이 URL을 웹페이지의 텍스트 상자에 복사하세요. 유튜브 주소 , '필사' 또는 '번역'을 선택한 다음 '제출'을 클릭하면 지정된 텍스트가 생성됩니다.
교류 및 토론
🖌️ 고품질 프로젝트를 발견하시면, 백그라운드에 메시지를 남겨 추천해주세요! 또한, 튜토리얼 교환 그룹도 만들었습니다. 친구들의 QR코드 스캔과 [SD 튜토리얼] 댓글을 통해 그룹에 가입하여 다양한 기술 이슈에 대해 논의하고 신청 결과를 공유해 주시기 바랍니다.↓
