ViT-CoMer: 밀도 높은 예측을 위한 컨볼루션 다중 스케일 특징 상호작용을 갖춘 비전 트랜스포머
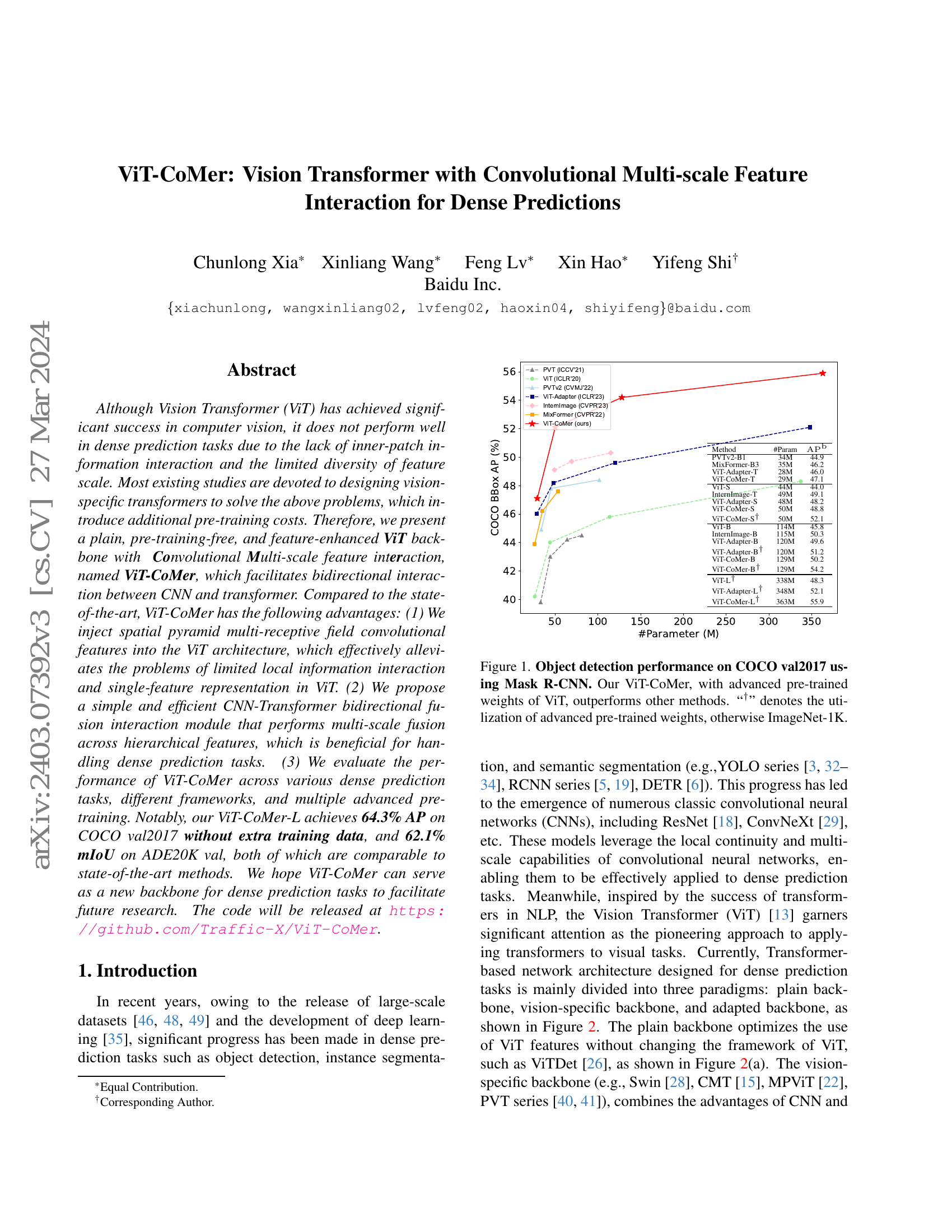
비전 트랜스포머(Vision Transformer, ViT)는 컴퓨터 비전 분야에서 큰 성공을 거두었지만, 패치 내부 정보 상호작용의 부족과 특징 스케일의 제한적인 다양성으로 인해 밀도 높은 예측 작업에서는 성능이 부족한 문제가 있다. 기존 대부분의 연구는 위의 문제를 해결하기 위해 시각 특화 트랜스포머를 설계하는 데 집중해 왔으며, 이는 추가적인 사전 학습 비용을 수반한다. 따라서 우리는 사전 학습이 필요 없고 특징을 강화한 단순한 ViT 백본을 제안한다. 이 백본은 컨볼루션 기반의 다중 스케일 특징 상호작용(Convolutional Multi-scale feature interaction)을 포함하며, 이를 ViT-CoMer이라 명명한다. ViT-CoMer은 CNN과 트랜스포머 간의 양방향 상호작용을 촉진한다. 최신 기술 대비 ViT-CoMer은 다음과 같은 장점이 있다: (1) 공간 피라미드 다중 수용 영역 컨볼루션 특징을 ViT 아키텍처에 통합함으로써, ViT의 국소 정보 상호작용 제한과 단일 특징 표현 문제를 효과적으로 완화한다. (2) 계층적 특징 간 다중 스케일 융합을 수행하는 간단하고 효율적인 CNN-Transformer 양방향 융합 상호작용 모듈을 제안한다. 이는 밀도 높은 예측 작업 처리에 유리하다. (3) ViT-CoMer의 성능을 다양한 밀도 높은 예측 작업, 다양한 아키텍처 프레임워크 및 여러 최첨단 사전 학습 방식에서 평가하였다. 특히, 추가 학습 데이터 없이 COCO val2017에서 ViT-CoMer-L이 64.3%의 AP를 달성하였으며, ADE20K val에서 62.1%의 mIoU를 기록하여 최신 기술과 비교해도 유사한 성능을 보였다. 우리는 ViT-CoMer이 향후 연구를 촉진하기 위해 밀도 높은 예측 작업을 위한 새로운 백본으로 활용되기를 기대한다. 코드는 https://github.com/Traffic-X/ViT-CoMer에서 공개될 예정이다.