Command Palette
Search for a command to run...
효율적인 배포를 위한 양자화 비전 변환기(Vit): 전략 및 모범 사례
이 튜토리얼에서는 PyTorch 버전 2.0과 단일 4090 GPU를 사용하는 것이 좋습니다. 사용 편의성을 위해 사용된 모델이 튜토리얼에 다운로드되어 있습니다. 하나씩 실행해 보세요.
1. 서론
산업 전반에서 고급 컴퓨터 비전 시스템에 대한 수요가 급증함에 따라 Vision Transformers의 배포는 연구자와 실무자에게 주요 관심사가 되었습니다. 하지만 이러한 모델의 잠재력을 최대한 실현하려면 아키텍처에 대한 깊은 이해가 필요합니다. 또한, 이러한 모델을 효과적으로 배포하기 위한 최적화 전략을 개발하는 것도 마찬가지로 중요합니다.
이 글에서는 Vision Transformer에 대한 개요를 제공하고, 아키텍처, 주요 구성 요소와 이를 독특하게 만드는 기본 사항을 자세히 살펴보겠습니다. 기사의 마지막 부분에서는 모델을 더 간결하게 만들어 배포를 용이하게 하는 몇 가지 최적화 전략과 코드 데모를 논의하겠습니다.
2. 비타민의 개요
ViT는 주로 이미지 분류와 객체 감지에 사용되는 특수한 유형의 신경망입니다. ViT의 정확도는 기존 CNN을 능가했으며, 이에 기여한 주요 요인은 Transformer 아키텍처를 기반으로 한다는 것입니다. 이 건축물은 지금 어떤 건축물인가?
2017년에 Vaswani et al. "당신에게 필요한 것은 주의뿐입니다"Transformer 신경망 아키텍처는 .에 소개되었습니다. 네트워크는 순환 신경망(RNN)과 매우 유사한 인코더 및 디코더 구조를 사용합니다. 이 모델에서는 입력에 대한 타임스탬프 개념이 없습니다. 모든 단어가 동시에 전달되고, 단어 임베딩도 동시에 결정됩니다.
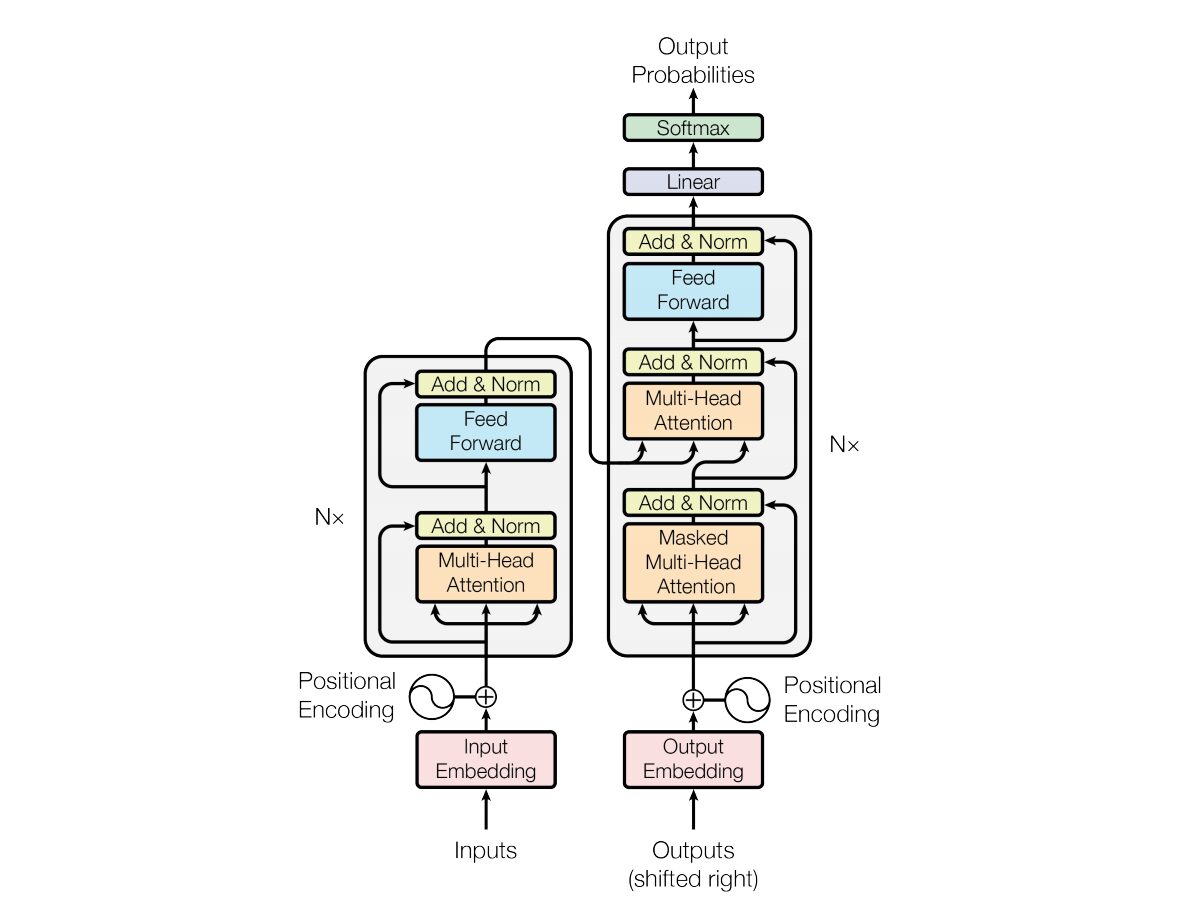
이러한 유형의 신경망 아키텍처는 셀프 어텐션이라는 메커니즘에 의존합니다.
다음은 Transformer 아키텍처의 핵심 구성 요소에 대한 간략한 설명입니다.
- 입력 임베딩: 입력 임베딩은 입력을 Transformer에 전달하는 첫 번째 단계입니다. 입력 임베딩은 입력 토큰이나 단어를 모델에 입력할 수 있는 고정 크기 벡터로 변환하는 프로세스를 말합니다. 이 임베딩 단계는 단어 간의 의미적 관계를 포착하는 방식으로 이산 토큰 표현을 연속 벡터 표현으로 변환하므로 매우 중요합니다. 이 임베딩 단계는 단어를 벡터에 매핑하지만, 같은 단어라도 문장마다 의미가 다를 수 있습니다. 여기서 위치 인코더가 등장합니다.
- 위치 인코딩: 변환기 자체는 시퀀스의 요소 순서를 이해하지 못하므로, 시퀀스에서 요소의 위치에 대한 정보를 모델에 제공하기 위해 입력 임베딩에 위치 인코딩이 추가됩니다. 간단히 말해서, 위치 임베딩은 문장에서 단어의 위치에 따라 맥락에 맞는 벡터를 제공합니다. 원래 논문에서는 이 벡터를 생성하기 위해 사인과 코사인 함수를 사용했습니다. 이 정보는 인코더 블록으로 전달됩니다.
- 인코더-디코더 구조: 트랜스포머는 주로 기계 번역과 같은 시퀀스-투-시퀀스 작업에 사용됩니다. 이는 인코더와 디코더로 구성됩니다. 인코더는 입력 시퀀스를 처리하고 디코더는 출력 시퀀스를 생성합니다.
- 멀티헤드 셀프 어텐션: 셀프 어텐션을 사용하면 모델이 예측을 할 때 입력 시퀀스의 각 부분에 다른 가중치를 부여할 수 있습니다. Transformer의 핵심 혁신은 여러 개의 어텐션 헤드를 사용한 것입니다. 이를 통해 모델이 입력의 다양한 측면에 동시에 집중할 수 있습니다. 각 주의 헤드는 다른 패턴에 초점을 맞추도록 훈련됩니다.
- 확장된 점곱 주의: 주의 메커니즘은 입력 시퀀스와 학습 가능한 가중치 벡터의 점곱을 구하여 주의 점수 세트를 계산합니다. 이러한 점수는 조정되어 소프트맥스 함수를 거쳐 주의 가중치를 얻습니다. 이러한 주의 가중치를 사용한 입력 시퀀스의 가중 합은 주의 메커니즘의 출력입니다.
- 피드포워드 신경망: 어텐션 계층 다음에, 각 인코더와 디코더 블록에는 일반적으로 ReLu와 같은 활성화 함수가 있는 피드포워드 신경망이 포함됩니다. 네트워크는 시퀀스의 각 위치에 독립적으로 적용됩니다.
- 레이어 정규화 및 잔여 연결: 레이어 정규화와 잔여 연결은 학습을 안정화하는 데 사용됩니다. 인코더와 디코더 모두의 각 하위 계층(주의 또는 피드포워드)에는 계층 정규화가 있으며, 각 하위 계층의 출력은 잔여 연결을 통해 전달됩니다.
- 인코더와 디코더 스택: 인코더와 디코더는 서로 위에 쌓인 여러 개의 동일한 레이어로 구성됩니다. 레이어의 수는 하이퍼파라미터입니다.
- 디코더의 마스크된 자기 주의: 학습 중에 디코더에서 자기 주의 메커니즘이 수정되어 향후 토큰에 주의를 기울이지 않습니다. 이는 각 위치가 바로 앞의 위치만 처리할 수 있도록 마스킹 기술을 사용하여 수행됩니다.
- 최종 선형 및 소프트맥스 계층: 디코더 스택의 출력은 최종 예측 확률로 변환되어(예: 선형 계층 다음에 소프트맥스 활성화를 사용) 출력 시퀀스를 생성합니다.
3. Vision Transformer 아키텍처 이해
CNN은 이미지 분류 작업에 가장 적합한 솔루션으로 여겨진다. 사전 학습 데이터 세트가 충분히 크다면 ViT는 이러한 작업에서 CNN보다 꾸준히 우수한 성능을 보입니다. ViT는 ImageNet에서 Transformer 인코더를 성공적으로 학습시켜 상당한 성공을 거두었으며, 잘 알려진 합성곱 아키텍처와 비교해도 인상적인 결과를 보여주었습니다.
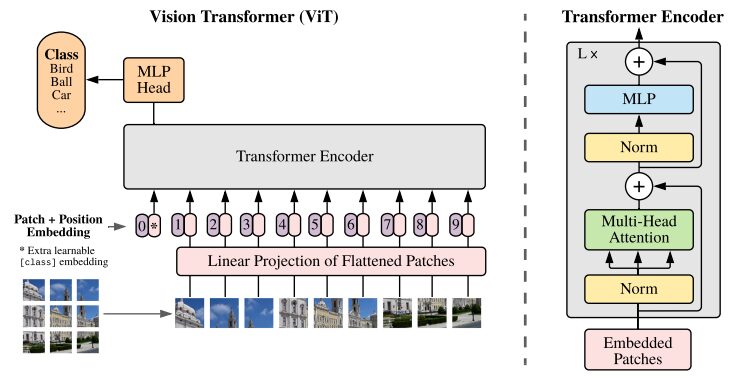
원래 연구 논문의 ViT 아키텍처 그림
변환기 모델은 일반적으로 인코더-디코더에 순차적으로 전달되는 이미지와 단어를 처리합니다. ViT에 대한 간단한 개요는 다음과 같습니다.
- 패치 추출: 이미지는 패치 시퀀스로 Transformer 인코더에 공급됩니다. 패치는 일반적으로 16×16픽셀 크기의 이미지의 작은 직사각형 부분입니다.

- 이미지를 겹치지 않는 블록(일반적으로 16×16 격자)으로 나눈 후, 각 블록을 해당 특징을 나타내는 벡터로 변환합니다. 이러한 특징은 일반적으로 이미지 분류에 필요한 중요한 특징을 식별하도록 훈련된 합성 신경망(CNN)을 활용하여 추출됩니다.
- 선형 임베딩: 추출된 패치는 평면 벡터에 선형적으로 임베딩됩니다. 이러한 벡터는 변환기에 대한 입력 시퀀스로 처리되며, 평평한 패치의 선형 투영으로도 알려져 있습니다.
- Transformer Encoder: 내장된 패치 벡터는 Transformer Encoder 레이어 스택을 통해 전달됩니다. 각 인코더 계층은 셀프 어텐션 메커니즘과 피드포워드 신경망으로 구성됩니다.
- 셀프 어텐션 메커니즘: 셀프 어텐션 메커니즘을 통해 모델은 이미지의 다양한 패치 간의 관계를 포착하여 장거리 종속성과 관계를 학습할 수 있습니다. Transformer의 주의 메커니즘을 통해 모델은 로컬 및 글로벌 컨텍스트 정보를 모두 포착하여 다양한 비전 작업을 효과적으로 수행할 수 있습니다.
- 위치 인코딩: 변환기 자체는 패치 간의 공간적 관계를 이해하지 못하므로, 원본 이미지에서 패치의 위치에 대한 정보를 제공하기 위해 입력 임베딩에 위치 인코딩이 추가됩니다.
- 다중 인코더 레이어: ViT는 일반적으로 다중 Transformer 인코더 레이어를 사용하여 입력 이미지에서 계층적이고 추상적인 특징을 캡처합니다.
- 전역 평균 풀링: Transformer 인코더의 출력은 일반적으로 전역 평균 풀링을 거치는데, 이는 다양한 패치의 정보를 고정 크기 표현으로 집계합니다.
- 분류 헤드: 병합된 표현은 분류 헤드(일반적으로 하나 이상의 완전히 연결된 레이어로 구성됨)에 입력되어 특정 컴퓨터 비전 작업(예: 이미지 분류)에 대한 최종 출력을 생성합니다.
원본을 꼭 보시기를 권장합니다.연구 논문ViT 아키텍처를 더 깊이 이해하려면 다음을 참조하세요.
4. 사용 방법
다음 코드는 모두 pre_ViT.ipynb에서 접근하여 실행할 수 있습니다! ! ! !
4.1 사전 학습된 ViT 모델을 사용하여 이미지 분류
사전 학습된 ViT 모델은 1,400만 개의 이미지와 21,000개의 카테고리를 갖춘 유명한 ImageNet-21k 데이터 세트를 사용하여 사전 학습되고, 100만 개의 이미지와 1,000개의 카테고리를 갖춘 ImageNet 데이터 세트로 미세 조정됩니다.
데모:
- 처음 플랫폼을 시작하면 다음 두 라이브러리가 없습니다. pip를 사용하여 종속성을 설치합니다. pip를 사용하여 종속성을 설치할 때 추가 매개변수 --user를 추가합니다. 그러면 설치된 종속성이 컨테이너의 작업 공간에 저장되고 다음에 다시 시작할 때 무효화되지 않습니다.
!pip install --user -q transformers timm- Transformer 라이브러리에서 필요한 클래스를 가져옵니다. ViTFeatureExtractor는 이미지에서 특징을 추출하는 데 사용되고, ViTForImageClassification은 이미지 분류를 위한 사전 학습된 ViT 모델입니다.
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image as img
from IPython.display import Image, display
FILE_NAME = '/notebooks/football-1419954_640.jpg'
display(Image(FILE_NAME, width = 700, height = 400))
#预测图片的地址
image_path = "./pic/football.jpg"
image_array = img.open(image_path)
#Vit 模型地址
vision_encoder_decoder_model_name_or_path = "./my_model/"
#加载 ViT 特征转化 and 预训练模型
#feature_extractor = ViTFeatureExtractor.from_pretrained(vision_encoder_decoder_model_name_or_path)
#model = ViTForImageClassification.from_pretrained(vision_encoder_decoder_model_name_or_path)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')
#使用 Vit 特征提取器处理输入图像,专为 ViT 模型的格式
inputs = feature_extractor(images = image_array,
return_tensors="pt")
#预训练模型处理输入并生成输出 logits,代表模型对不同类别的预测。
outputs = model(**inputs)
#创建一个变量来存储预测类的索引。
logits = outputs.logits
# 查找具有最高 Logit 分数的类的索引
predicted_class_idx = logits.argmax(-1).item()
print(predicted_class_idx)
#805
print("Predicted class:", model.config.id2label[predicted_class_idx])
#预测种类:足球코드 분석:
- ViTFeatureExtractor.from_pretrained: 입력 이미지를 ViT 모델에 적합한 형식으로 변환하는 역할을 합니다.
- ViTForImageClassification.from_pretrained: 이미지 분류를 위해 사전 학습된 ViT 모델을 로드합니다.
- feature_extractor: ViT 기능 추출기를 사용하여 입력 이미지를 처리하고 ViT 모델에 적합한 형식으로 변환합니다.
- 모델: 사전 학습된 모델은 입력을 처리하고 다양한 범주에 대한 모델의 예측을 나타내는 출력 로짓을 생성합니다. 다음 단계는 로짓 점수가 가장 높은 클래스의 인덱스를 찾는 것입니다. 예측된 클래스의 인덱스를 저장할 변수를 만듭니다.
- model.config.id2label[predicted_class_idx]: 예측된 클래스 인덱스를 해당 레이블에 매핑합니다.
4.2 DeiT를 사용한 이미지 분류
DeiT는 제한된 데이터 가용성과 리소스가 있는 경우에도 컴퓨터 비전 작업에 Transformers를 성공적으로 적용하는 방법을 보여줍니다.
from PIL import Image
import torch
import timm
import requests
import torchvision.transforms as transforms
from timm.data.constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
print(torch.__version__)
# should be 1.8.0
#从 DeiT 存储库加载名为 “deit_base_patch16_224” 的预训练 DeiT 模型。
model = torch.hub.load('facebookresearch/deit:main', 'deit_base_patch16_224', pretrained=True)
#将模型设置为评估模式,这在使用预训练模型进行推理时非常重要。
model.eval()
#定义一系列应用于图像的变换。例如调整大小、中心裁剪、将图像转换为 PyTorch 张量、使用 ImageNet 数据常用的平均值和标准差值对图像进行归一化。
transform = transforms.Compose([
transforms.Resize(256, interpolation=3),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD),
])
#从 URL 下载图像并对其进行转换。或者直接从本地上传
#Image.open(requests.get("https://images.rawpixel.com/image_png_800/czNmcy1wcml2YXRlL3Jhd3BpeGVsX2ltYWdlcy93ZWJzaXRlX2NvbnRlbnQvcHUyMzMxNjM2LWltYWdlLTAxLXJtNTAzXzMtbDBqOXFrNnEucG5n.png", stream=True).raw)
img = Image.open("./pic/football.jpg")
#None 模拟大小为 1 的批次
img = transform(img)[None,]
#模型的推理、预测
out = model(img)
clsidx = torch.argmax(out)
#打印预测类别的索引。
print(clsidx.item())코드 분석:
- 라이브러리 설치: 가장 먼저 필요한 단계는 필요한 라이브러리를 설치하는 것입니다. 더 잘 이해하기 위해 사용자 여러분께서 이 라이브러리를 공부하실 것을 강력히 권장합니다.
- 사전 학습된 모델 로드:: model=torch.hub.load('facebookresearch/deit:main', 'deit_base_patch16_224', pretrained=True)는 DeiT 저장소에서 'deit_base_patch16_224'라는 사전 학습된 DeiT 모델을 로드합니다.
- 모델을 평가 모드로 설정합니다. model.eval(): 추론을 위해 사전 학습된 모델을 사용할 때 매우 중요한 평가 모드로 모델을 설정합니다.
- 이미지 변환: 이미지에 적용할 일련의 변환을 정의합니다. 예를 들어, 이미지 크기 조절, 중앙 자르기, 이미지를 PyTorch 텐서로 변환, ImageNet 데이터에서 일반적으로 사용되는 평균 및 표준 편차 값을 사용하여 이미지 정규화 등이 있습니다. 이미지 다운로드 및 변환: 다음 단계에서는 URL에서 이미지를 다운로드하고 변환합니다. 인수 [None,]을 추가하면 크기 1의 배치를 시뮬레이션하기 위한 차원이 추가됩니다.
- 모델 추론 및 예측: out = model(img)를 사용하면 전처리된 이미지를 DeiT 모델을 통해 추론할 수 있습니다. clsidx = torch.argmax(out)은 가장 높은 확률을 갖는 클래스의 인덱스를 찾습니다. 다음으로, 예측된 클래스의 인덱스를 인쇄합니다.
4.3 양자화 모델
모델 크기를 줄이려면 양자화가 적용됩니다. 이 과정을 통해 모델의 정확도를 떨어뜨리지 않고 크기를 줄일 수 있습니다.
#将量化后端指定为 “qnnpack” 。 QNNPACK(Quantized Neural Network PACKage)是 Facebook 开发的低精度量化神经网络推理库
backend = "qnnpack"
model.qconfig = torch.quantization.get_default_qconfig(backend)
torch.backends.quantized.engine = backend
#推理过程中量化模型的权重,并 qconfig_spec 指定量化应仅应用于线性(全连接)层。使用的量化数据类型是 torch.qint8(8 位整数量化)
quantized_model = torch.quantization.quantize_dynamic(model, qconfig_spec={torch.nn.Linear}, dtype=torch.qint8)
scripted_quantized_model = torch.jit.script(quantized_model)
#模型保存到名为 “fbdeit_scripted_quantized.pt” 的文件
scripted_quantized_model.save("fbdeit_scripted_quantized.pt")코드 분석:
- torch.quantization.quantize_dynamic(모델, qconfig_spec={torch.nn.Linear}, dtype=torch.qint8)
- qconfig_spec은 양자화가 선형(완전히 연결됨) 계층에만 적용되어야 함을 지정합니다. 사용되는 양자화 데이터 유형은 torch.qint8(8비트 정수 양자화)입니다.
4.4 최적화 모델
optimize_for_mobile 함수는 모바일 배포에 맞게 특별히 최적화하고 최적화된 모델을 파일로 저장합니다.
from torch.utils.mobile_optimizer import optimize_for_mobile
optimized_scripted_quantized_model = optimize_for_mobile(scripted_quantized_model)
optimized_scripted_quantized_model.save("fbdeit_optimized_scripted_quantized.pt")
# 使用优化模型进行预测
out = optimized_scripted_quantized_model(img)
clsidx = torch.argmax(out)
print(clsidx.item())4.5 라이트 버전
이는 PyTorch Lite를 지원하는 모바일 또는 에지 디바이스에 모델을 배포하여 해당 디바이스의 런타임 환경의 호환성과 효율성을 보장하는 데 중요합니다.
optimized_scripted_quantized_model._save_for_lite_interpreter("fbdeit_optimized_scripted_quantized_lite.ptl")
ptl = torch.jit.load("fbdeit_optimized_scripted_quantized_lite.ptl")4.6 추론 속도 비교
다양한 모델 변형의 추론 속도를 비교하려면 제공된 코드를 실행하세요.
with torch.autograd.profiler.profile(use_cuda=False) as prof1:
out = model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof2:
out = scripted_quantized_model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof3:
out = optimized_scripted_quantized_model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof4:
out = ptl(img)
print("original model: {:.2f}ms".format(prof1.self_cpu_time_total/1000))
print("scripted & quantized model: {:.2f}ms".format(prof2.self_cpu_time_total/1000))
print("scripted & quantized & optimized model: {:.2f}ms".format(prof3.self_cpu_time_total/1000))
print("lite model: {:.2f}ms".format(prof4.self_cpu_time_total/1000))
위의 모든 코드는 pre_ViT.ipynb에서 접근하여 실행할 수 있습니다! ! ! !
결론 및 생각
이 문서에서는 Visual Converter를 시작하고 Paperspace 콘솔을 사용하여 모델을 탐색하는 데 필요한 모든 내용을 다루었습니다. 우리는 이 모델의 중요한 응용 분야 중 하나인 이미지 인식을 살펴보았습니다. ViT를 비교하고 더 쉽게 해석하기 위해 Transformer 아키텍처도 포함했습니다.
Vision Transformer 논문에서는 CNN에 대한 대안으로 유망하고 간단한 모델을 소개합니다. ILSVRC의 ImageNet과 그 슈퍼셋인 ImageNet-21M으로 사전 학습된 이 모델은 Oxford-IIIT Pets, Oxford Flowers, Google Brain의 JFT-300M을 비롯한 인기 있는 이미지 분류 데이터 세트에서 최첨단 벤치마크를 달성했습니다.
요약하자면, Vision Transformers(ViTs)와 DeiT는 컴퓨터 비전 분야에서 중요한 발전을 이루었습니다. ViT는 주의 기반 아키텍처를 통해 이미지 이해를 위한 Transformer 모델의 효율성을 입증하여 기존의 합성곱 방식에 도전했습니다.
특히 DeiT는 지식 정제를 도입하여 ViT가 직면한 과제를 더욱 해결합니다. 교사-학생 교육 패러다임을 활용하여 DeiT는 훨씬 적은 레이블이 지정된 데이터로 경쟁력 있는 성과를 달성할 수 있는 잠재력을 보여주며, 대규모 데이터 세트를 쉽게 사용할 수 없는 시나리오에서 귀중한 솔루션이 됩니다.
이 분야의 연구가 계속 발전함에 따라, 이러한 혁신은 더욱 효율적이고 강력한 모델을 위한 길을 열어주고 있으며, 컴퓨터 비전 애플리케이션의 미래에 대한 흥미로운 가능성을 열어주고 있습니다.