Command Palette
Search for a command to run...
Gibbs-Diffusion을 사용하여 블라인드 이미지 노이즈 제거
Gibbs-Diffusion 기반 이미지 블라인드 노이즈 제거

튜토리얼 소개
GDiff는 Gibbs-Diffusion의 약자로, 신호 및 잡음 매개변수의 사후 샘플링 문제를 해결하는 베이지안 블라인드 잡음 제거 방법입니다. 이는 사전 훈련된 확산 모델(신호 사전 정의)과 해밀턴 몬테카를로 샘플러를 번갈아 샘플링하는 깁스 샘플러에 의존합니다. 이 논문에서는 자연 이미지 잡음 제거와 우주론(우주 마이크로파 배경 분석)에서의 응용을 소개합니다. 논문 결과는 다음과 같습니다.소음 듣기: Gibbs 확산을 이용한 블라인드 노이즈 제거"
공식 문서에서는 테스트 방법만 제공하는데, 이는 선명한 원본 이미지를 통과시키고 노이즈를 중첩한 다음 블라인드 제거와 블라인드 제거를 비교하는 것입니다.
효과 시연
공식적인 효과 시연에서는 선명한 원본 이미지를 입력하고, 특정 매개변수의 노이즈를 중첩한 후 블라인드 디노이징을 수행합니다.
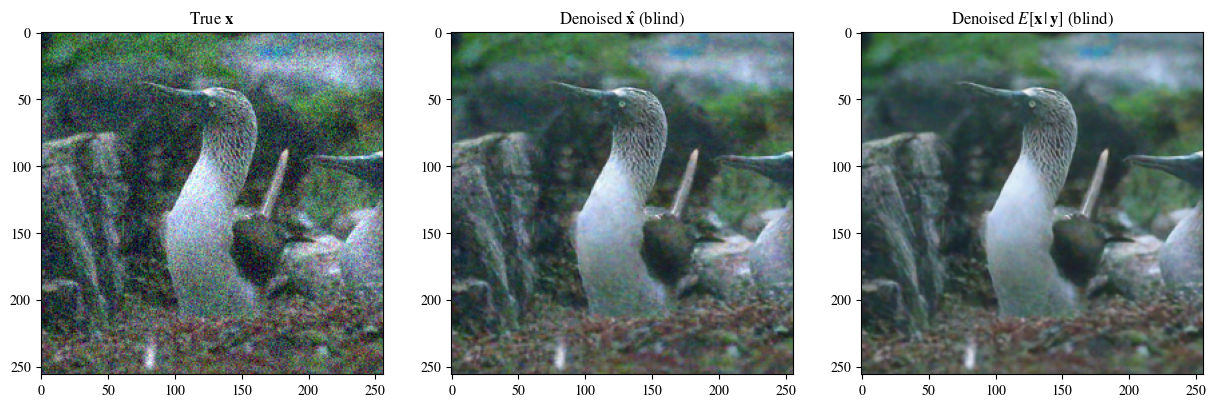
다음 그림은 왼쪽에서 오른쪽으로 노이즈를 중첩한 후의 이미지, 원본 이미지, 블라인드 노이즈 제거 효과, 노이즈 제거된 사후 평균입니다.

블라인드 노이즈 제거 및 비블라인드 노이즈 제거 소개
블라인드 디노이징과 논블라인드 디노이징은 이미지 처리와 신호 처리에서 사용되는 두 가지 디노이징 방법입니다. 두 방법의 주요 차이점은 소음 정보의 예측 정도에 있습니다.
블라인드 디노이징
정의: 블라인드 노이즈 제거는 노이즈 특성이나 노이즈 모델을 알지 못한 채 노이즈를 제거하는 것을 말합니다. 이 방법은 노이즈에 대한 사전 지식에 의존하지 않고, 이미지나 신호 자체의 정보를 사용해 노이즈를 제거합니다.
특징:
- 소음 모델에 독립적입니다. 소음의 유형, 분포 또는 강도를 알 필요가 없습니다.
- 강력한 적응성: 다양한 유형의 소음 및 신호 환경에 적용될 수 있습니다.
- 높은 복잡성: 노이즈 모델의 도움이 없으므로 블라인드 노이즈 제거에는 일반적으로 더 복잡한 알고리즘과 더 많은 컴퓨팅 리소스가 필요합니다.
비맹검 노이즈 제거
정의: 블라인드가 아닌 잡음 제거는 잡음 특성이나 잡음 모델이 알려져 있을 때 잡음을 제거하는 것을 말합니다. 이 방법은 잡음에 대한 사전 지식을 활용하여 잡음 제거 프로세스를 최적화합니다.
특징:
- 소음 모델에 대한 의존성: 소음의 종류, 분포, 강도에 대한 사전 지식이 필요합니다.
- 더 나은 효과: 노이즈 모델이 알려지면 특정 노이즈 유형에 맞게 최적화하여 더 나은 노이즈 제거 효과를 얻을 수 있습니다.
- 적용 범위가 제한적입니다. 소음 유형에 따라 서로 다른 모델과 매개변수가 필요하며, 블라인드 노이즈 제거보다 적용 범위가 좁습니다.
튜토리얼을 실행하는 방법
이 튜토리얼은 두 부분으로 나뉩니다. 첫 번째 부분은 "흐린 이미지의 블라인드 노이즈 제거"로, start.ipynb 파일(이 파일)에서 실행할 수 있습니다. 여기서는 노이즈가 있는 흐릿한 이미지를 전달하여 블라인드 노이즈 제거를 수행할 수 있습니다. 두 번째 부분은 test.ipynb 파일에서 실행되는 "Clear Image Superimposed Noise and Denoising"입니다. 이는 공식 문서를 간소화한 것으로, 블라인드 디노이징 모델과 비스블라인드 디노이징 모델의 차이를 비교하기 위해 중첩된 노이즈가 있는 선명한 이미지를 전달하는 데 사용할 수 있습니다.
사용자 정의 이미지를 사용해야 하는 경우 이미지를 업로드하고 처리하려는 이미지의 경로를 수정한 다음 하나씩 실행하면 됩니다. (사진 이름은 반드시 영어로 작성해주세요)
1부: 흐릿한 이미지의 블라인드 노이즈 제거(start.ipynb)
필요한 패키지 가져오기
import sys, time
import torch
import numpy as np
import matplotlib.pyplot as plt
import corner
import arviz as az
from PIL import Image
sys.path.append('..')
from gdiff.data import ImageDataset, get_colored_noise_2d
from gdiff.model import load_model
import gdiff.hmc_utils as iut
from gdiff.utils import ssim, psnr, plot_power_spectrum, plot_list_of_images
plt.rcParams.update(
{
'text.usetex': False,
'font.family': 'stixgeneral',
'mathtext.fontset': 'stix',
}
)이미지 읽기 및 전처리 기능, 사용 방법은 공식 문서 data.py에서 가져왔습니다.
#图片读取与预处理,方法来自官方文档 data.py
def readimg(filename):
from torchvision import transforms
img=Image.open(filename)
trans = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(256),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()])
img=trans(img)
return img다음은 이 문서에서는 사용되지 않는, 데이터 세트를 읽는 공식적인 방법입니다. 사용자는 자신의 폴더에 자신의 데이터 세트를 넣고 일괄 처리를 달성하기 위해 약간의 수정을 할 수 있습니다(데이터 폴더에서 몇 개의 폴더 이름만 선택할 수 있음)
#
# PARAMETERS 官方数据读取与噪声参数,模型选择
#
# Dataset and sample 读取官方数据集
dataset_name = "CBSD68" # Choices among "imagenet_train", "imagenet_val", "CBSD68", "McMaster", "Kodak24"
dataset = ImageDataset(dataset_name, data_dir='./data')
sample_id = 0 # np.random.randint(len(dataset))
# Noise 准备叠在在清晰图片上的噪声
phi_true = -0.4 # Spectral index -> between -1 and 1 (\varphi in the paper)
sigma_true = 0.1 # Noise level
# Device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Model 选择模型,有 5000 与 10000 步迭代模型可选
diffusion_steps = 5000 # Number of diffusion steps: 5000 or 10000
model = load_model(diffusion_steps=diffusion_steps,
device=device,
root_dir='./model_checkpoints')
model.eval()
# Inference
num_chains = 4 # Number of HMC chains
n_it_gibbs = 50 # Number of Gibbs iterations after burn-in
n_it_burnin = 25 # Number of burn-in iterations다음으로, 노이즈를 제거해야 할 이미지를 읽습니다. 예를 들어, 이 튜토리얼에서 사용된 이미지는 홈 디렉토리에 있는 '3_noisy.png'입니다. img=readimg('3_noisy.png')에서 경로를 '3_noisy.png'로 변경하기만 하면 됩니다.
A6000의 경우 카드 1장을 사용하면 1장의 이미지를 처리하는 데 몇 분이 걸립니다.
#
# DENOISING 在此处读入的图片为高噪声图,在此处进行降噪处理
#
# 读取自己的高噪声图片,用于去噪
img=readimg('3_noisy.png')
x = img.to(device).unsqueeze(0)
# Our DDPM has discrete timestepping -> we get the time step closest to the chosen noise level
sigma_true_timestep, sigma_true = model.get_closest_timestep(torch.tensor([sigma_true]), ret_sigma=True)
alpha_bar_t = model.alpha_bar_t[sigma_true_timestep.cpu()].reshape(-1, 1, 1, 1).to(device)
print(f"Time step corresponding to noise level {sigma_true.item():.3f}: {sigma_true_timestep.item()}")
yt = torch.sqrt(alpha_bar_t) * x # Noisy image normalized for the diffusion model 归一化图像
# Non-blind denoising (for reference) 非盲去噪 即已知噪声参数的情况下去噪
print("Denoising in non-blind setting...")
t0 = time.time()
x_hat_nonblind = model.denoise_samples_batch_time(yt,
sigma_true_timestep.unsqueeze(0),
phi_ps=phi_true)
t1 = time.time()
print(f"Non-blind denoising took {t1-t0:.2f} seconds")
# Blind denoising with GDiff 基于 GDiff 的盲去噪
print("Denoising in blind setting (GDiff)...")
t0 = time.time()
phi_hat_blind, x_hat_blind = model.blind_denoising(x, yt,
num_chains_per_sample=num_chains,
n_it_gibbs=n_it_gibbs,
n_it_burnin=n_it_burnin)
t1 = time.time()
print(f"Blind denoising took {t1-t0:.2f} seconds")
# Denoised posterior mean estimate 去噪的后验均值估计
x_hat_blind_pmean = x_hat_blind[:, n_it_burnin:].mean(dim=(0, 1))소음 수준 0.100에 해당하는 시간 단계: 134 블라인드가 아닌 설정에서 소음 제거... 블라인드가 아닌 설정에서 소음 제거에 4.48초가 걸렸습니다. 블라인드 설정에서 소음 제거(GDiff)...
0%| | 0/75 [00:00
300번의 반복을 사용하여 단계 크기 조정 단계 크기는 tensor([0.0179, 0.0181, 0.0179, 0.0194], device='cuda:0')로 고정됩니다.
100%|██████████| 75/75 [08:52<00:00, 7.10초/시간]
블라인드 노이즈 제거에 532.30초가 걸렸습니다.
#
# Plot of a reconstruction 展示结果 顺序为:原始图片 非盲去噪 盲去噪 去噪的后验均值
#
data = [x[0],
x_hat_blind[0, -1],
x_hat_blind_pmean]
data = [d.to(device) for d in data]
labels_base = [r"True $\mathbf{x}$",
r"Denoised $\hat{\mathbf{x}}$ (blind)",
r"Denoised $E[\mathbf{x}\,|\,\mathbf{y}]$ (blind)"]
labels = [labels_base[0] ,
labels_base[1] ,
labels_base[2] ]
plot_list_of_images(data, labels)
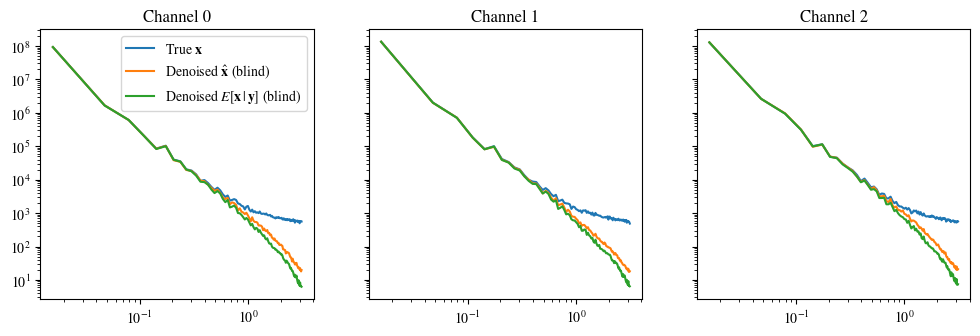
plot_power_spectrum(data, labels_base, figsize=(12, 3.5))RGB 데이터([0..1]은 부동 소수점 수이고 [0..255]는 정수)를 사용하여 imshow의 유효 범위에 입력 데이터를 클리핑합니다.