Command Palette
Search for a command to run...
GPT-SoVITS 오디오 합성 온라인 데모
1. 기능 설명
참고: 제가 만든 원클릭 트레이닝은 현재 중국어만 지원합니다. 일본어나 영어를 학습하려면 Webui를 활성화해야 합니다.
방법은 run.ipynb 실행 코드에서 python run_all.py를 python webui.py로 변경하는 것입니다.
2. 비디오 튜토리얼
https://www.bilibili.com/video/BV1WC411W79t
3. 작동 방법
1. run.ipynb를 엽니다.
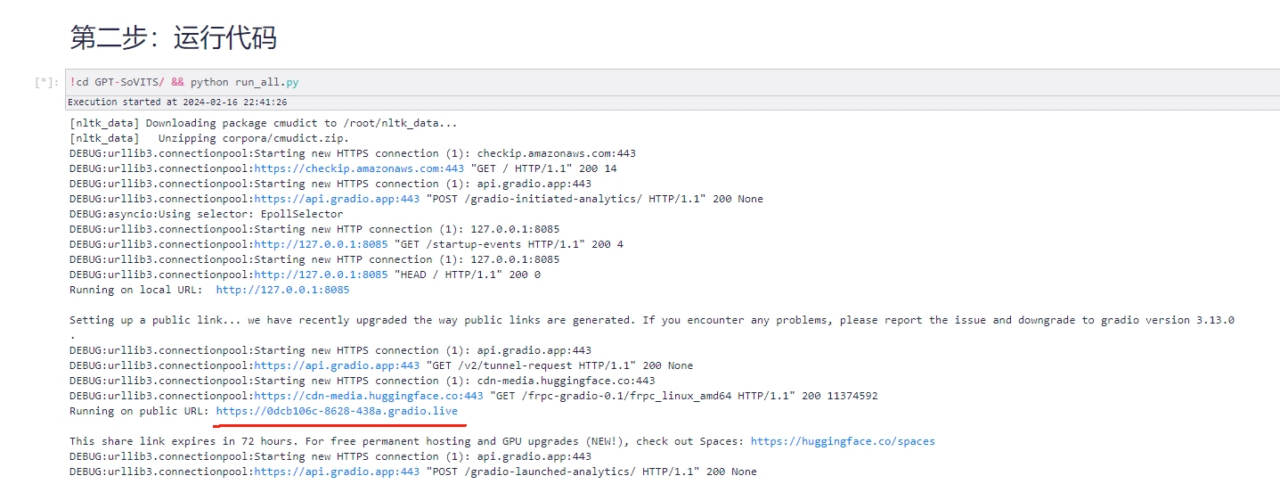
실행 -> 모든 셀 실행을 클릭하면 프로그램이 시작되고, 환경이 자동으로 구성되고, 서비스가 시작됩니다.

2. 출력 공개 URL을 엽니다.
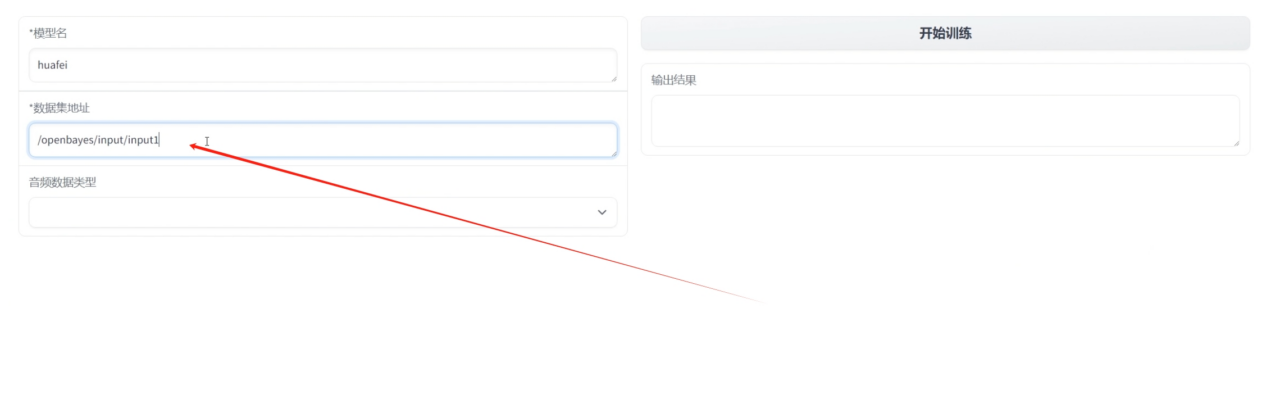
3. 오디오에 맞는 데이터 유형을 선택하세요

4. 교육을 시작하려면 클릭하세요
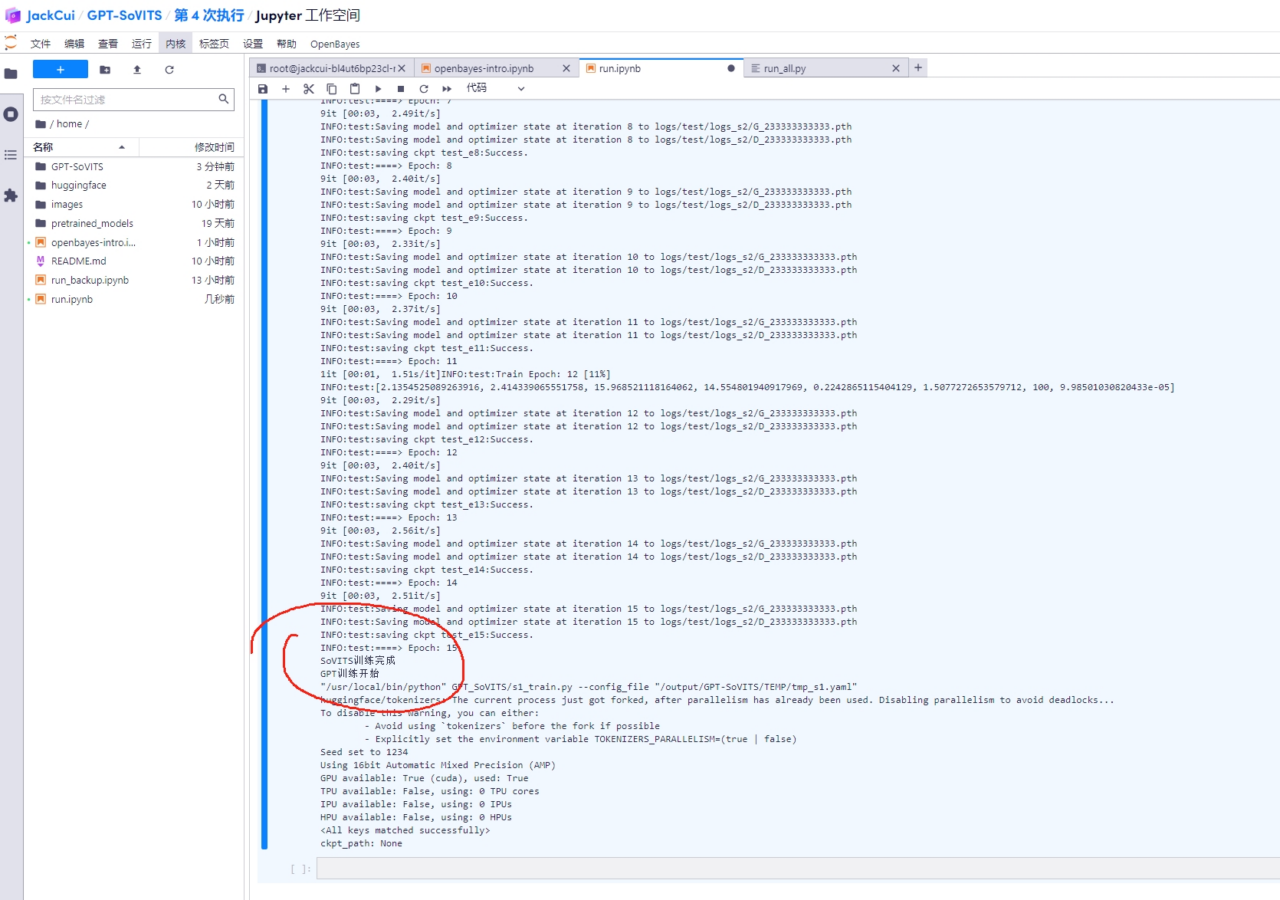
포그라운드에서 프로세스가 어느 단계에 도달했는지 보려면 클릭하고, 백그라운드에서 로그 출력도 볼 수 있습니다.

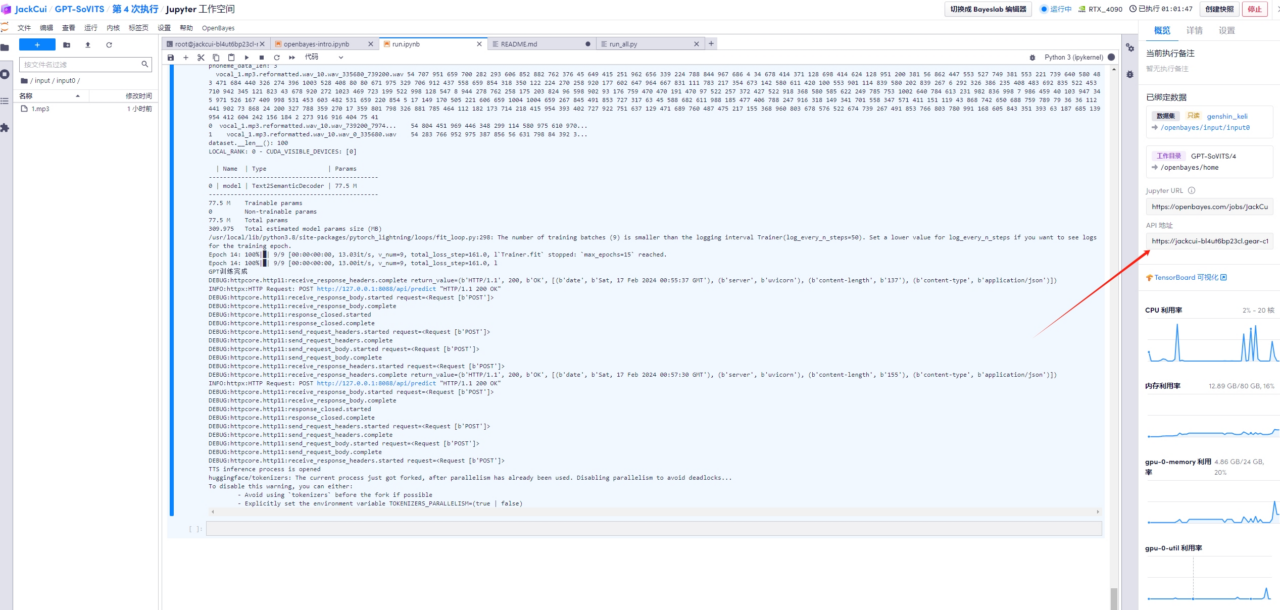
5. API 주소를 엽니다
프런트 엔드에서 예측이 켜졌다고 표시되는 경우

오픈 API 주소:
6. 음성 복제
훈련된 모델을 선택하고, 텍스트를 입력하고, 즐기세요.
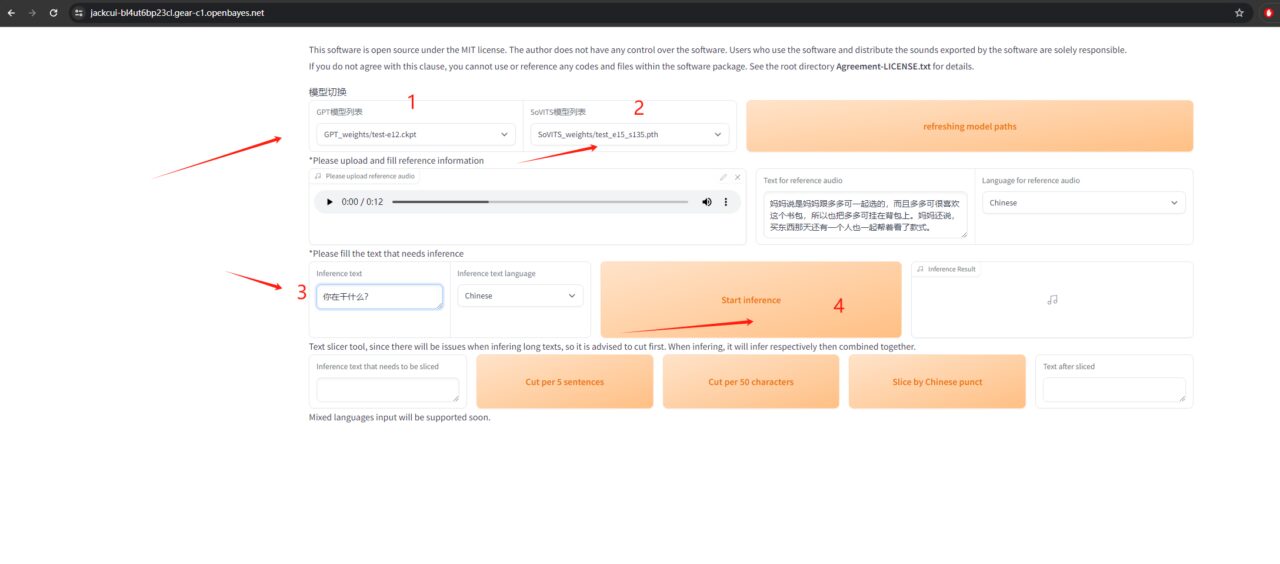
4. 사용자 정의 오디오
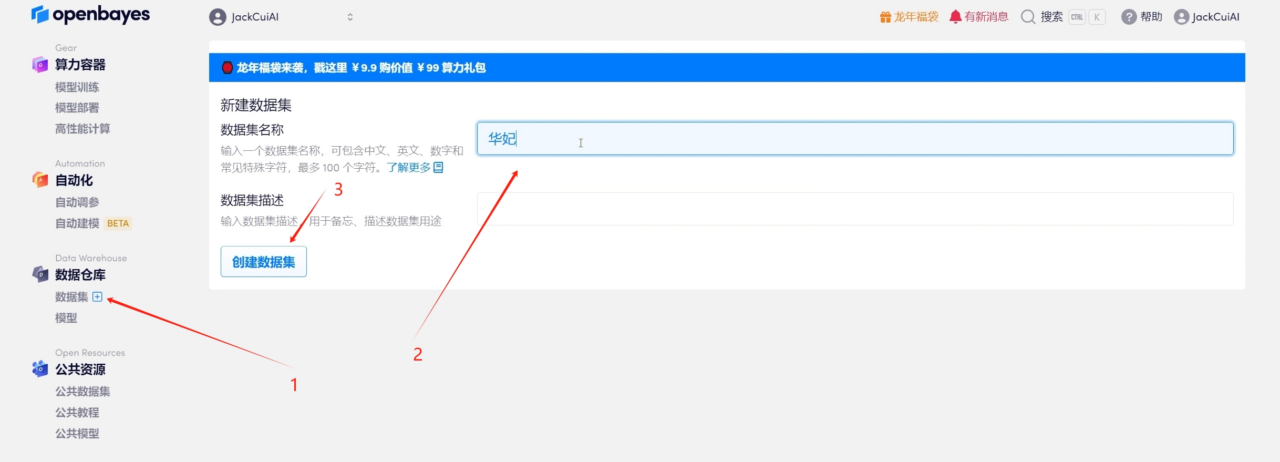
1. 데이터 세트를 찾고 새로운 데이터 세트를 만듭니다.
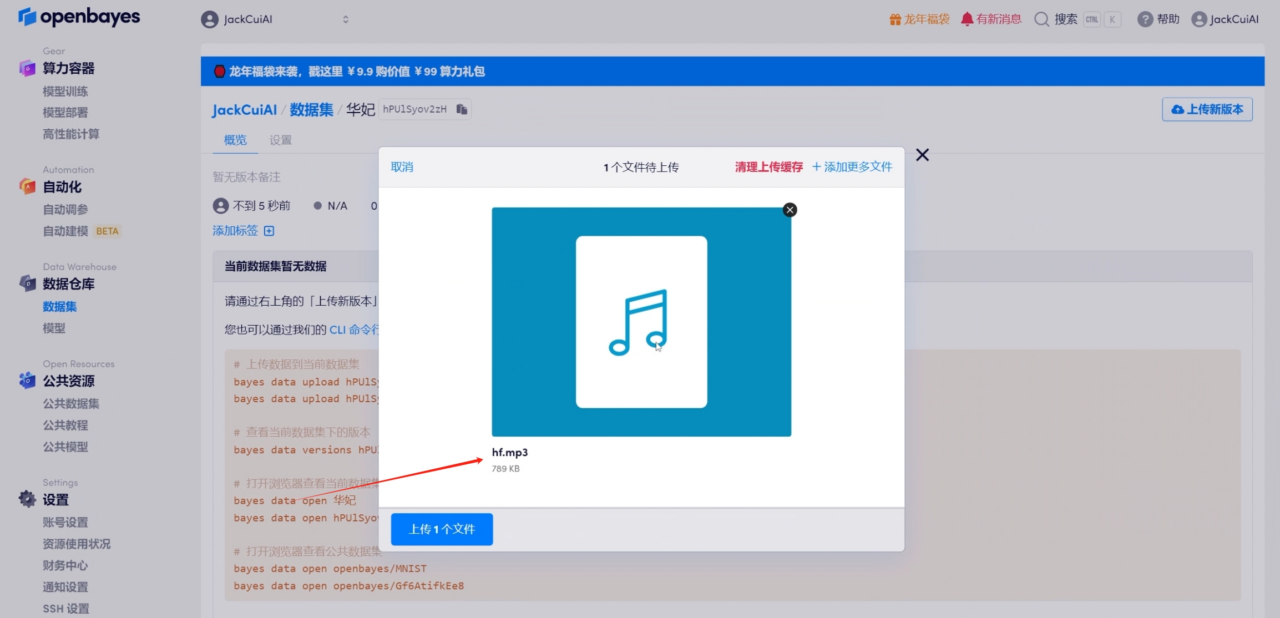
2. 오디오 데이터 업로드
3. 구성을 수정하고 시작하세요.
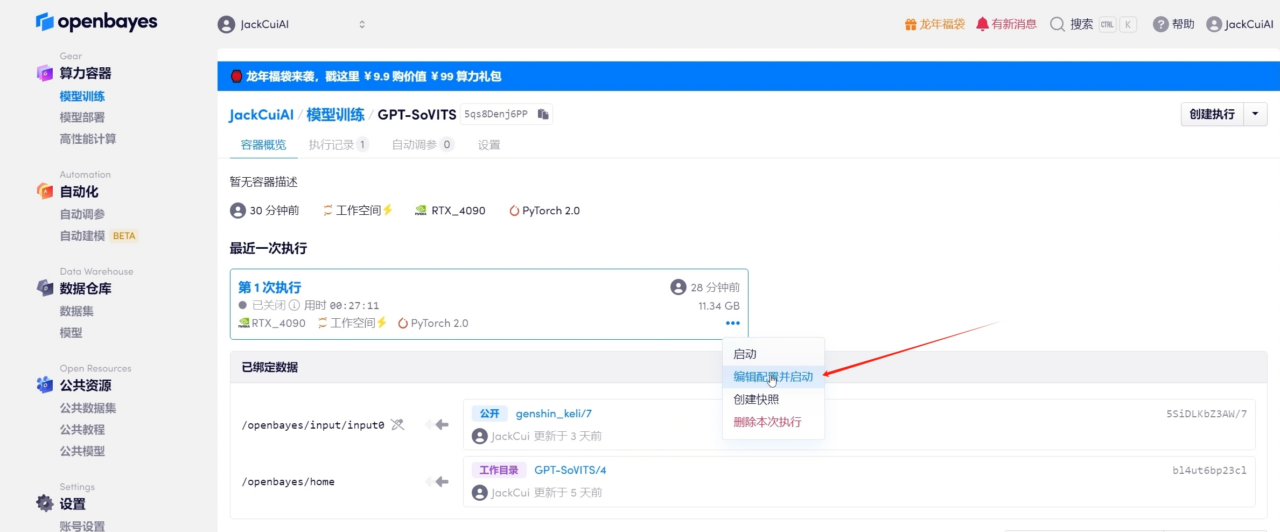
4. 새로운 입력 주소 바인딩
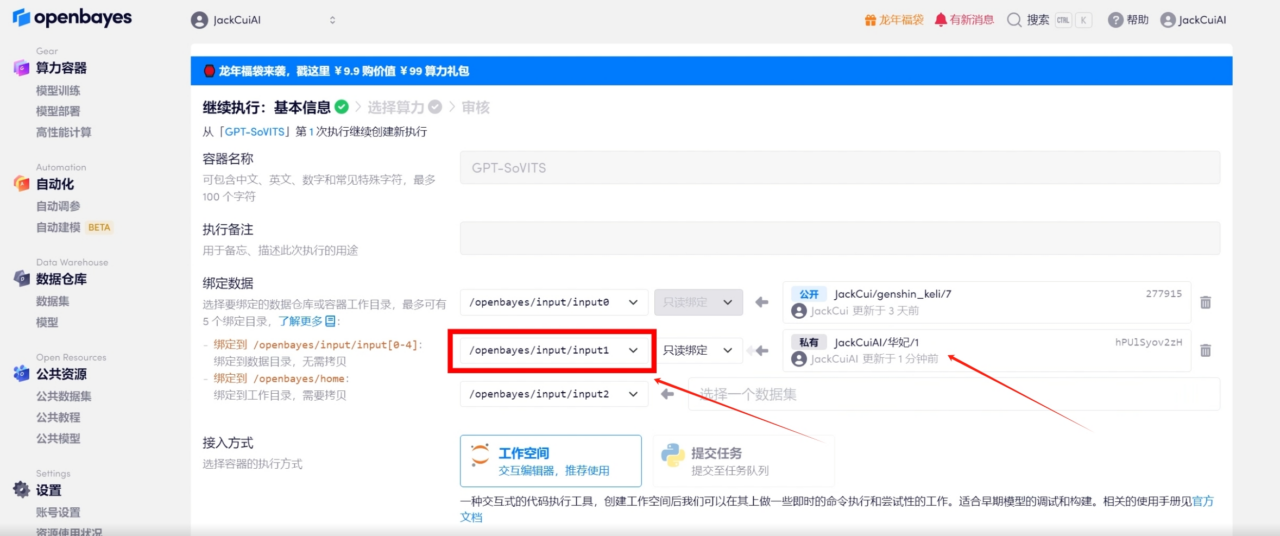
5. 작업공간을 엽니다
이렇게 하면 오른쪽 사이드바에서 새로 바인딩된 데이터 세트를 볼 수 있습니다.
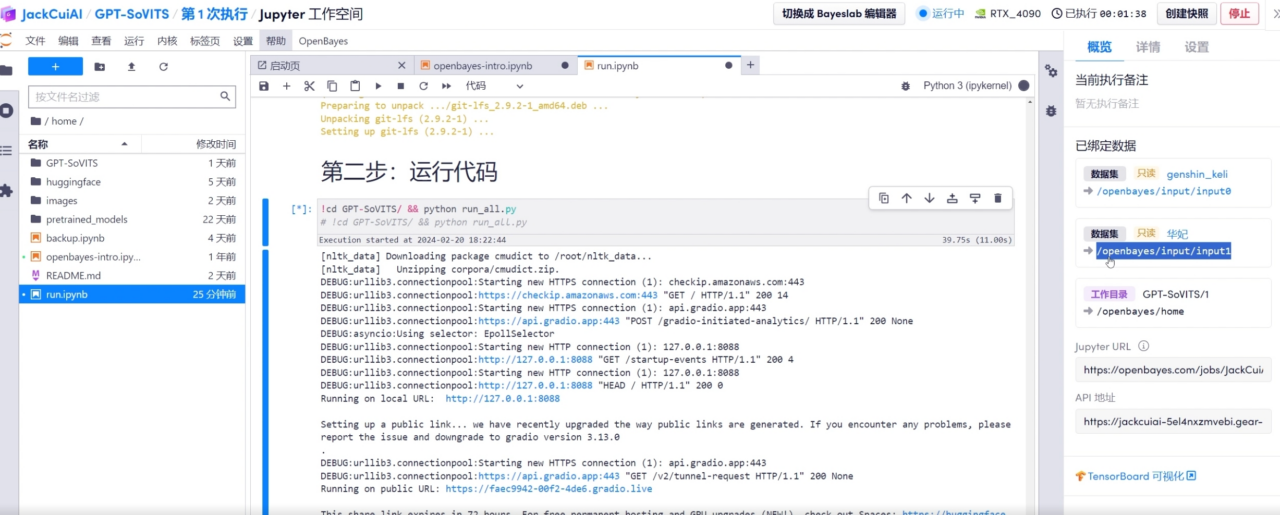
6. 새로 묶은 주소를 채우는 훈련