Command Palette
Search for a command to run...
LongWriter-glm4-9b의 원클릭 배포
LongWriter: 장문맥 LLM의 10,000개 이상의 단어 생성 능력 활용

1. 튜토리얼 소개
LongWriter는 청화대학교 데이터 마이닝 연구 그룹(THUDM)에서 개발한 오픈 소스 프로젝트로, 장문 컨텍스트 대규모 언어 모델(LLM)을 사용하여 매우 긴 텍스트(10,000단어 이상)를 생성합니다. 이 프로젝트의 목표는 매우 긴 텍스트를 생성하는 데 있어 현재의 대규모 언어 모델의 한계를 극복하고, 생성된 콘텐츠가 긴 텍스트에서도 일관성과 관련성을 유지하도록 하는 것입니다. LongWriter는 문학 작품, 학술 논문, 뉴스 보도 등을 포함하되 이에 국한되지 않는 다양한 유형의 장문 텍스트 생성 작업에 적응할 수 있습니다. 이러한 다양성 덕분에 LongWriter는 실제 응용 분야에서 더 광범위하게 적용할 수 있습니다.
2. 작업 단계
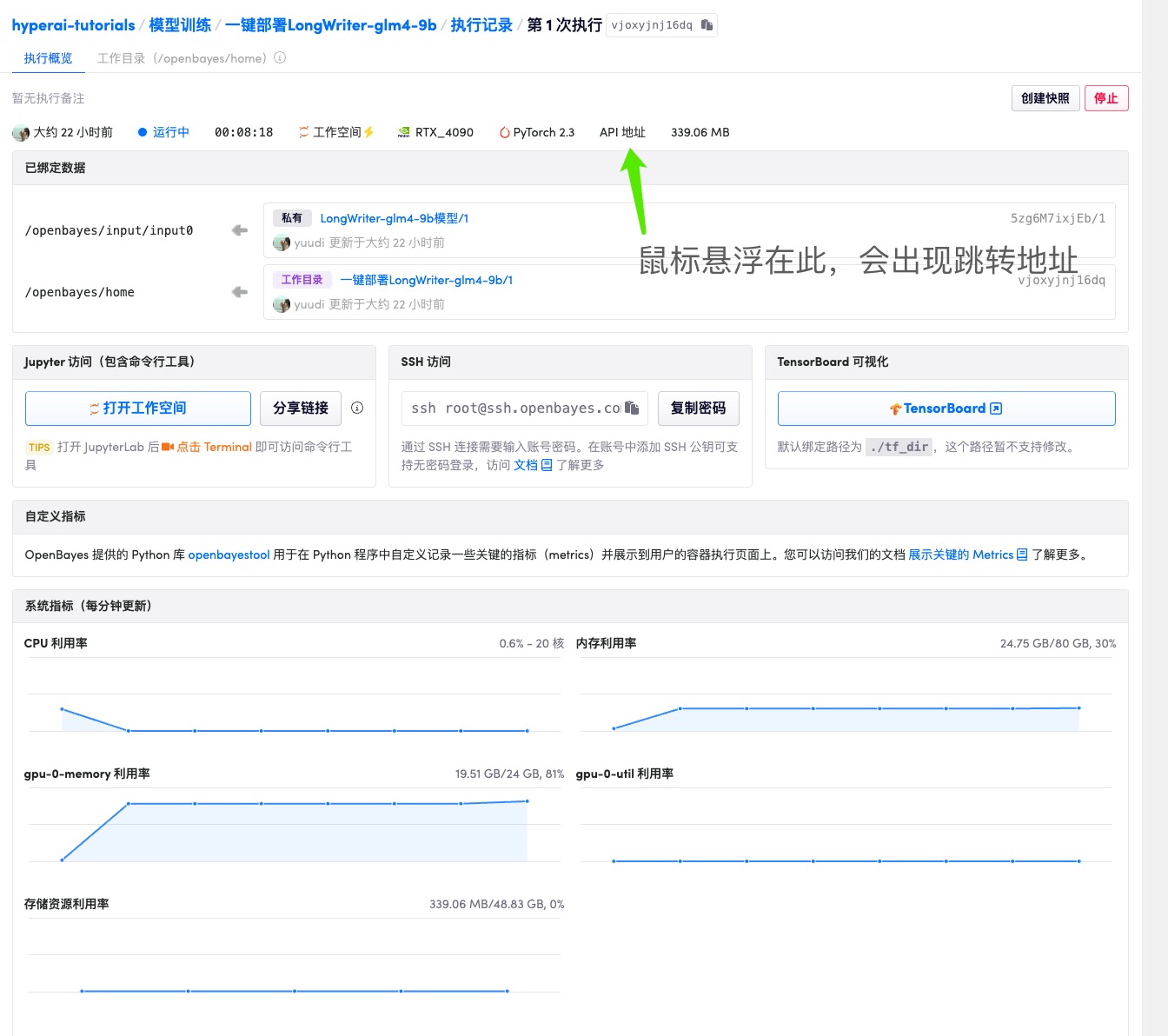
컨테이너를 시작한 후 API 주소를 클릭하여 웹 인터페이스로 들어갑니다.
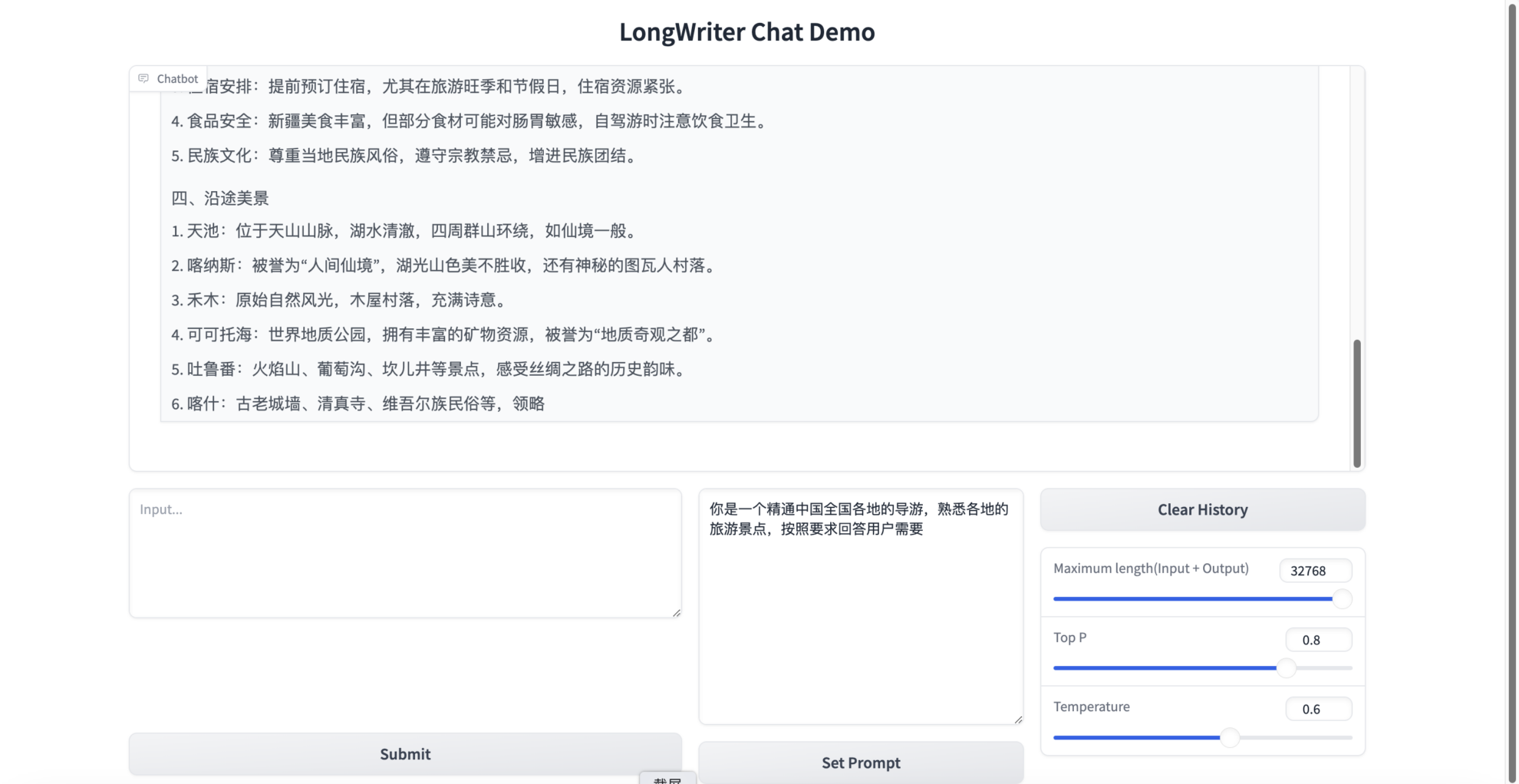
프롬프트를 설정한 다음 모델과 계속 대화할 수 있으며, 선택적으로 샘플링 매개변수를 조정할 수 있습니다.
- 최대 길이(입력 + 출력): 입력 + 출력 최대 컨텍스트 길이
- 상위 P: 예를 들어, p=0.9인 경우 누적 확률이 0.9에 도달하는 가장 작은 단어 집합에서만 단어를 선택하고 누적 확률이 0.9 미만인 다른 단어는 무시합니다. 이렇게 하면 부적절하거나 관련성이 없는 단어를 샘플링하는 것을 방지하는 동시에 흥미롭거나 창의적인 단어를 유지할 수 있습니다.
- 온도: 온도[0,1]는 생성된 데이터의 무작위성을 제어합니다. 온도가 높을수록 무작위성은 커집니다. 온도가 낮을수록 무작위성은 낮아집니다.
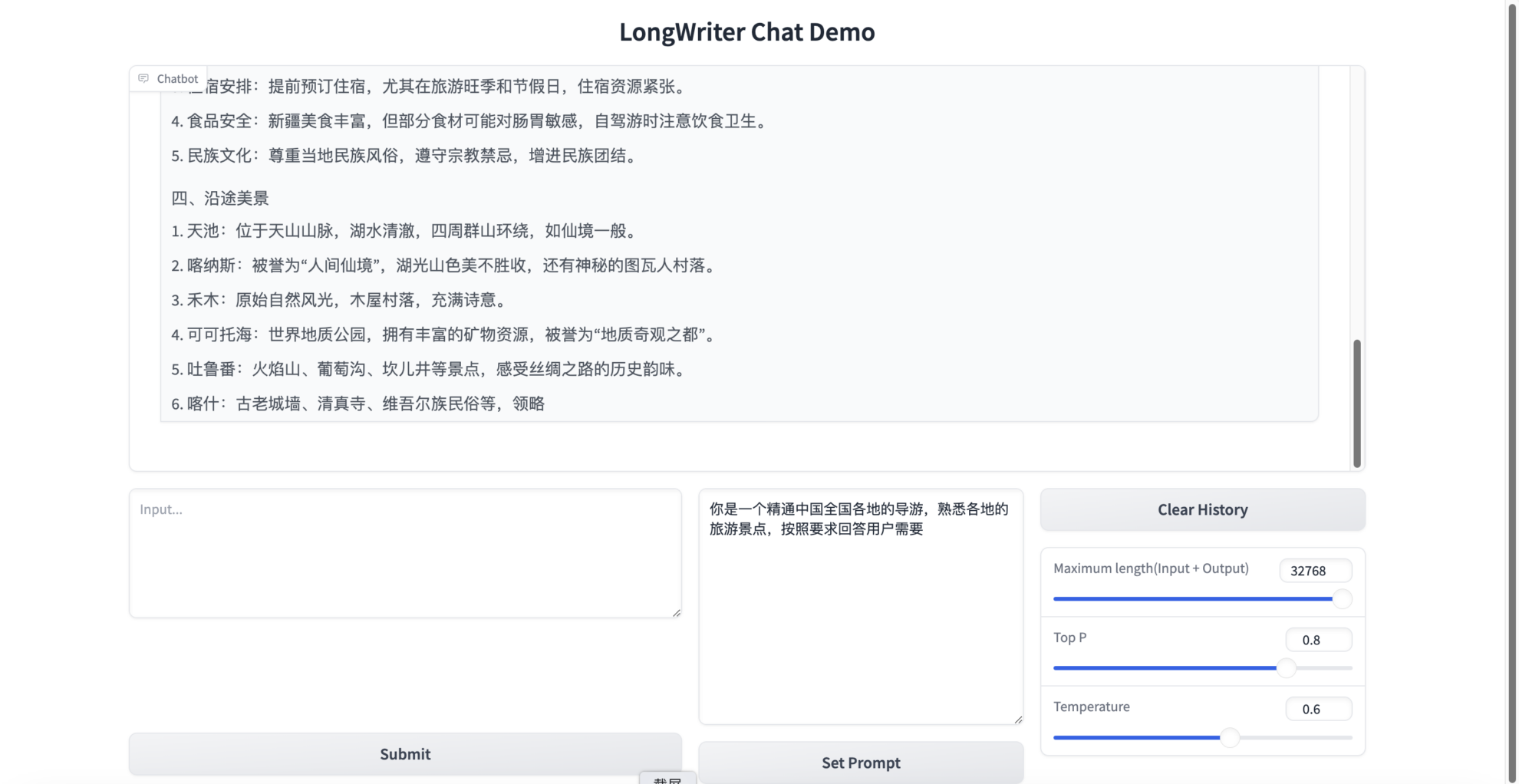
예를 들어, 다음 그림
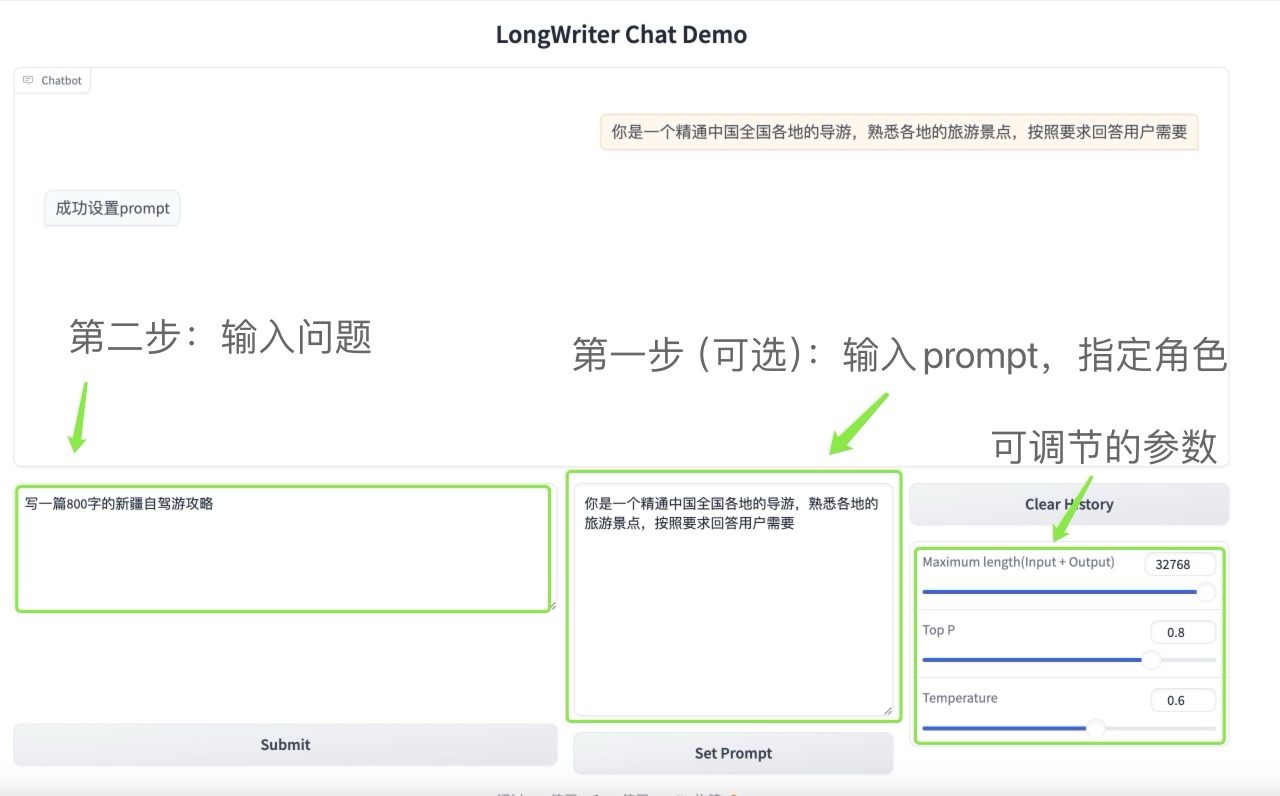
제출을 클릭하여 모델 출력 결과를 확인하세요.