Command Palette
Search for a command to run...
사용자 정의 데이터로 YOLOv8 학습
이 튜토리얼에서는 Ultralytics의 새로운 모델인 YOLOv8의 새로운 기능을 살펴보고, YOLOv5와 비교하여 아키텍처 변경 사항을 자세히 살펴보고, 농구 데이터셋에서 Python API 기능을 사용하여 탐지 기능을 테스트하여 새로운 모델을 시연합니다. YOLOv8의 주요 원리를 다루고, 데이터셋을 생성하고 레이블을 지정하며, 모델을 학습시키고, 모든 수신 비디오 파일이나 스트림에 적용하는 방법을 보여줍니다.
객체 감지는 AI 기술의 가장 인기 있고 간단한 사용 사례 중 하나로 남아 있습니다. Joseph Redman 등의 획기적인 작업으로 첫 번째 버전이 출시된 이후, 2016년 "You Only Look Once: Unified, Real-Time Object Detection"에서 YOLO 모델 계열이 이러한 추세를 선도해 왔습니다. 이러한 객체 감지 모델은 DL 모델을 사용하여 이미지에서 실시간 엔터티 주체 및 위치 인식을 수행하는 방법을 연구하는 길을 열었습니다.
이 글에서는 이러한 기술의 기본을 다시 살펴보고, Ultralytics의 최신 버전인 YOLOv8의 새로운 기능을 논의하며, RoboFlow와 Paperspace Gradient, 새로운 Ultralytics API를 사용하여 사용자 지정 YOLOv8 모델을 미세 조정하는 단계를 살펴보겠습니다. 이 튜토리얼을 마치면 사용자는 레이블이 지정된 이미지 세트에 YOLOv8 모델을 빠르고 쉽게 적용할 수 있게 됩니다.
YOLO는 어떻게 작동하나요?
먼저, YOLO의 기본 작동 원리에 대해 살펴보겠습니다. 다음은 모델의 기능 합계를 분석한 원래 YOLO 논문의 짧은 인용문입니다.
단일 합성곱 신경망은 여러 개의 경계 상자와 해당 상자의 클래스 확률을 동시에 예측합니다. YOLO는 전체 이미지를 학습하고 탐지 성능을 최적화합니다. 이 통합 모델은 기존 객체 탐지 방식보다 여러 가지 장점을 제공합니다.
앞서 언급했듯이, 이 모델은 이러한 특징에 대한 훈련을 받았으므로 이미지에서 여러 개체의 위치를 예측하고 해당 개체를 식별할 수 있습니다. 이 작업은 이미지를 크기가 s*s인 N개의 격자로 나누어 단일 단계로 수행합니다. 이러한 지역은 동시에 구문 분석되어 그 안에 포함된 모든 객체를 감지하고 지역화합니다. 그런 다음 모델은 각 그리드 셀의 경계 상자 좌표 B를 예측하고 여기에 포함된 객체의 레이블과 예측 점수를 예측합니다.
이 모든 것을 종합하면 객체 분류, 객체 감지, 이미지 분할 작업을 수행할 수 있는 기술을 얻을 수 있습니다. YOLO의 기본 기술은 동일하므로 YOLOv8에서도 작동할 것으로 예상됩니다. YOLO의 작동 방식에 대한 자세한 내용은 YOLOv5 및 YOLOv7에 대한 이전 게시물, YOLOv6 및 YOLOv7 벤치마크 결과, 그리고 YOLO 논문 원본을 참조하세요.
YOLOv8의 새로운 기능은 무엇인가요?
YOLOv8이 출시된 지 얼마 안 되었기 때문에 이 모델을 다룬 논문은 아직 나오지 않았습니다. 저자는 곧 출시할 예정이지만, 지금으로서는 공식 출시 게시물을 확인하고 커밋 내역에서 변경 사항을 추론한 뒤, YOLOv5와 YOLOv8 사이의 변경 범위를 직접 확인하는 수밖에 없습니다.
~에 따르면공식 출시YOLOv8은 새로운 백본 네트워크, 앵커 없는 검출 헤드 및 손실 함수를 채택했습니다. Github 사용자 RangeKing은 업데이트된 모델 백본과 헤드 구조를 보여주는 YOLOv8 모델 인프라에 대한 개요를 공유했습니다. 이 수치를 다음과 비교해보면 YOLOv5 RangeKing의 유사한 검사와 비교게시물다음 변경 사항이 확인되었습니다.

C2f 모듈, 이미지 출처: RoboFlow (원천)- 그들은 사용합니다
C2f모듈 교체됨C3기준 치수. 존재하다C2f에서, 에서Bottleneck(잔여 연결이 있는 3×3 2개convs)는 서로 연결되어 있지만,C3마지막 하나만 사용됩니다Bottleneck산출. (원천)

- 그들은
Backbone하나를 사용하세요3x3 Conv블록은 첫 번째를 대체합니다6x6 Conv - 그들은 두 개를 삭제했습니다
Conv(YOLOv5 구성에서는 10번째와 14번째)

- 그들은
Bottleneck하나를 사용하세요3x3 Conv첫 번째를 교체했습니다1x1 Conv - 그들은 분리된 헤더로 전환하고 제거했습니다.
objectness가지
YOLOv8 논문이 발표되면 다시 확인해 주세요. 이 섹션에 더 많은 정보를 업데이트하겠습니다. 위의 변경 사항에 대한 자세한 분석을 보려면 RoboFlow 문서를 확인하십시오. YOLOv8 풀어 주다.
접근성
Github 저장소를 복제하고 환경을 수동으로 설정하는 기존 방식 외에도 사용자는 이제 새로운 Ultralytics API를 사용하여 YOLOv8에 액세스하여 학습 및 추론을 수행할 수 있습니다. 아래를 참조하세요 모델 학습 API 설정에 대한 자세한 내용은 섹션을 참조하세요.
앵커 경계 상자 없음
Ultralytics 파트너인 RoboFlow의 블로그 게시물에 따르면 YOLOv8YOLOv8에는 이제 앵커 없는 경계 상자가 있습니다. YOLO의 초기 버전에서는 사용자가 객체 감지 프로세스를 용이하게 하기 위해 이러한 앵커 상자를 수동으로 식별해야 했습니다. 이러한 사전 정의된 경계 상자는 미리 정해진 크기와 높이를 가지고 있으며, 데이터 세트의 특정 객체 범주의 크기와 종횡비를 포착합니다. 이러한 경계에서 예측된 객체까지의 오프셋은 모델이 객체의 위치를 더 잘 식별하는 데 도움이 됩니다.
YOLOv8에서는 이러한 앵커 상자가 자동으로 객체의 중심에 예측됩니다.
훈련이 끝나기 전에 모자이크 증강을 중단하세요
YOLOv8은 학습의 각 에포크마다 제공된 이미지의 약간 다른 버전을 봅니다. 이런 변화를 향상이라고 합니다. 그 중 하나,모자이크 강화, 4개의 이미지를 결합하여 모델이 주변 픽셀의 변화가 더 큰 가려짐으로 인해 서로 부분적으로 차단된 새로운 위치에서 객체의 정체성을 학습하도록 하는 프로세스입니다. 훈련 내내 이러한 증강을 사용하면 예측 정확도에 부정적인 영향을 미칠 수 있다는 사실이 밝혀졌으므로, YOLOv8은 훈련의 마지막 몇 에포크 동안 이 프로세스를 중단할 수 있습니다. 이를 통해 전체 실행으로 확장하지 않고도 최적의 학습 모델을 실행할 수 있습니다.
효율성과 정확성
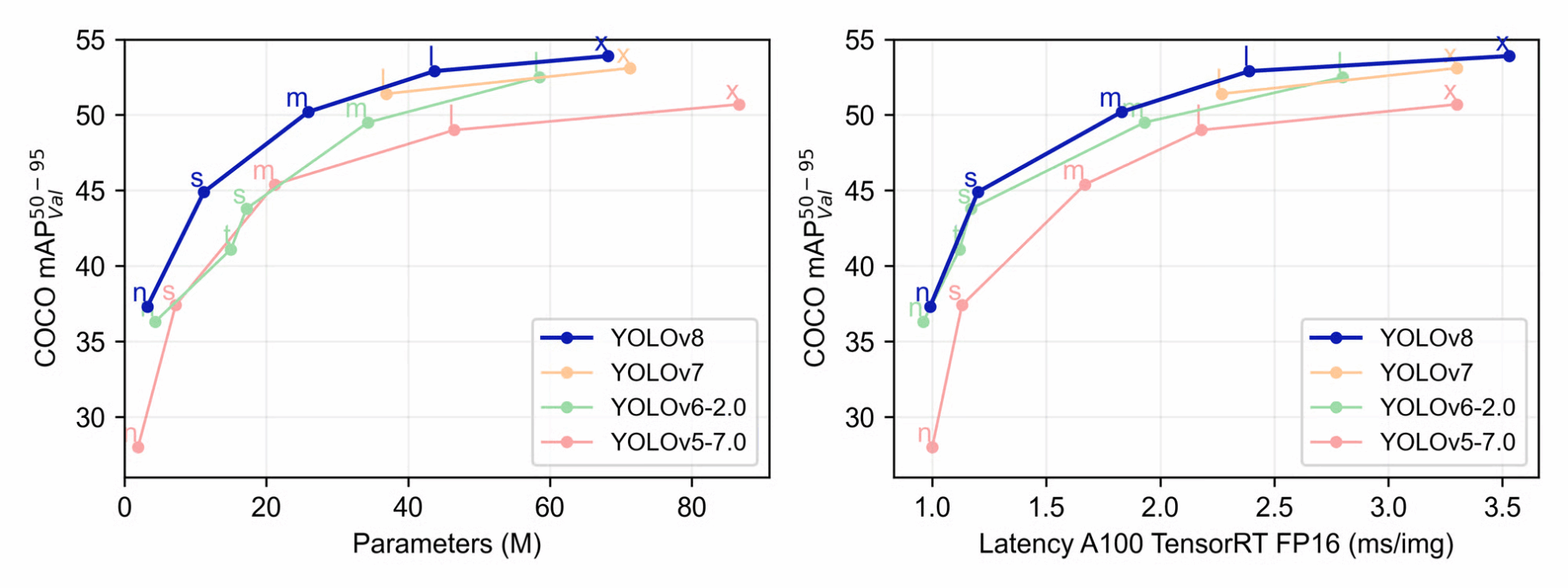
여기서 우리가 주목하는 주된 목적은 추론과 학습 과정에서 성능의 정확도와 효율성을 개선하는 것입니다. Ultralytics의 저자는 YOLO의 새로운 버전을 다른 버전과 비교하는 데 사용할 수 있는 유용한 샘플 데이터를 제공했습니다. 위 차트에서 볼 수 있듯이, 학습 과정에서 YOLOv8은 평균 정밀도, 크기, 지연 시간 측면에서 YOLOv7, YOLOv6-2.0, YOLOv5-7.0보다 우수한 성능을 보입니다.

각각의 Github 페이지에서 다양한 크기의 YOLOv8 모델에 대한 통계적 비교 표를 찾을 수 있습니다. 위의 표에서 볼 수 있듯이 매개변수의 크기, 속도, FLOP가 커질수록 mAP도 커집니다. 가장 큰 YOLOv5 모델인 YOLOv5x의 최대 mAP 값은 50.7입니다. mAP 값이 2.2단위 증가했다는 것은 역량 면에서 상당한 개선을 의미합니다. 이러한 결과는 모든 모델 크기에 적용되며, 아래에 표시된 것처럼 새로운 YOLOv8 모델이 YOLOv5보다 지속적으로 우수한 성능을 보입니다.

전반적으로 YOLOv8은 YOLOv5 및 기타 경쟁 프레임워크보다 상당히 발전된 것으로 볼 수 있습니다.
YOLOv8 미세 조정
튜토리얼을 실행하려면:OpenBayes에서 온라인 달리기를 시작하세요
YOLOv8 모델을 미세 조정하는 과정은 데이터 세트 생성 및 레이블 지정, 모델 학습, 모델 배포의 세 단계로 나눌 수 있습니다. 이 튜토리얼에서는 처음 두 단계를 자세히 살펴보고, 모든 수신 비디오 파일이나 스트림에 새 모델을 사용하는 방법을 보여드리겠습니다.
데이터 세트 설정
두 모델을 비교하는 데 사용했던 YOLOv7 실험을 다시 만들어서 Roboflow의 농구 데이터셋으로 돌아가겠습니다. 데이터셋을 설정하고, 레이블을 지정하고, RoboFlow에서 노트북으로 가져오는 방법에 대한 자세한 내용은 이전 글의 "커스텀 데이터셋 설정" 섹션을 참조하세요.
이전에 만든 데이터 세트를 사용하고 있으므로 이제는 데이터를 가져오기만 하면 됩니다. 아래는 Notebook 환경으로 데이터를 가져오는 데 사용되는 명령입니다. 자신의 레이블이 지정된 데이터 세트의 경우 동일한 프로세스를 사용하지만 작업 공간 및 프로젝트 값을 자신의 값으로 바꿔서 동일한 방식으로 데이터 세트에 액세스합니다.
아래 스크립트를 사용하여 노트북의 데모를 따라가려면 API 키를 자신의 키로 변경해야 합니다.
!pip install roboflow
from roboflow import Roboflow
rf = Roboflow(api_key="")
project = rf.workspace("james-skelton").project("ballhandler-basketball")
dataset = project.version(11).download("yolov8")
!mkdir datasets
!mv ballhandler-basketball-11/ datasets/모델 학습
새로운 Python API를 사용하면 다음을 사용할 수 있습니다. ultralytics 라이브러리는 Gradient Notebook 환경에서 모든 작업을 쉽게 수행합니다. 제공된 구성과 가중치를 사용하여 처음부터 빌드합니다. YOLOv8n 모델. 그런 다음 방금 환경에 로드한 데이터 세트를 사용합니다. model.train() 방법을 세부적으로 조정합니다.
from ultralytics import YOLO
# 加载模型
model = YOLO("yolov8n.yaml") # 从头构建新模型
model = YOLO("yolov8n.pt") # 加载预训练模型(建议用于训练)
# 使用模型
results = model.train(data="datasets/ballhandler-basketball-11/data.yaml", epochs=10) # 训练模型모델 테스트
results = model.val() # 在验证集上评估模型性能우리는 사용할 수 있습니다 model.val() 方法 검증 세트에서 평가할 새 모델을 설정합니다. 이렇게 하면 모델의 성능이 얼마나 좋은지 보여주는 표가 출력 창에 표시됩니다. 여기서는 10개의 에포크만 훈련했기 때문에 비교적 낮은 mAP 50-95는 예상된 결과입니다.

그 다음부터는 사진을 제출하는 게 간단합니다. 경계 상자에 대한 예측을 출력하고, 해당 상자를 이미지 위에 겹쳐서 "runs/detect/predict" 폴더에 업로드합니다.
from ultralytics import YOLO
from PIL import Image
import cv2
# from PIL
im1 = Image.open("assets/samp.jpeg")
results = model.predict(source=im1, save=True) # 保存绘制的图像
print(results)
display(Image.open('runs/detect/predict/image0.jpg'))우리는 경계 상자와 레이블에 대한 예측을 다음과 같이 얻습니다.
[Ultralytics YOLO <class 'ultralytics.yolo.engine.results.Boxes'> masks
type: <class 'torch.Tensor'>
shape: torch.Size([6, 6])
dtype: torch.float32
+ tensor([[3.42000e+02, 2.00000e+01, 6.17000e+02, 8.38000e+02, 5.46525e-01, 1.00000e+00],
[1.18900e+03, 5.44000e+02, 1.32000e+03, 8.72000e+02, 5.41202e-01, 1.00000e+00],
[6.84000e+02, 2.70000e+01, 1.04400e+03, 8.55000e+02, 5.14879e-01, 0.00000e+00],
[3.59000e+02, 2.20000e+01, 6.16000e+02, 8.35000e+02, 4.31905e-01, 0.00000e+00],
[7.16000e+02, 2.90000e+01, 1.04400e+03, 8.58000e+02, 2.85891e-01, 1.00000e+00],
[3.88000e+02, 1.90000e+01, 6.06000e+02, 6.58000e+02, 2.53705e-01, 0.00000e+00]], device='cuda:0')]다음 예와 같이 이미지에 적용합니다.

보시다시피, 우리의 경량 훈련된 모델은 한 코너를 제외하고 경기장에 있는 선수와 경기장에 있는 선수, 그리고 사이드라인에 있는 선수와 관중을 식별할 수 있음을 보여줍니다. 더 많은 훈련이 확실히 필요하지만, 모델이 작업에 대한 이해력을 매우 빠르게 습득하는 것은 쉽게 알 수 있습니다.
모델 학습에 만족하면 원하는 형식으로 모델을 내보낼 수 있습니다. 이 경우에는 ONNX 버전을 내보낼 것입니다.
success = model.export(format="onnx") # 将模型导出为 ONNX 格式요약하다
이 튜토리얼에서는 Ultralytics의 강력한 신규 모델인 YOLOv8의 새로운 기능을 살펴보고, YOLOv5와 비교한 아키텍처 변경 사항을 자세히 살펴보고, Ballhandler 데이터세트에서 새로운 모델의 Python API 기능을 테스트했습니다. 우리는 이것이 YOLO 객체 감지 모델의 미세 조정 과정을 단순화하는 데 있어서 상당한 진전을 나타낸다는 것을 보여줄 수 있었고, 이 모델이 NBA 경기에서 경기 내 사진을 사용하여 볼 소유권을 구별할 수 있는 능력을 입증했습니다.