Command Palette
Search for a command to run...
초록
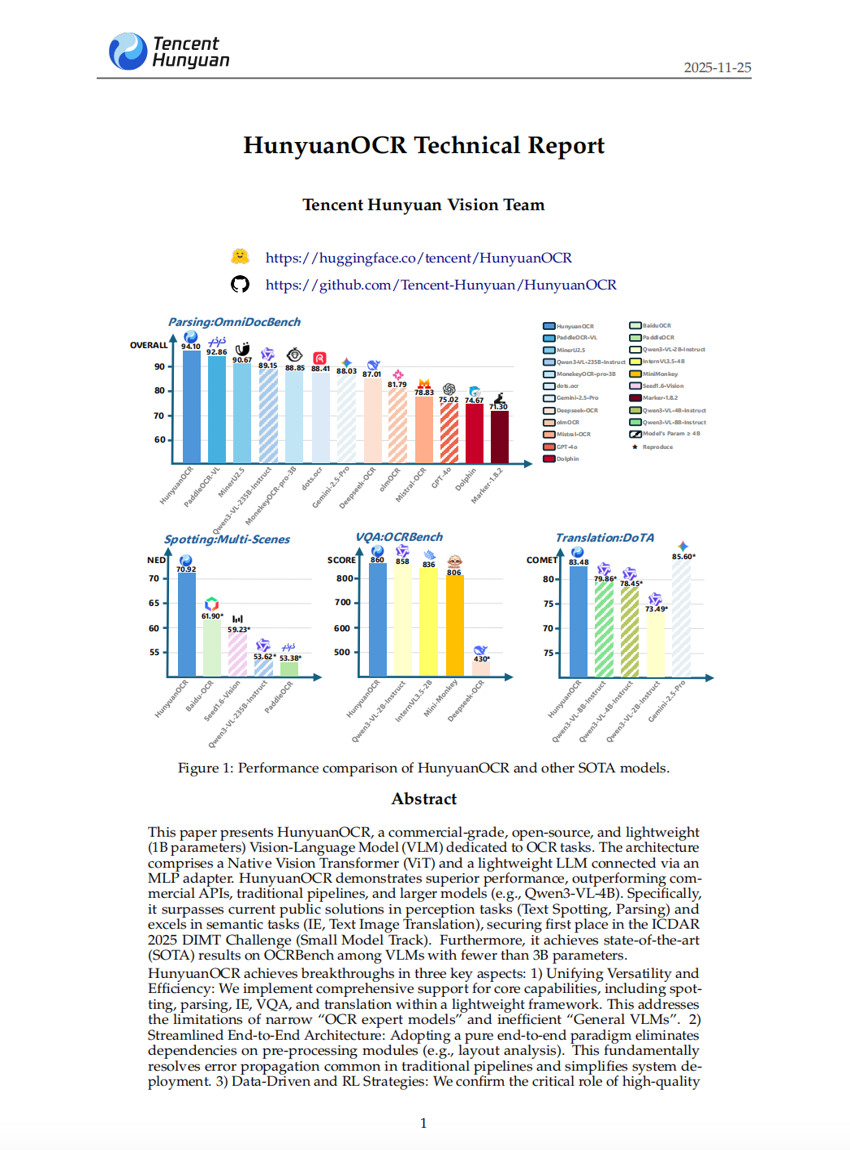
이 논문은 OCR 작업에 특화된 상용 수준의 오픈소스 경량(Vision-Language Model, VLM) 모델인 HunyuanOCR를 제안한다. HunyuanOCR는 1B 파라미터 규모를 갖춘 네이티브 비전 트랜스포머(ViT)와 경량 LLM을 MLP 어댑터를 통해 연결한 아키텍처로 구성되어 있으며, 뛰어난 성능을 보이며 상용 API, 전통적인 파이프라인, 더 큰 규모의 모델(예: Qwen3-VL-4B)을 능가한다. 특히, 텍스트 스포팅(Text Spotting) 및 파싱(Parsing)과 같은 인지 작업에서 현재 공개된 솔루션을 넘어서고, 정보 추출(IE), 텍스트 이미지 번역(Text Image Translation)과 같은 의미론적 작업에서도 뛰어난 성능을 발휘하여 ICDAR 2025 DIMT 챌린지(소형 모델 트랙)에서 1위를 차지했다. 또한, 파라미터 수가 3B 미만인 VLM 중에서 OCRBench에서 최신 기준(SOTA) 성능을 달성하였다.HunyuanOCR는 세 가지 핵심 분야에서 획기적인 성과를 이루었다.1) 다용도성과 효율성의 통합: 경량 프레임워크 내에서 텍스트 스포팅, 파싱, 정보 추출(IE), VQA, 번역 등 핵심 기능을 포괄적으로 지원함으로써, 좁은 범위의 ‘OCR 전문 모델’이나 효율성이 낮은 ‘일반 VLM’의 한계를 극복하였다.2) 단순화된 엔드투엔드 아키텍처: 순수한 엔드투엔드 패러다임을 채택함으로써 레이아웃 분석 등의 전처리 모듈에 대한 의존성을 제거하였다. 이는 전통적인 파이프라인에서 흔히 발생하는 오류 전파 문제를 근본적으로 해결하며, 시스템 배포를 간소화한다.3) 데이터 중심 및 강화학습(RL) 전략: 고품질 데이터의 결정적 역할을 입증하였으며, 산업계에서 처음으로 강화학습(RL) 전략이 OCR 작업에서 의미 있는 성능 향상을 가져옴을 실험적으로 확인하였다.HunyuanOCR는 공식적으로 HuggingFace에서 오픈소스화되었으며, vLLM 기반의 고성능 배포 솔루션도 제공되어 실제 운영 효율성 측면에서 최상위 수준에 위치하고 있다. 본 모델이 선도적인 연구 발전을 촉진하고 산업 응용을 위한 견고한 기반을 제공하기를 기대한다.