Command Palette
Search for a command to run...
FLUX.1-슈넬 빈센트 데모


튜토리얼 소개
FLUX.1은 텍스트 설명으로부터 이미지를 생성할 수 있는 120억 개의 매개변수를 갖춘 대형 모델입니다. 우리는 텍스트-이미지 합성을 위한 이미지 세부 정보, 시간 준수, 스타일 다양성, 장면 복잡성 측면에서 새로운 최첨단 기술을 정의합니다. 이 튜토리얼에서는 FLUX.1 [schnell] 버전 모델을 사용합니다. 모델과 환경이 배포되었습니다. 튜토리얼 지침에 따라 대규모 모델을 사용하여 추론 대화를 직접 수행할 수 있습니다.
모델이 크기 때문에 A6000을 사용하여 실행해야 하며 단일 4090 카드로는 시작할 수 없습니다.
FLUX.1은 이미지 합성의 최첨단 기술을 정의합니다. FLUX.1 [pro] 및 [dev]는 Midjourney v6.0, DALL·E 3(HD), SD3-Ultra 등 인기 모델을 시각적 품질, 빠른 후속 조치, 크기/종횡비 가변성, 타이포그래피, 출력 다양성 등 모든 면에서 능가합니다. FLUX.1[schnell]은 현재까지 가장 진보된 몇 단계 모델로, 경쟁 모델뿐만 아니라 Midjourney v6.0 및 DALL·E 3(HD)와 같은 강력한 비증류 모델보다 성능이 뛰어납니다.
접근성과 모델 기능 간의 균형을 맞추기 위해 FLUX.1은 FLUX.1 [pro] , FLUX.1 [dev] 및 FLUX.1 [schnell]의 세 가지 버전으로 제공됩니다.
FLUX.1 [pro]: FLUX.1의 가장 뛰어난 기능으로, 최고 수준의 즉각적 추적, 시각적 품질, 이미지 디테일 및 다양한 출력 기능을 갖춘 최첨단 성능 이미지 생성 기능을 제공합니다. 상업적 목적으로 사용할 수 없으며, 사용하려면 연구팀에 문의해야 합니다. FLUX.1[dev]: FLUX.1[dev]은 비상업적 응용 프로그램에 적합한 개방형 가중치의 가이드 세분화 모델입니다. FLUX.1[dev]는 FLUX.1[pro]에서 직접 파생되었으며 동일한 크기의 표준 모델보다 효율성이 더 높으면서도 유사한 품질과 시기적절한 규정을 갖추고 있습니다. FLUX.1 [dev] 가중치는 HuggingFace에서 사용할 수 있으며 Replicate 또는 Fal.ai에서 직접 시도할 수 있습니다. 상업적 용도로 사용할 수 없습니다. FLUX.1 [schnell]: 이 모델은 지역 개발 및 개인 사용에 맞게 제작되었습니다. FLUX.1[schnell]은 Apache 2.0 라이선스에 따라 공개적으로 사용 가능합니다.
주요 특징
- 최첨단 출력 품질과 경쟁력 있는 빠른 추종성으로 폐쇄형 소스 대안의 성능과 일치합니다.
- 잠재성 적대 확산 증류법을 사용하여 훈련된 FLUX.1[schnell]은 단 1~4단계만으로 고품질 이미지를 생성할 수 있습니다.
- 이 모델은 Apache-2.0 라이선스에 따라 공개되었으며 개인적, 과학적, 상업적 목적으로 사용할 수 있습니다.
다른 Wenshengtu 모델 점수와의 비교
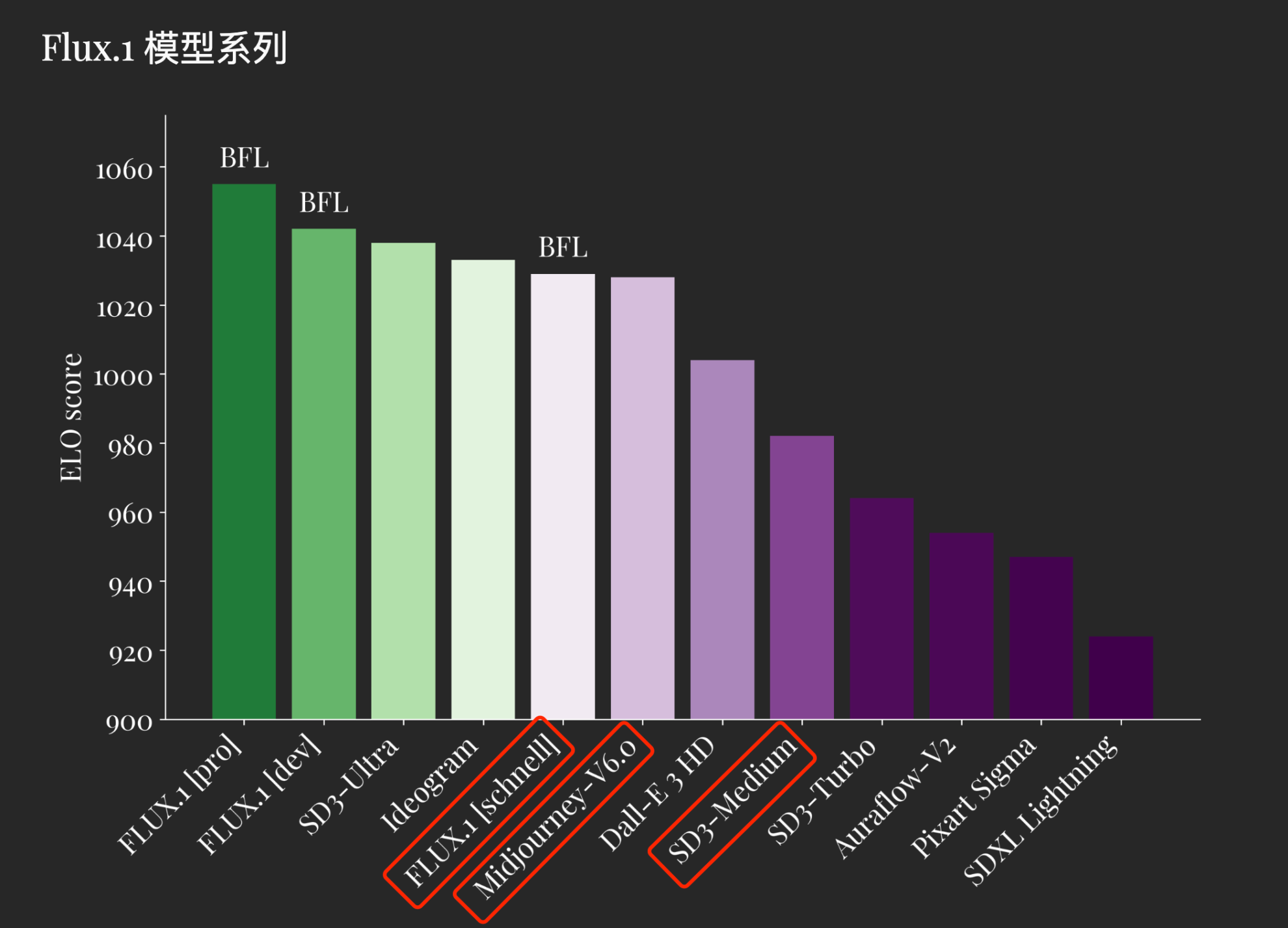
추론 단계 배포
이 튜토리얼에서는 모델과 환경을 배포했습니다. 튜토리얼의 설명에 따라 추론 대화를 위해 대형 모델을 직접 사용할 수 있습니다. 구체적인 튜토리얼은 다음과 같습니다.
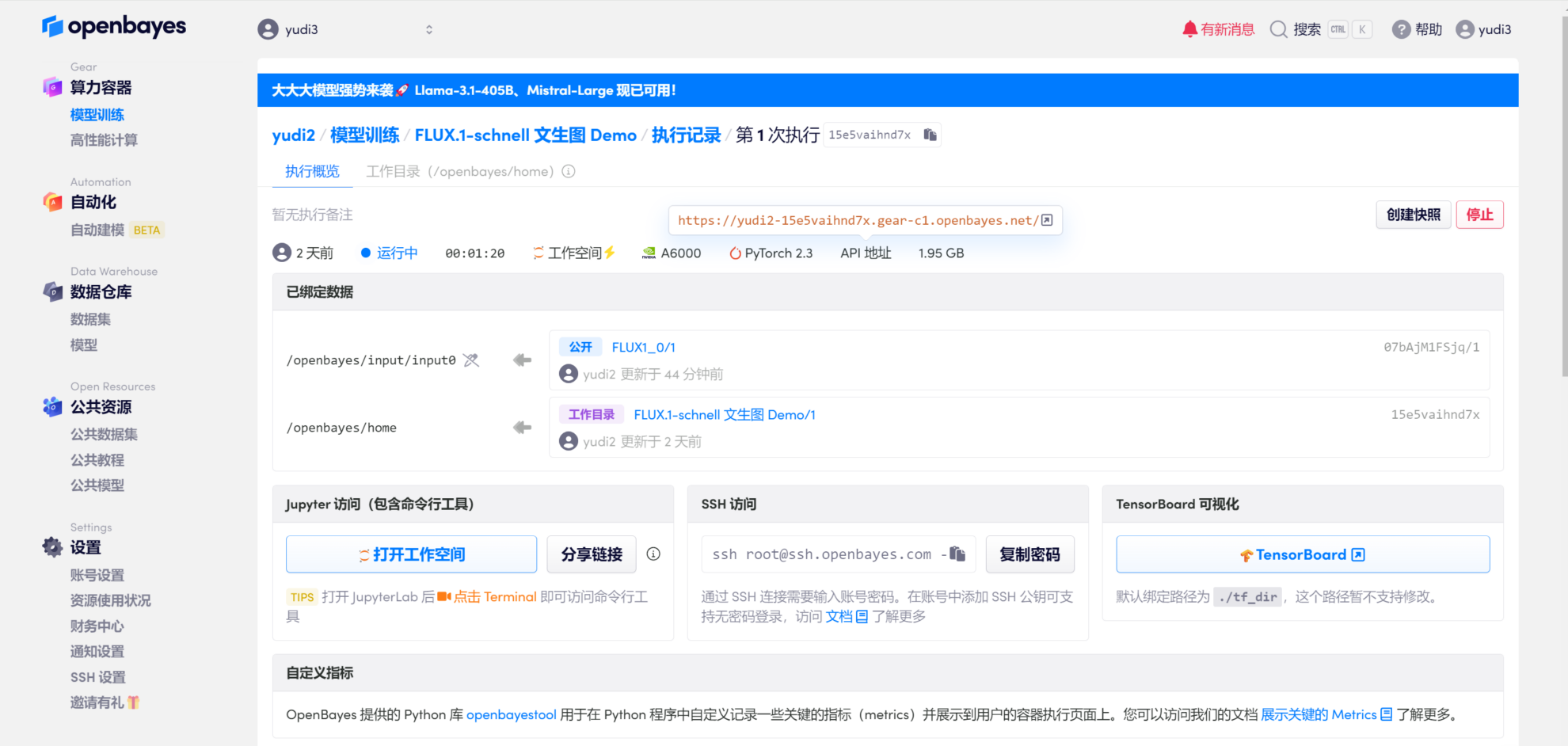
1. 인터페이스를 엽니다
페이지 오른쪽 상단에 있는 "복제"를 클릭하여 컨테이너를 복제하고 시작합니다. 리소스가 구성된 후 컨테이너를 시작하고 API 주소의 링크를 직접 클릭하여 데모 인터페이스로 들어갑니다.
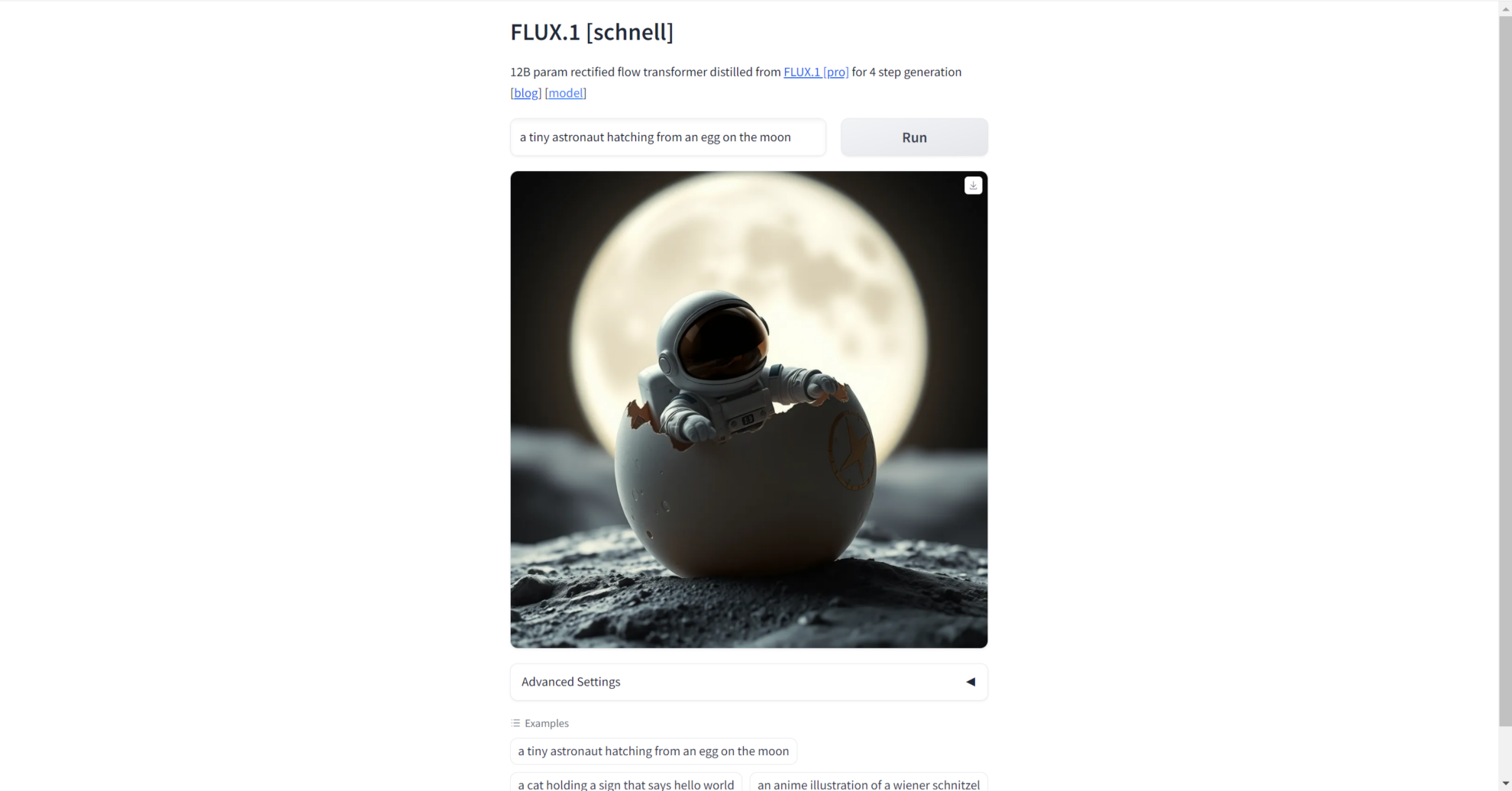
2. 프롬프트 단어를 입력하세요
인터페이스를 연 후, 생성하려는 그림에 대한 프롬프트 단어를 입력하면 해당 고품질 그림이 생성됩니다. 또한 예제 속의 예제를 사용하여 검증할 수도 있습니다.
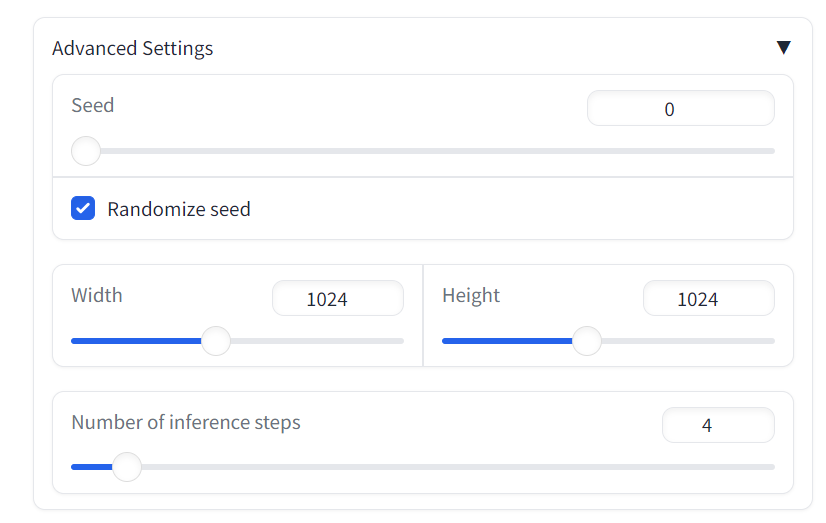
3. 매개변수 변경
사용자가 조정할 수 있는 여러 매개변수가 모델에 있습니다. 우리는 모델의 추론 단계 수를 독립적으로 조정하고 이미지의 길이와 너비와 같은 매개변수를 생성할 수 있습니다.
토론 및 교류
🖌️ 고품질 프로젝트를 발견하시면, 백그라운드에 메시지를 남겨 추천해주세요! 또한, 튜토리얼 교환 그룹도 만들었습니다. 친구들의 QR코드 스캔 및 [튜토리얼 교환]에 댓글을 남겨 그룹에 가입하여 다양한 기술 이슈에 대해 논의하고 신청 결과를 공유해 주시기 바랍니다.↓ 