Command Palette
Search for a command to run...
MuseV 무제한 길이의 가상 인간 비디오 생성 데모

프로젝트 소개
MuseV 텐센트 뮤직 엔터테인먼트의 톈친 랩이 2024년 3월에 오픈 소스로 공개한 가상 인간 비디오 생성 프레임워크로, 고품질 가상 인간 비디오와 립싱크 생성에 중점을 두고 있습니다. 고급 알고리즘을 사용하여 높은 일관성과 자연스러운 표현을 갖춘 긴 비디오 콘텐츠를 제작합니다. 이미 게시된 것과 결합될 수 있습니다. 뮤즈톡 이러한 두 가지를 조합하여 사용하면 완전한 "가상 인간 솔루션"을 구축할 수 있습니다.
이 모델은 다음과 같은 특징을 가지고 있습니다.
- 이 기술은 오류 누적 문제 없이 무한 길이를 생성하는 새로운 시각적 조건부 병렬 잡음 제거 방식을 지원하며, 특히 카메라 위치가 고정된 장면에 적합합니다.
- 문자 유형 데이터 세트를 기반으로 한 가상 인간 비디오 생성을 위한 사전 학습된 모델이 제공됩니다.
- 이미지-비디오, 텍스트-이미지-비디오, 비디오-비디오 생성을 지원합니다.
- 호환 가능
Stable Diffusion텍스트 및 이미지 생성 생태계에는 다음이 포함됩니다.base_model,lora,controlnet기다리다. - 다음을 포함한 여러 참조 이미지 기술을 지원합니다.
IPAdapter,ReferenceOnly,ReferenceNet,IPAdapterFaceID.
효과 표시
결과를 생성하는 모든 프레임은 다음에 의해 직접 생성됩니다. MuseV 시간적 초해상도나 공간적 초해상도와 같은 후처리 과정 없이 생성됩니다.
이 튜토리얼에서는 다음의 모든 테스트 사례를 구현할 수 있습니다. 테스트 결과, 7초 분량의 영상을 생성하는 데 약 2분 30초가 걸리는 것으로 나타났습니다. 테스트한 가장 긴 영상은 20초 길이로 8분 걸렸습니다.
캐릭터 효과 표시
| 영상 | 동영상 | 즉각적인 |
 | (걸작, 최상의 품질, 고해상도: 1), 평화롭고 아름다운 바다 풍경 | |
 | (걸작, 최상의 품질, 고해상도:1), 기타 연주 | |
 | (걸작, 최상의 품질, 고해상도:1), 기타 연주 |
장면 효과 표시
| 영상 | 동영상 | 즉각적인 |
 | (걸작, 최상의 품질, 고해상도:1), 평화롭고 아름다운 폭포, 끝없는 폭포 | |
 | (걸작, 최상의 품질, 고해상도: 1), 평화롭고 아름다운 바다 풍경 |
기존 비디오에서 비디오 생성
| 영상 | 동영상 | 즉각적인 |
 | (걸작, 최상의 품질, 고해상도:1), 춤추는 애니메이션 |
실행 단계
1. 이 튜토리얼의 오른쪽 상단 모서리에 있는 "복제" 버튼을 찾으세요. "복제"를 클릭한 후 플랫폼의 기본 구성을 직접 사용하여 컨테이너를 생성합니다. 컨테이너가 성공적으로 실행되고 시작될 때까지 기다리면 아래 그림에 표시된 페이지가 표시됩니다. 그림의 지시에 따라 프로젝트 운영 인터페이스로 들어가세요.
❗참고❗ 모델이 크기 때문에 컨테이너가 성공적으로 시작된 후 API 주소를 열기 전까지 모델을 로드하는 데 약 1분이 걸릴 수 있습니다.
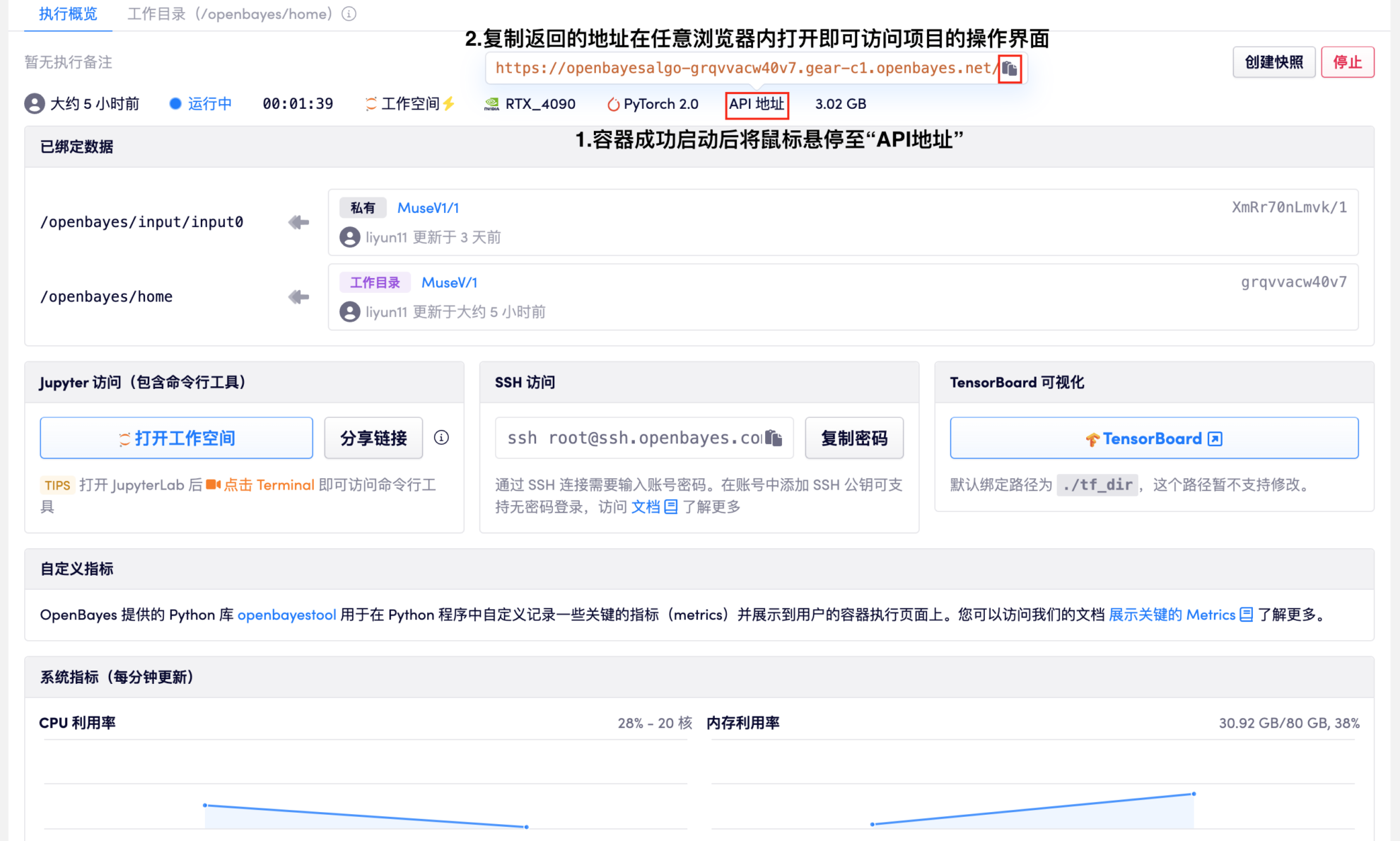
2. 페이지의 사용법은 다음과 같습니다.

교류 및 토론
🖌️ 고품질 프로젝트를 발견하시면, 백그라운드에 메시지를 남겨 추천해주세요! 또한, 튜토리얼 교환 그룹도 만들었습니다. 친구들의 QR코드 스캔과 [SD 튜토리얼] 댓글을 통해 그룹에 가입하여 다양한 기술 이슈에 대해 논의하고 신청 결과를 공유해 주시기 바랍니다.↓
