Command Palette
Search for a command to run...
MinerU 원스톱 데이터 추출 도구
모델 소개

MinerU는 PDF를 기계가 읽을 수 있는 형식(예: 마크다운, JSON)으로 변환하는 도구로, 원하는 형식으로 쉽게 추출할 수 있습니다. 176개 언어의 정확한 인식과 정밀한 언어 유형 식별을 지원합니다. 이 제품은 이미지, 수식, 표, 각주 등이 포함된 복잡한 멀티모달 PDF 문서를 명확하고 분석하기 쉬운 마크다운 형식으로 변환하도록 특별히 설계되었습니다. 또한, MinerU는 광고 등의 간섭 정보가 포함된 웹 페이지나 전자책에서 정형화된 콘텐츠를 빠르게 파싱하고 추출하는 기능을 지원하여 AI 코퍼스 준비의 효율성을 효과적으로 향상시킵니다.
주요 특징
- 의미적 일관성을 유지하려면 머리글, 바닥글, 각주, 페이지 번호 및 기타 요소를 삭제하세요.
- 여러 열에 대해 사람이 읽을 수 있는 순서로 텍스트를 출력합니다.
- 제목, 문단, 목록 등을 포함하여 원본 문서의 구조를 보존합니다.
- 이미지, 그림 제목, 표, 표 제목 추출
- 문서의 수식을 자동으로 인식하고 이를 Latex로 변환합니다.
- 문서의 표를 자동으로 인식하고 이를 Latex로 변환합니다.
- 왜곡된 PDF에 대한 OCR을 자동으로 감지하고 활성화합니다.
- CPU 및 GPU 환경 지원
- Windows/Linux/Mac 플랫폼 지원
추론 단계 배포
이 튜토리얼에서는 모델과 환경을 배포했습니다. 튜토리얼의 설명에 따라 추론 대화를 위해 대형 모델을 직접 사용할 수 있습니다. 구체적인 튜토리얼은 다음과 같습니다.
1. 모델 구성
리소스가 구성된 후 컨테이너를 시작하고 API 주소의 링크를 클릭하여 데모 인터페이스로 들어갑니다.
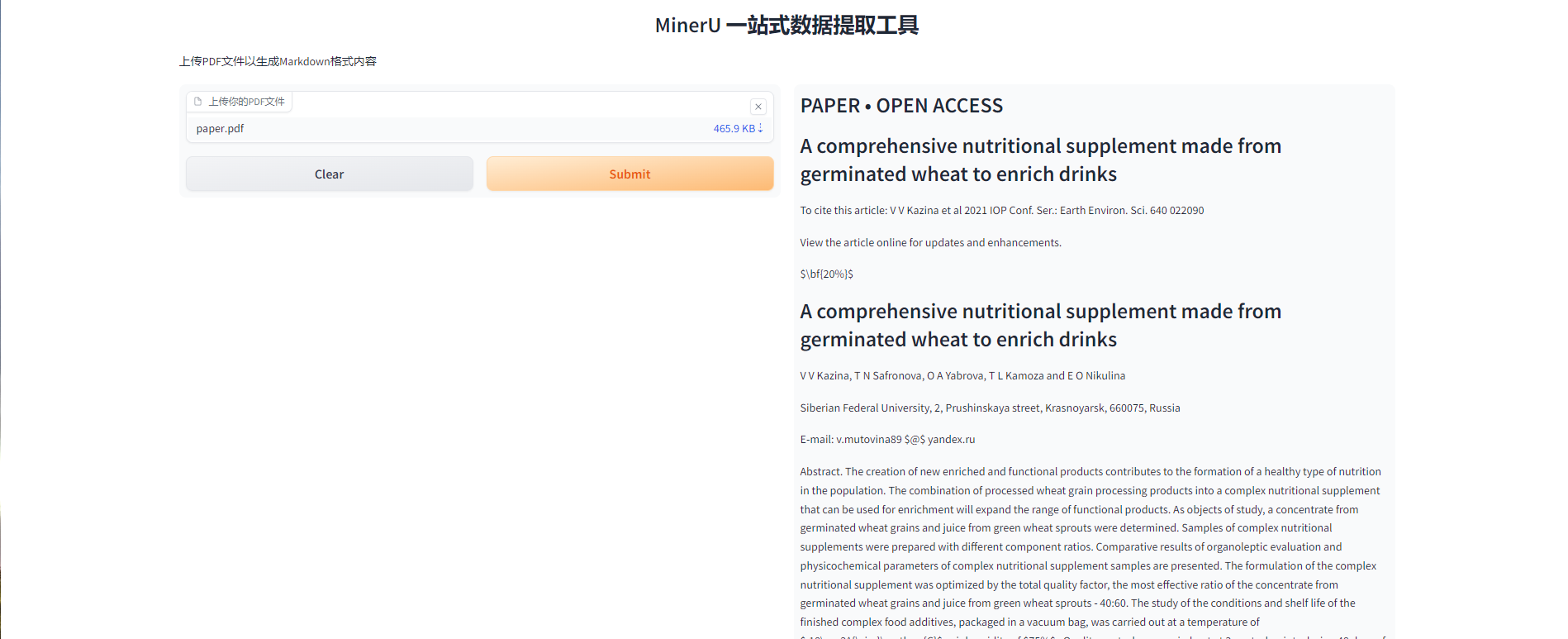
2. 인터페이스를 엽니다
잠시 후, 모델 인터페이스를 볼 수 있고, 그러면 모델을 사용할 수 있습니다. 사용자는 추출할 PDF 파일을 업로드할 수 있습니다(파일 크기는 5MB를 넘지 않아야 함). 제출 버튼을 클릭하면 모델 추출이 시작됩니다. 사용자가 모델을 체험해 볼 수 있도록 샘플 파일 paper.pdf도 그라디오 인터페이스에 제공됩니다. (이 파일의 추출 시간은 약 110초입니다)