Command Palette
Search for a command to run...
MuseTalk 고품질 립싱크 모델 데모
MuseTalk의 기능은 다음과 같습니다.
- 실시간: 실시간 환경에서 실행이 가능하며, 초당 30프레임 이상의 처리 속도를 달성하여 매끄러운 립 동기화를 보장합니다.
- 고품질 동기화: 잠재 공간 인페인팅 방법을 사용하여 얼굴 특징을 유지하면서 입력 오디오를 기반으로 입 모양을 조정하여 고품질 립싱크를 구현합니다.
- MuseV와 호환: MuseTalk는 가상 인간 비디오를 생성할 수 있는 비디오 생성 프레임워크인 MuseV 모델과 함께 사용할 수 있습니다.
- 오픈 소스: MuseTalk의 코드는 커뮤니티 기여와 추가 개발을 용이하게 하기 위해 오픈 소스로 공개되었습니다.
MuseTalk은 립싱크 생성에 탁월하며, 특히 실제 사람 영상 생성에 있어서 좋은 영상 일관성을 유지하면서 정확한 립싱크를 생성할 수 있습니다. 또한 EMO, AniPortrait, Vlogger, Microsoft의 VASA-1 등 다른 제품과 비교해도 장점이 있습니다.
효과 예시
모델 프레임워크
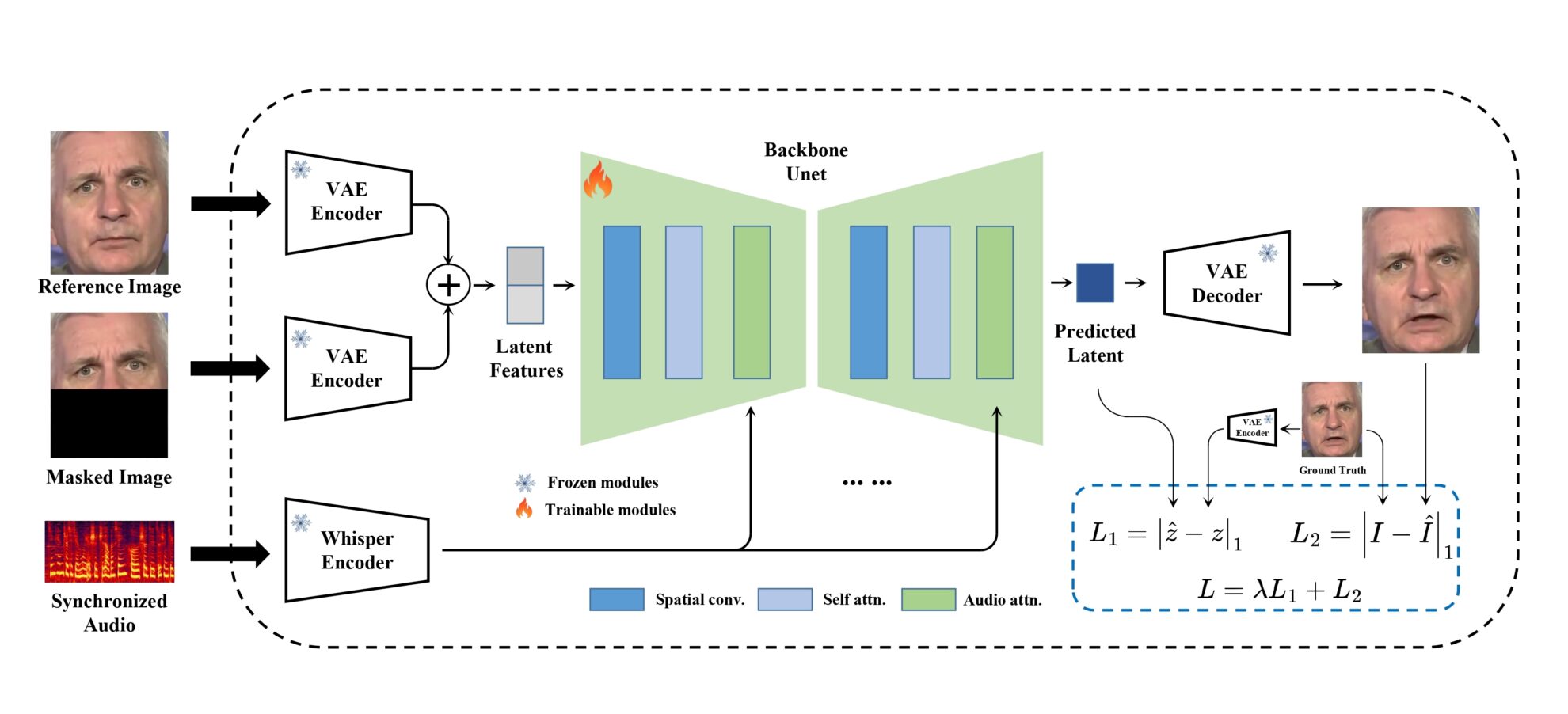
MuseTalk 훈련은 이미지가 동결된 VAE에 의해 인코딩되는 잠재 공간에서 수행됩니다. 오디오는 얼어붙은 아주 작은 모델에 의해 인코딩되었습니다. 생성 네트워크의 아키텍처는 오디오 임베딩이 교차 관심을 통해 이미지 임베딩과 융합된 stable-diffusion-v1-4의 UNet에서 차용되었습니다.
실행 단계
1. 프로젝트의 오른쪽 상단에 있는 "복제"를 클릭한 후 "다음"을 클릭하여 다음 단계를 완료합니다. 기본 정보 > 컴퓨팅 성능 선택 > 검토. 마지막으로 "계속"을 클릭하여 개인 컨테이너에서 이 프로젝트를 엽니다.
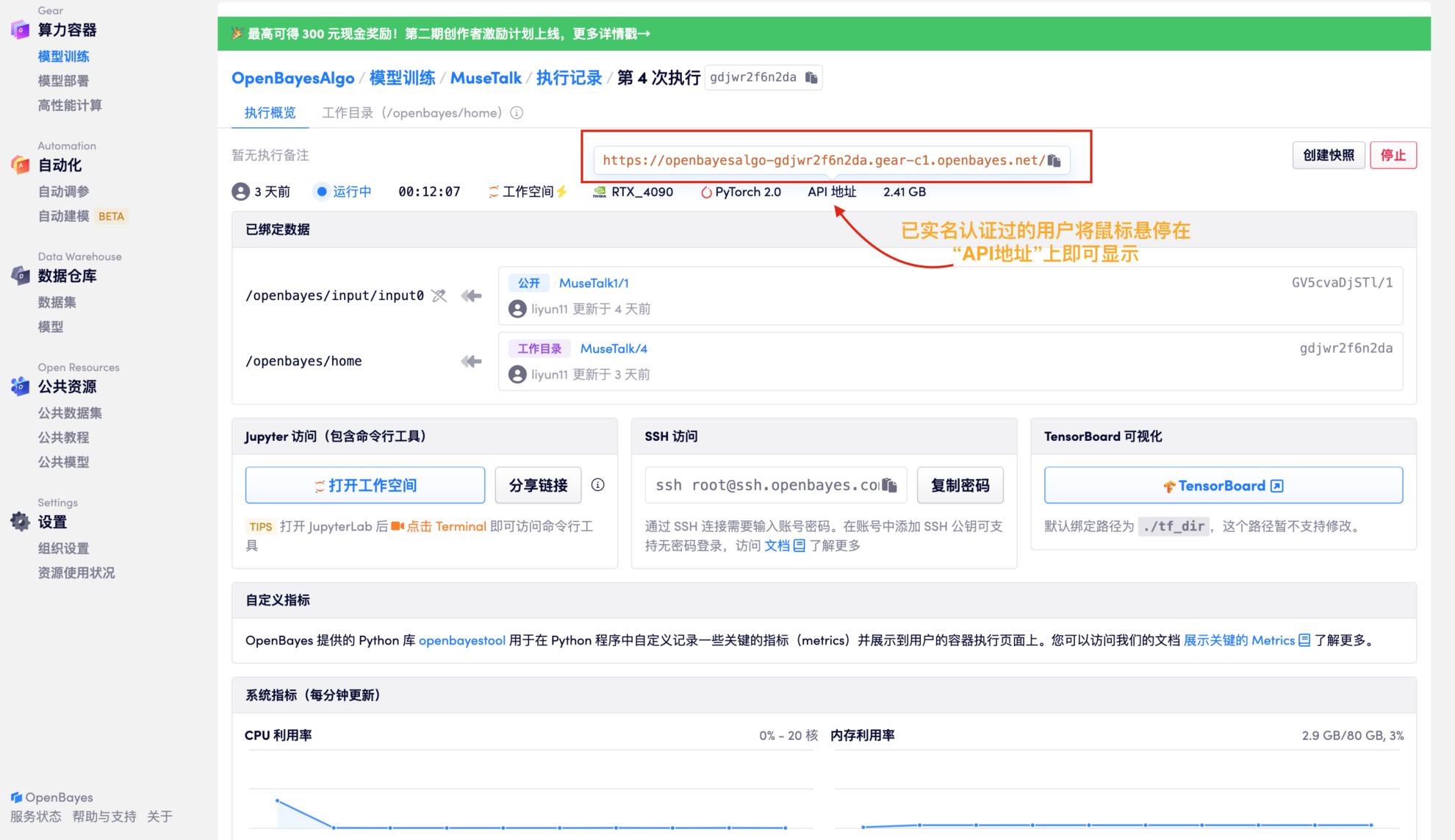
2. 리소스 할당이 완료되면 API 주소를 직접 복사하여 임의의 URL에 붙여넣습니다. (실명 인증이 완료되어야 하며, 이 단계에서는 작업 공간을 열 필요가 없습니다.)
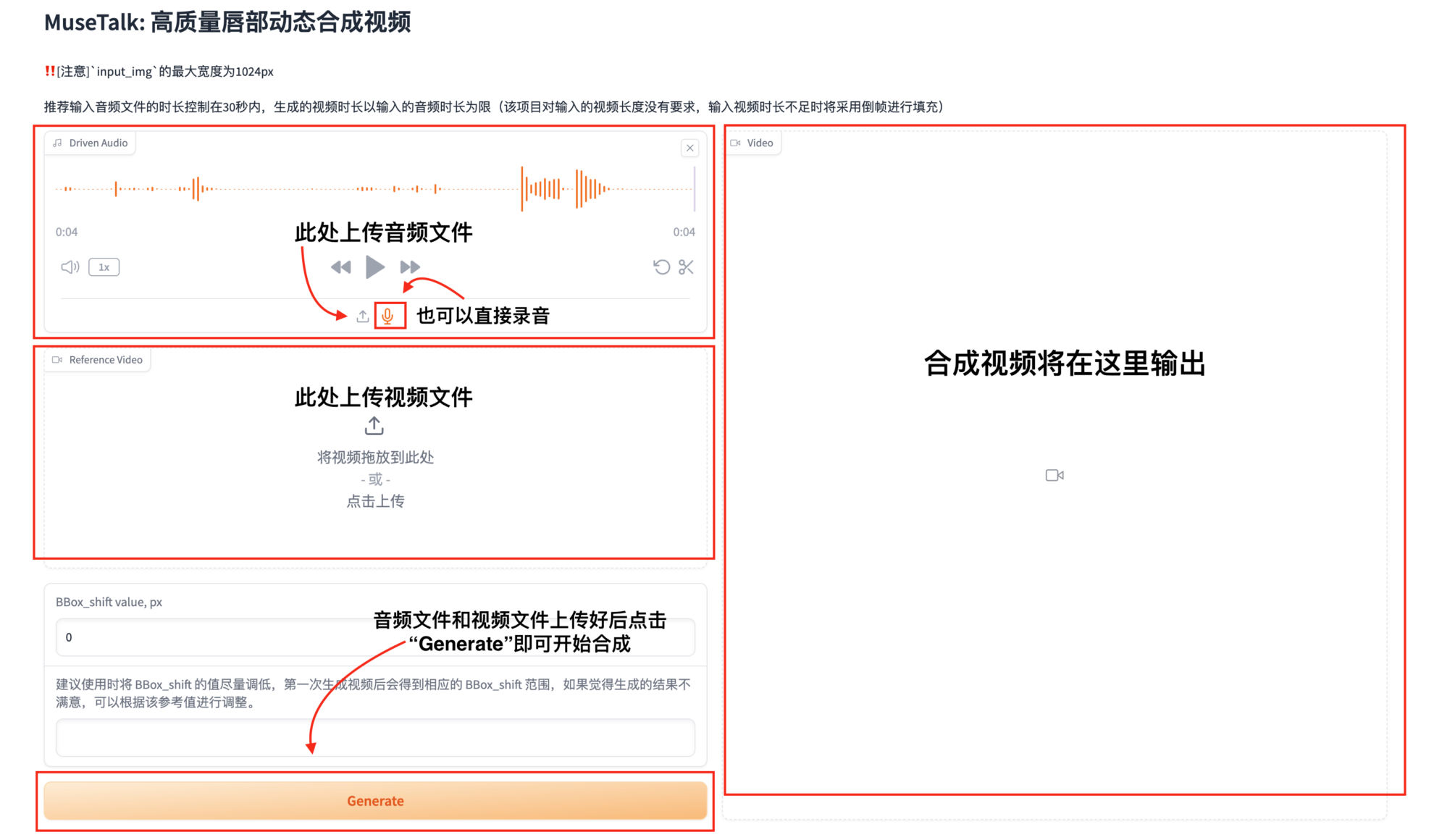
3. 합성을 위한 오디오 및 비디오 파일 업로드
테스트 결과: 17초 길이의 오디오 파일을 생성하는 데 약 3분이 걸렸습니다. 약 1분 길이의 오디오 파일을 생성하는 데는 약 6분이 걸립니다.
-|MuseTalk 얼굴과 입 모양은 입력 오디오에 따라 수정될 수 있습니다. 얼굴 영역의 크기는 바람직하게는 256 x 256입니다. MuseTalk 또한 얼굴 영역 중심점 제안을 수정하는 기능도 지원하는데, 이는 생성된 결과에 상당한 영향을 미칩니다.
- |현재 MuseTalk 중국어, 영어, 일본어 등 여러 언어로 오디오 입력을 지원합니다.
- |최종적으로 생성되는 비디오 길이는 오디오 길이를 기준으로 합니다.